
软件工程师罗小东,多年平台架构和落地经验,大模型的出现让通用型AI成为一种可能,针对数字化和平台化的结合一直在考虑整合点,让超级自动化方面落地更成为可能。
注意这里假设部分材料可以公开,数据隐私性不强的情况下的设计运用,比如规范
概念
相关数字中台概念,可以参考我为什么觉得数字中台是团队的新型基础设施,这里不做过多阐述。
背景
整个研究的目标点是为了针对于数字中台层级的超级自动化,这个是在继Ops架构体系之后的一个突破点,前两年在Ops架构突发和成熟,比如DevOps/GitOps/DataOps/AIOps等体系(这里不涉及AIOps架构),在某个方面已经具备一定的自动能力,进而发展出数字中台的基础设施能力。
研究超级自动化的时间应该是在20年左右,前期在Ops上已经实践多年,一直想找更优的突破点,而且Ops模型体系也已经有了标准和完善,不管在微服务、中台技术、运维、数据治理上,这些都已经集成了自动化和流水线的能力,开源的产品也比较多,但是在超级自动化和数字中台整合方面上,目前市场和概念的意识还不够成熟。前期也研究过一段时间AI能力融入,但是多方面的限制,始终无法得到比较好的效果,而大模型(GPT)的出现,貌似把这超级自动化都变成了可能。
这里主要以落地结合实际为参考,基于数字中台基础设施上的进一步架构设计,从能力提升过程为维度进行阐述:
- 微服务和DevOps架构能力提升
- 数据治理能力的能力提升
- 服务治理和运维架构能力的提升
结合起来的建设的思路依然是大平台、轻中台、小前台,整合思路设计思路如下:
- 建立完整的规范文档,自定义大量的prompt前置库
- PromptOps(参考Ops)流水线体系的建设
- 结合数字中台多产品线的融入和落地
这里的大平台进一步的下沉和强化新型基础设施的概念和能力,更为突出层级的划分和固化,这个是以GPT模型为能力设计,整体设计是基于有完善的数字中台基础设施的能力上进行,这里主要给出参考,这里只是针对问题和解决问题思路来进行说明,也是后期落地和建设的方面,经验不一,我有我思。
过程问题
这也是结合使用过程发现的一个特别大的问题点,规范化和完善基础设施是条件之一,而利用GPT的结合推荐,Prompt生成的整合,也是基于这个规范和基础设计为主,而更好的结合实际,而不是仅仅参考,更多的是运用,这个主要会更利于人员的成长和往更高一层的思考,将人的精力和学习能力更加的提升,这对于很多中小团队来说是致命的成本硬伤,以下是AIGC和数字中台结合的整体架构:
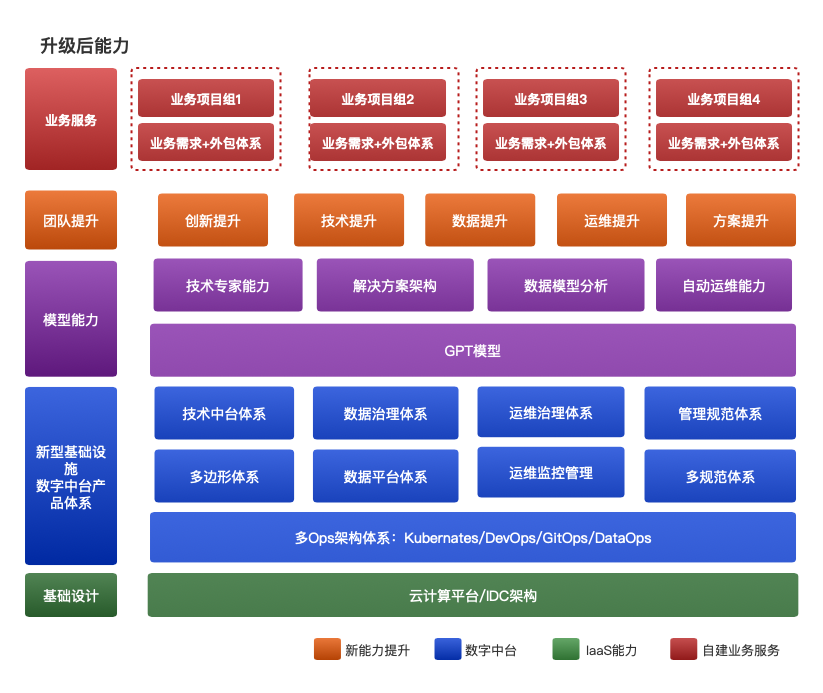
目前主要设计到的超级自动化上构建专家体系、自动化体系等。
微服务和DevOps架构能力提升
有工具和会用是另一回事,在成熟的前提上更进一步提升
这个可能是一个老生的话题,在过去的实践中还有目前行业的发展中,这个是工程结构的基础,也是面对于解决系统和架构问题的进一步架构提升,在业务和各个组件能力上,规范上,还有基础技术上的统一化和规范化等。解决这部分的能力,主要是在于后期服务治理能力、业务工程结构能力、还有自定义业务创新(或者说自研)业务上提供一定的保障。
前期在这块上体现可提升或者进一步需要优化的部分,过程遇到的体现在几个方面:
- 工程结构的规范、编码能力、基础编码优化等,比如针对于几百个规范和文档编写;
- 技术债成本高,涉及过多的概述和技术,比如往往需要多方面人才的指导才可以完整走下;
- 多组件沟通困难,针对于大量的组件和技术整合架构不够明确,比如场景无法更好的结合组件做架构
- 结合解决方案困难,无法针对现有的能力,更好的组合出更好的解决方案,比如往往会出现很多轮子
- 技术问题解决思路,这个成本较高,比如一般初中级工程师无法提出针对性的技术思路
- 产品和市场信息产生偏差,无法形成合力,比如你做你的方案,我找我找方案
- ……
针对于以上种种,可能临时可以解决或者”总会找到人”,但是这个如果项目PM在工时和项目经验上,做过精打细算经验的会发现,会有一种温水煮青蛙的感觉,无形中流失很多时间和问题在非业务功能需求上,虽然说在前期的基础架构上这些问题好像已经有规划和处理,但是在很多时候,自己一直得不到满意的效果(即使管理流程和组织架构上做优化),还是感觉这一步是可以进一步优化。
主要是构建专家体系、文档体系、规范体系、学习体系,而原来的组织结构会进一步调整和优化,从而更专注于业务场景需求和创新方面,培养业务专家体系(当然业务专家也可以结合,这里不做阐述),集中精力在更具备价值的地方,在多个方面更好的实现业务能力和创新。
数据治理能力的能力提升
数据分析和挖掘会更一步精简化,更专注于数据运营效果
在应用采集的数据挖掘能力上,GPT基本上比较容易整合,对于数据多层级的划分,如ODS/DWD/APS等这些在前期使用过程中,基本上针对于系统会针对性的出一版本,这部分的处理一些方案和方向上已经达到,这里不做过多的阐述,得益于SQL规范上,指定一定的指标分析过程,只需要更好的结构好模型,做出模型投喂等,出来的指标一般来极具参数性的,这类型的可以参考Chat2DB,PhotoShop等,这部分的数据分析可能正向推、或者反向推都可以。
前期在这块上体现的一些问题点:
- 数据维度分析、指标分析,这块上需要较长的周期,无法快速给出参考,需要投入特定人员,比如一些初级的分析
- 数据计算上SQL编写,无法和现有模型较好的整合,有一定的技术复杂度,比如kafka/flink/hive/clickhouse等
- 人员培训成本上,技术和数据概述有差异,过程需要特定的数据人员指导全程指导
- 技术债成本高,涉及过多的概述和技术,业务、技术和数据的结合沟通成本上较高,比如数据总线概念和消息概念不一样,但是技术操作上可能是一样;
- ……
另一个是在数据生成API上,也一样针对于第一章节提到的规范可以进一步推出。比如一个简单的实时例子,在维度分析和指标分析上,会结合模型自动生成,同时另一个是也会输出FlinkSQL,这个往数据开发工具上复制和调试即可(目前是这么处理)。
主要是构建专家体系、文档体系、规范体系、学习体系,从而更专注于数据挖掘场景需求和创新方面,在多个方面更好的实现业务能力和创新。
另一个是数据分级、元数据、主数据的分析的抽取上,数据清洗、元数据管理、数据模型管理等流程化的工作,这些都有比较好的能力整合,结合模型训练基本上会更合适(如基础的数据模型算法)。
注意数据涉密的问题,这里只做模型提交处理,而且需要客户沟通
新一代的AI技术,让此类工作门槛大幅降低,数据分析不再成为一个难点,针对一般型的项目基本上是可以直接套过来,通过自然语言快速建表,包括自动生成维度表、建立范式模型和星型模型、自动分析表之间的逻辑关系、甚至提供建模建议,生成一定的SQL和脚本,更快的进行数据采集分析。
服务治理和运维架构能力的提升
自动运维能力的提升,更快速提供服务运维质量和范围
这里的运维包括监控、管理、安全、自动化等,自己一直在研究和运用的更多的是ChatOPS,以钉钉一类为代表的工具,一个是信息的交互,另一个是主动推送信息,这部分在某种模型上,会比较成熟,不过在运用上还是比较不得意,大部分是集成中通知和互相上,集成起来的能力点是极度有限的,是在现有的工具模型上做的API,然后结合各个服务能力进行一个窗口型的交互。
出于几方面的处理,很多方面是webhook/定时/api几个方面的能力结合,而这些操作过于通用而带来一定的限制,主要在几个方面:
- webhook能力有限,需要定制很多api来结合,机器人的结合,缺少推理的能力,在这块上学习成本和场景上依然会有很大的限制
- 技术债成本高,涉及过多的概述和技术,业务、技术和数据的结合沟通成本上较高,学习成本很高;
- 技术问题解决思路,这个成本较高,比如一般初中级工程师有些可能根本无法接过自动化运维这个内容
- 运维和数据挖掘的结合目前缺少一定的方案,技术方案突破存在一定的瓶颈,需要研究的成本很大
- 问题解决过程需要关联大量的基础设施信息,这个结合的成本需要特别熟悉的工程师才可以处理
- 问题分析模型创建困难,在海量的运维数据中,需要高级算法工程师和计算人员才可以,中小团队招人成本极高
- 运维/技术/数据整合起来困难,无法形成一体化的结合的能力,形成运维/技术/数据各个层级孤岛
- 相关过程问题沉淀效果不理想,重复问题参考效果未必能达到预期
- ……
前期一直有计划结合AI能力来处理这个,需要突破很多限制和成本,这对于中小团队来说,不管是精力还是人才,基本上会有很难的实现,特别是需要特别资深的工程师,而且甚至有可能做到半效果不理解,然后走到黑或者走到放弃的层面。
同样是构建专家体系、文档体系、规范体系、客服体系,在处理上更专注于稳定性和健壮性,提升问题预知和安全感知能力,促进业务的稳定性。确保系统、设备、应用程序等IT资源运转正常,并维护它们的高可用性和可靠性。运维人员通过对软件、硬件、网络等的监控、维护、检修、升级等工作来保证系统的稳定性和完整性。
整合思路
这里能这么做的主要利益于数字中台的规范性和完整的基础设施能力提供,稳定和成熟的中台体系。这个是针对原有的平台化的升级优化,而不是重构或者重建之类的,这个过程是没有必要的,应该来说以适当当前的任务平台或者业务系统。
建立完整的规范文档,自定义大量的prompt前置库
建立专属的Prompt库,指令会有一定的字符限制
根据自己在接触的平台的这几年,有一些经验和材料的沉淀,不管是文档和脚本库等,都有上千份,进行进一步的梳理和建立更好的资料库,服务系统之前标准API的提取和标准的定义,更加明确多个节点的标准规范,比如接口规范、日志规范、数据规范等,形成大量的知识库,而这些标准知识库,形成Prompt的前置库,为了形成更好的指令传递给GPT模型。从而结合实际的微服务技术、中台技术等。
- 增加了模型能力的引入和团队能力提升的章节(可以理解成高级助手)
- 通过多个资料和材料的整合,形成多个专家体系,比如Java技术专家,数据分析专家,运维专家,数据库专家,产品专家等;
- 通过资料和规范,结合AI的推理能力,会更加结合形成结果,形成客服体系,进而形成人员成长体系,解决人员的问题;
- 通过专家体系的融合,形成方案解决方案设计能力,针对场景和项目的不同,结合和搭配出不同的场景技术方案,提供更好的参考。
而整个过程需要达到的目标依然是大平台,沉淀形成新型基础设施,将人力和精力更加的集成在更有价值的地方。这个阶段的整合,更多是针对于文档规范和调整,会有一定的调整,同时为了更好的区分和不影响当前业务,分离出GPT版本,进行小规模的试行和验证,推进。
PromptOps(参考Ops)流水线体系的建设
建立更新机制和流程
这个主要得益于在DevOps/GitOps上的成熟和规范,效果等,在以前的经验中,这两块基本上达到了较高的自动化能力。
为了平台化更好的优化和更新,需要不断的吸取新的知识和参考,同时获取到更好的项目参考,比如包括同类竞品项目,开源项目等,这个是一部分的集成能力,另一部分是本身Prompt库的升级,更新等,这里主要是参考DevOps的思路,形成流水线和自动化的能力,建立多个输入端,形成类似于人工智能标注一样的处理流程。
- 在原来的沉淀结构上提一步的提升和规范,提升了每个章节内容的建设范围和边界。
- 根据层级数据安全,做好一定的敏感词定义和过滤,形成Prompt安全规范,避免敏感信息和层级数据外漏
- 根据结果和返回数据进一步沉淀到数据平台,过程进一步的进行优化和维护
这个过程的主要目标是形成流水线,减少在Prompt上的投入的运维管理。
结合数字中台多产品线的融入和落地
这是一个落地的问题
这里主要利益于产品的自研能力,为什么一直坚持自研也是这个考虑,这样更好的创新和能力的整合。
在这里同样的思路,如果一个事情过于复杂,需要想办法让它变得更简单。在这块上搜索和输入的Prompt内容,结合上面的专家体系和规范体系,结合产品工程中的特定卡点进行嵌入,最终直接输出结果。这个方式类似于Prometheus/ELK等,直接嵌入到每个工程运行的卡点里面,直接点击即可查看结果,或者输入少量的提示词即可直观的看到。
- 通过找到每个产品服务的卡点,进行GPT产品线的埋点,进行产品整合,以获取得到更好的反馈结果,这里主要以sdk埋点的形式
- 在工程师层面淡化AI的各种概念,形成无感切入,在后期中不断的沉淀和优化,以达到更好的效果,比如缺少某个关键词,通过上面的流水线进一步优化
这个过程主要的目标是落地运用,达到原目标的结果,这个在数据设计和规范编码上已经有一定的运用,效果还是不错的。
总结
对于数字中台的升级上,结合GPT和超级自动化作为新的突破点,提出了在数字中台基础设施上进一步提升能力的架构设计思路,并探讨了落地建设方面的问题和解决思路。经验因人而异,每个人都有自己的思考和理解。这个是下一步升级架构方案,当前还在进一步的优化和思考中,同时也在初步的结合中。以上为升级的方案,期望可以给他人一些参考,也期望有兴趣的朋友可以关注讨论。
鸣谢
这里主要参考了一些开源项目研究和得到的思路,这里做鸣谢:
- AutoGPT 为了目标实现而实现的能力
- 阿里云运维体系 运维体系和客服体系相当成熟
- Chat2DB 基于规范(SQL语法)基础实现的能力
- Kuboard 多产品和结合落地的能力体现