软件工程师罗小东,多年架构和平台设计经验,目前在研究平台与新技术结合中。
背景
内容针对的是社区产品建设新人切入的指导性思路,目标是打开自我思维,有基础,能设计,能思考,能实践,会自我价值体现。合理利用社会资源工具,将时间和精力放在最有价值的地方,创造价值,提升价值。
产品是以开源状态进行开发管理,当前社区团队在接纳新人,有部分还是大二大三学生,有一些可能没有接触过设计体系这块,考虑更系统的体现基础层,这里进行阐述说明。针对于新人来说需要一些方向的引导,以快速的进入状态,跟上梯度成员,便于他们有方向的成长和学习方向,也是规避迷茫,缺少方向感,导致负面和误导,消耗无谓的时间。

当前维护的社区团队非常小,还是兼职,自动化和低成本的基础设施对团队来说,会比较看重,应用最少的人力去维护好产品,同时为了更方便的办公。工具的使用,可以让新人和加强的技术理解、架构思维、使用场景、解决能力、还有方案输出等能力。
设施包含
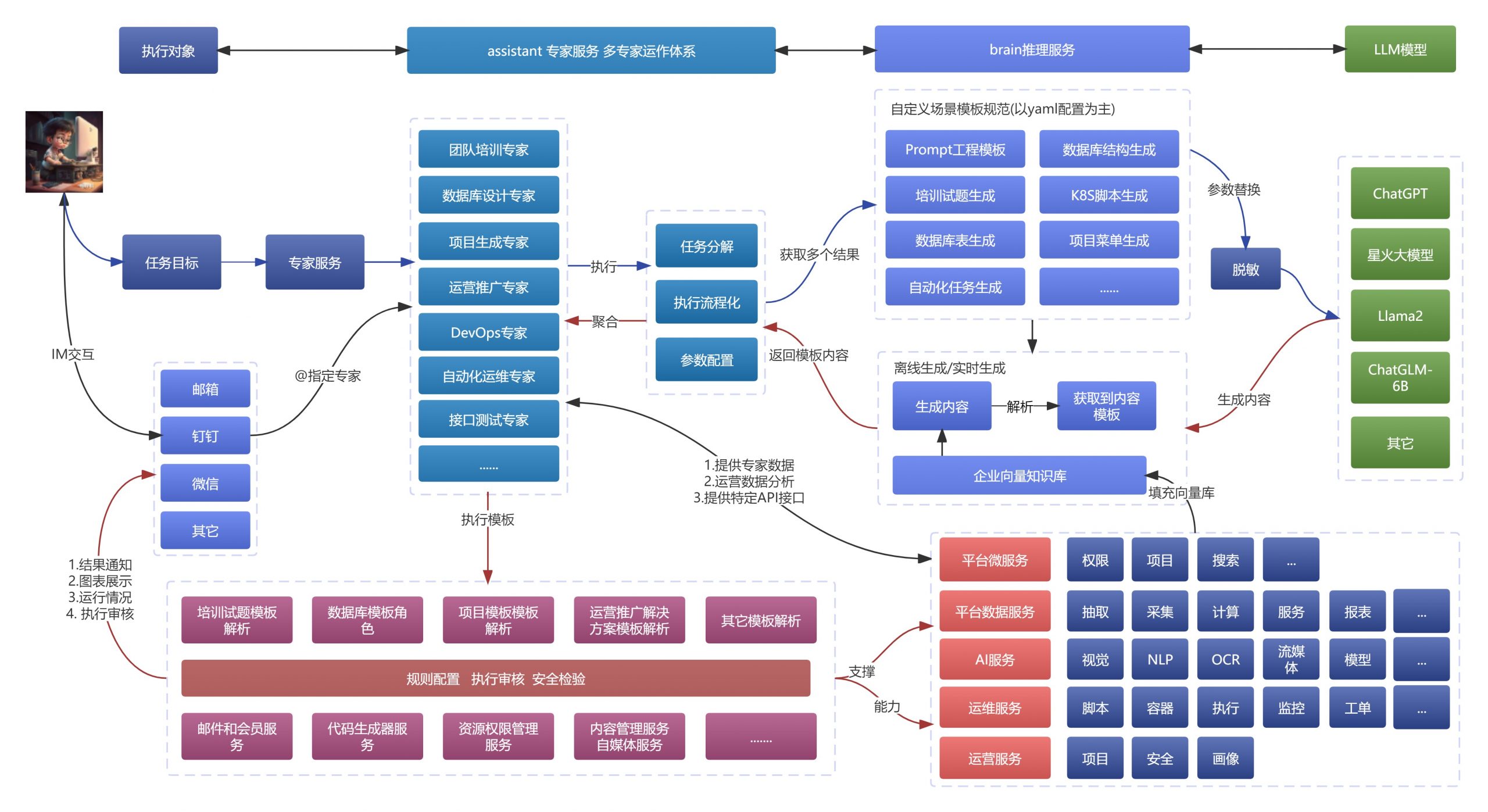
这里的基础设施工具,主要是使用开源和常用的SaaS化工具来进行平台产品研发的管理,以减少成本和学习路线,可以有大量的学习内容让团队可以快速解决问题,如下图中的这张架构内容。
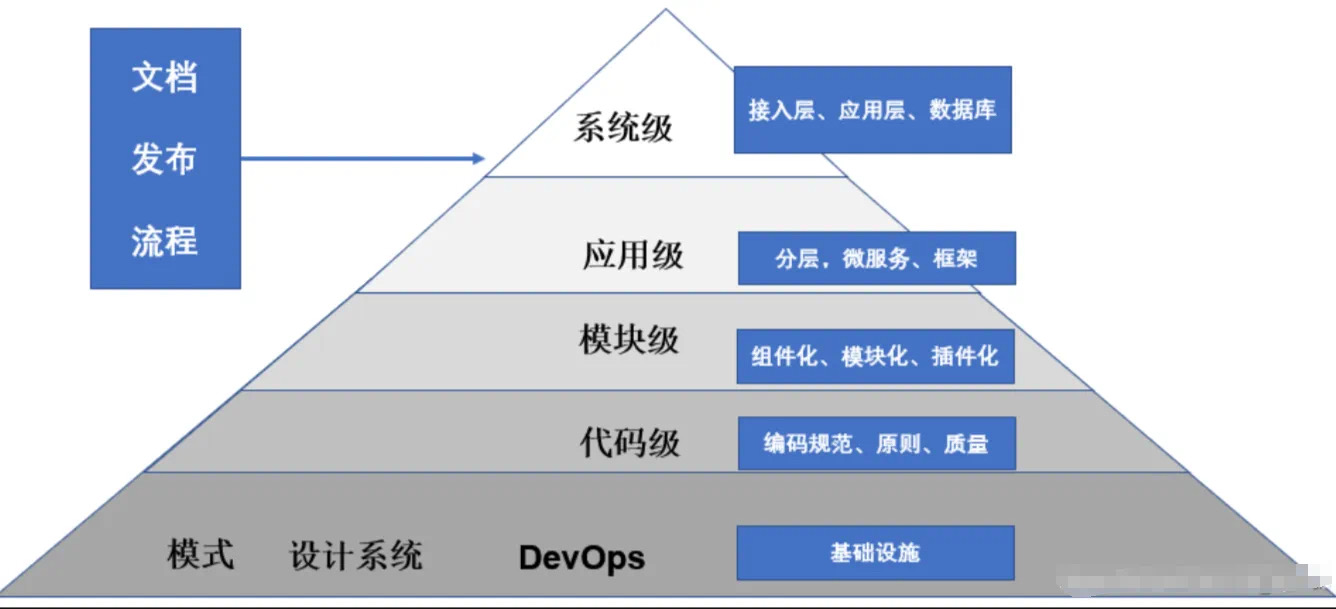
基础层主要是包括【基础设施、代码级、模块层、应用级】,这个主要是基础环境设施,上面系统级主要是软件服务应用。在基础层,基本上使用的都是免费工具类型,包括免费服务器,免费的DevOps套件、免费的代码检测、安全检测等。每个人都可以使用,开个账号就可以学习,可以使用一些效能工具更快的提高自己的效率。
有一部分是现成的,有另一部分的自己设计的,总的来说,类似于PaaS层,但是又高于PaaS层,最大化的贴近于应用层,以减少底层的建设,确定好规范之后,外加GPT的加持,会更加提高效率和输出服务能力。
这里主要的内容包括几个主要部分:
- 基础PaaS层:阿里云ECS服务器、Kubernetes、阿里云ECS网络安全、阿里域名
- DevOps套件:Github、GithubAction、阿里云效Maven私服、阿里云ACR镜像
- 中间件层:Redis、阿里云MySQL、七牛云存储、Clickhouse存储、Kafka消息、Nacos等
- 基础服务层:Infra核心包、Infra单点登陆、Infra代码生成器、Infra权限引擎、Infra网关服务等
- 质量管理层:SonarCloud、GithubSecurity、墨菲安全、ApiFox
- 自动化层:GithubAction、Ansible
- 项目管理层:阿里云效项目管理、阿里钉钉、WPS、腾讯会议
- 项目预警层:Prometheus、Ansible、阿里钉钉
- AI智能层:Hugging face、百度飞浆、阿里云AI系列
- 数据治理层:阿里云DataWorks、Infra数据治理套件
- LLM大模型层:ChatGPT、星火大模型、百川AI、Infra智能体服务
这些大部分社区工具和云服务平台,作为入门的基础内容,难度系数并不高,要求只是基础能接入使用就可以,另一部分是基础架构里面进行补充的内容(以Infra开头),这些都提供出对应的接口和使用说明文档。当中有一部分会混着用,比如数据治理层,后期做为平台型产品会做一些场景进行针对性替代的研发。
上面这些,在这进里统一规划层基础设施层,这些会考虑使用低成本的方式去运营管理,方便产品的正常开发和演示运营,同时确保可以新人更好的针对性的自我学习。
学习路线
在工具选定之后,针对新人来说,怎么接触练习,这个可能来说,先对比较简单一些,对于线上可以注册的工具,基本可以自己学习就可以,学习主要通过以下路线,先熟悉工具,在进行应用层服务的开发。
学习路线主要是下面:
- 了解开源工具:账号的注册和示例的学习,了解这个工具是做什么的。
- 了解服务能力:了解Infra组件提供的基础能力有哪些,怎么使用当前的服务模板。
- 熟悉研发流程:了解产品的项目管理流程,敏捷开发流程,知道从哪步到哪步。
- 创建服务能力:能根据需求自主创建出服务并提供出服务能力,价值体现。
学习工具主要是了解怎么使用,这里使用的层面就是自己注册跟学习了,然后自己关联自己的demo进行学习。这个过程看个人,不合适人员并不会要求往下,合适人员接触起来,其实也比较容易,大部分就是看教程或者视频操作。

这也是进入产品维护的一个简单门槛,基本工具使用的还是helloworld级别,深入会过程再慢慢沉淀这样。在长期接触过程中,其实大部分场景都是可以满足,即使不满足,也不会达到多难的程度。
这里除了编码层面的,其他都是自动化,编写一套之后,留着自动任务执行就可以,根据预警情况,看是否需要处理,其他的,出问题再需要人工介入。
编码层面的,这里主要是通过结合代码生成器,GPT和定制的Prompt来进行,因为是产品型和服务型应用,逻辑还是先出一般本,先可以看到,然后后续根据产品功能,进一步的完善。先用起来为主,这部分对一般没怎么接触过的人员,先做一个功能就可以上手,因为规范都统一化,这些入门成本会比较低,参考着复制粘贴就可以。
另外就是Agent智能体服务的,这个整合起来就是调用GPT的接口外加基础服务的接口,当然,这个需要一些规范,前期已经解决了这个问题,目前主要是根据规范,结合工具API接口写Agent插件就可以,集成架构也已经集成。
能力输出
这部分重点还是在需求和设计上面,到进入服务输出来说,到这步已经很容易了,服务能力的输出,才是最贴近业务层的,这里会把精力放在这块上面,时间成本最大的,也是在这块上面。这部分可以花时间在需求和设计上面,后期通过AI编程和微调整来实现,另外就是参考其它网上代码或者开源项目。

自我能力提升,还有AI的引用也是在这块上,这块要考虑的编码,但是更多的期望可以使用现成的代码,可以复制或是开源的,符合的拿过来就可以,没有的,使用GPT协助建设也可以。这部分偏于码农路线,但是我们能做但是不代表一定需要做。
时间精力放在优化,某个框架深入,思维的理解,场景的运用,解决方案沟通上,这个是目前团队特别关注也是重视的。
总结
上面是当前产品研发过程中,使用的基础设施工具,有部分是使用现成的,有部分是结合开源项目进行的研发,有部分是自主开发,通过设计整合起来的基础设施能力,为上层服务建设提供良好的条件,也可以让新人更专注于场景解决方案和业务能力分析设计上面。
这里提出了一套基于开源工具和社区资源的学习和实践方法,强调了基础设施、代码级、模块层、应用级的基础知识,以及使用免费或低成本的工具和服务的重要性。并给出了一个学习路线,包括了解开源工具、了解服务能力、熟悉研发流程和创建服务能力等步骤。强调了能力输出的重要性,包括业务能力、AI引用、编码能力、优化能力、框架深入理解、思维理解和解决方案沟通等方面。