软件架构师罗小东,多年架构和平台产品设计经验,目前在Agent场景落地结合中。
背景
这里针对的是AI体验版的数据,因为要迁移数据库,刚好做了一个统计,临时记录,会偏向于口语化一些。
当前一直是AI平台体验版对外,更多是合作伙伴还有部分注册用户使用,前期一直专注于产品的开发,没有太多体验用户,在这一年里面积累下来的体验数据。这里拿了两个数据,一个是AI写方案的数据,一个是AI对话的,目前后台对话的次数是605987次,然后生成的AI文档数据是161122份。当然还有其它的场景,这里就不做统计。

因为前期更多是为了给有合作的伙伴、兴趣的朋友、用户体验进行体验,这个量确实有点超过我们的预期。
但总的来说,这个数据体验还比较少,但是对于AI平台来说,或者对我们团队来说,是一个阶段性的反馈,因为我们每次对话更多的是Agent对话,文档是多Agent来(多循环)处理的,可能数据级来说,应该还会更多出几个级别。

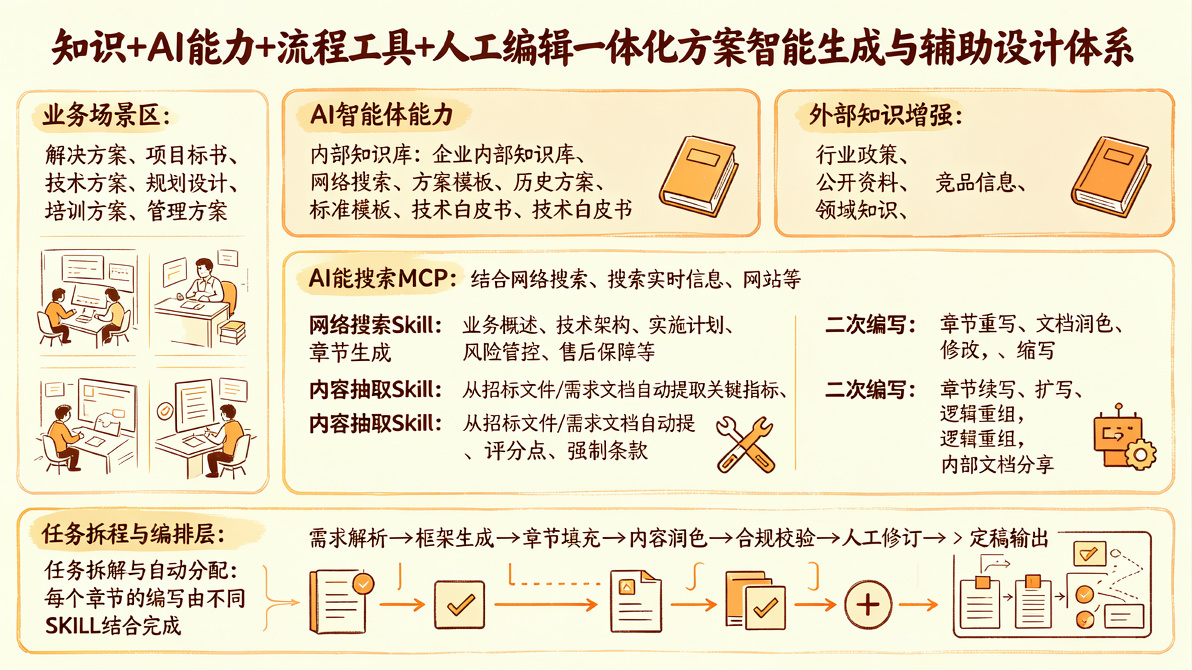
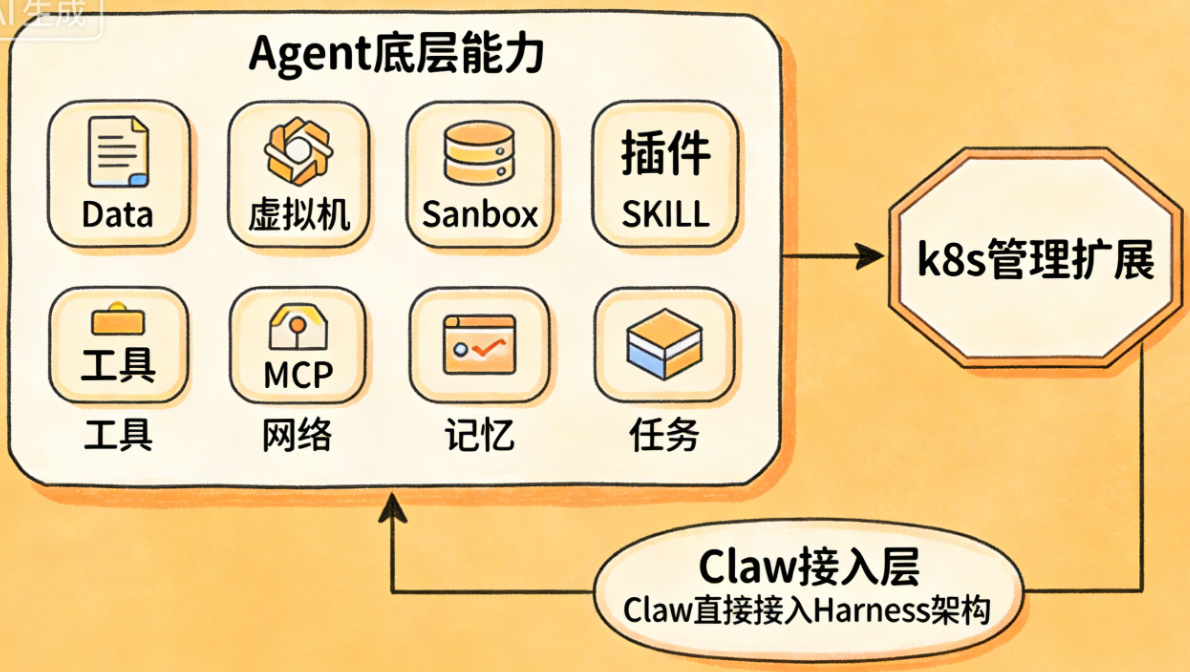
我们是自研的Agent平台,使用SpringBoot技术,底层框架(类似于langchain)也是我们自己搭建,包括前端。相对来说,可能会其它使用开源平台的有些不一样的(比如Dify),记录的经验大概有以下几个点:
- Agent前期稳定性及上下文
- 自定义全局Prompt及优化
- Agent的对话和工具优化
- 多Agent和后台任务的管理
你会发现这里很少讲Token费用的问题,主要是国内的Token成本比较低,另外就是AI文档的输出价值性较高(类似于你熬夜写方案还是AI写一份方案的对比)。这里的经验更多偏向于Agent平台过程问题及经验总结,每个架构师有自己的思路,我有我思。
过程记录
Agent并不是大模型,这里是 AI 工程化,并不是大模型的,类似于我们不做电厂,但是我们会用电来做特斯拉工厂,而Agent就是我们的 Model3 产品。
前期稳定性及性能问题
稳定性是我们最大的忌讳之一,不管是模型还是Agent,基本上你很难接受执行过程中出现断掉的,这好比看电影,可以接受画质模糊一些,但是不能接受一卡一卡的,特别是完全卡死的情况。
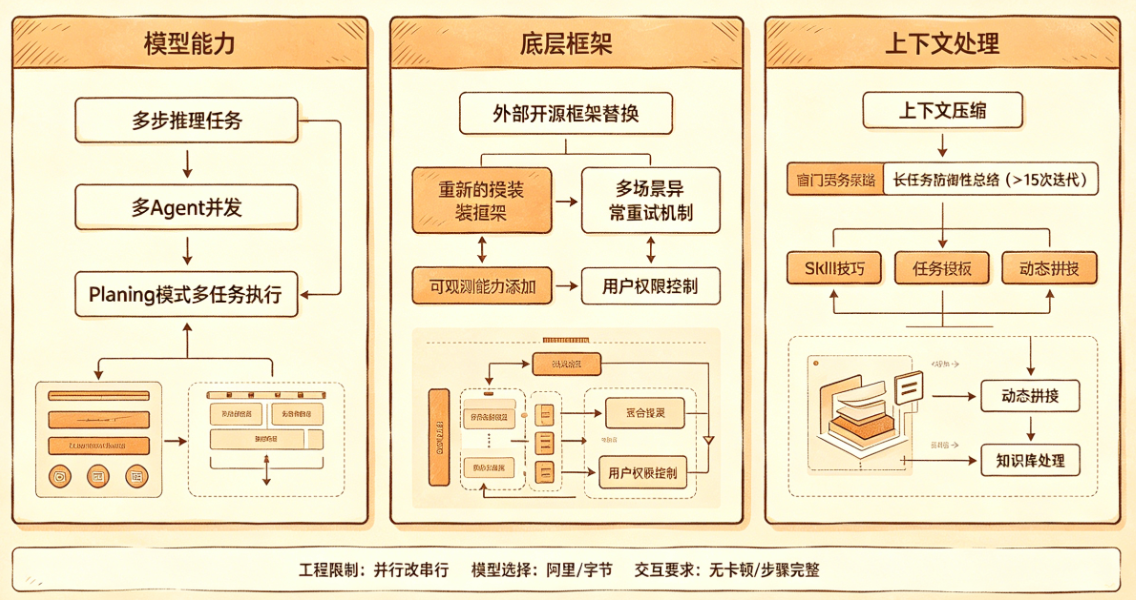
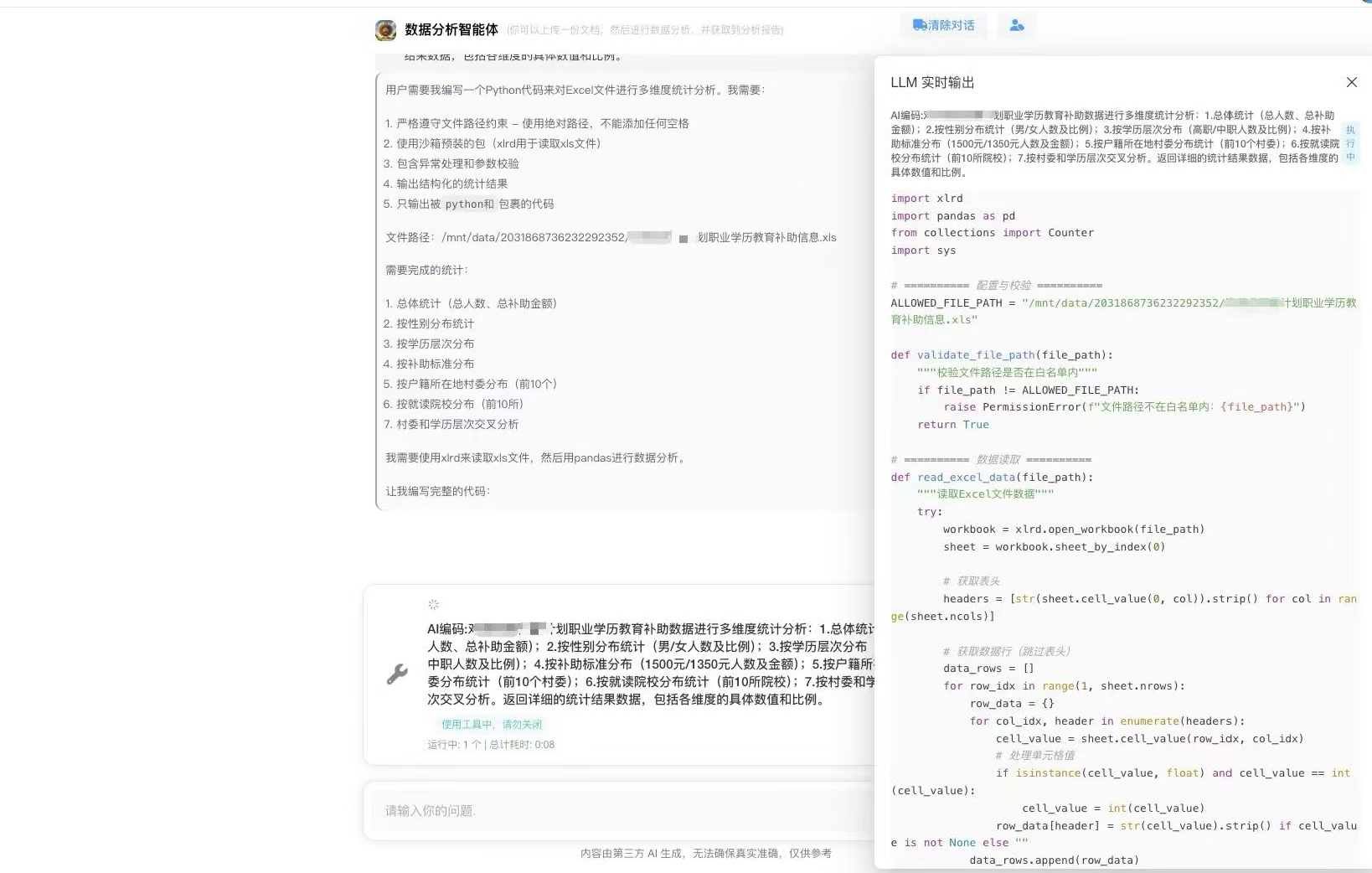
前期这个问题主要出现几个地方,一个是模型能力,另一个是底层框架,还有一个是上下文的处理。
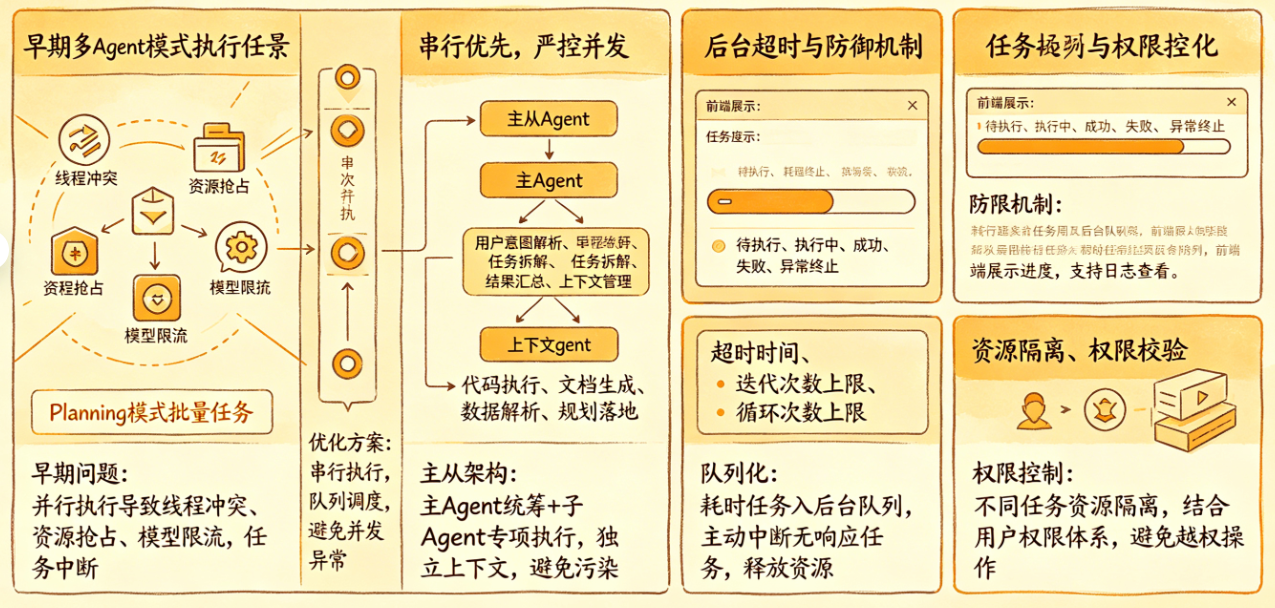
在Agent处理上,仅仅是简单的对话,这个可能相对来说会好一些,但是Agent的操作过程中多步的,有推理的,这个时候,就需要高级的模型能力,另外在多Agent的时候,还会存在并发的问题。比如Planing模式,规划出来了很多步骤,执行的时候几十个任务执行 …. 前期的稳定性问题,会造成是否可用的关键点。
在工程上做了限制,由并行改成成串行,避免了多线程并发问题,可以慢一些,因为有可能会同时执行十几个Agent,考虑到稳定性,将所有的都改成串行,要保障使用性上能稳定。
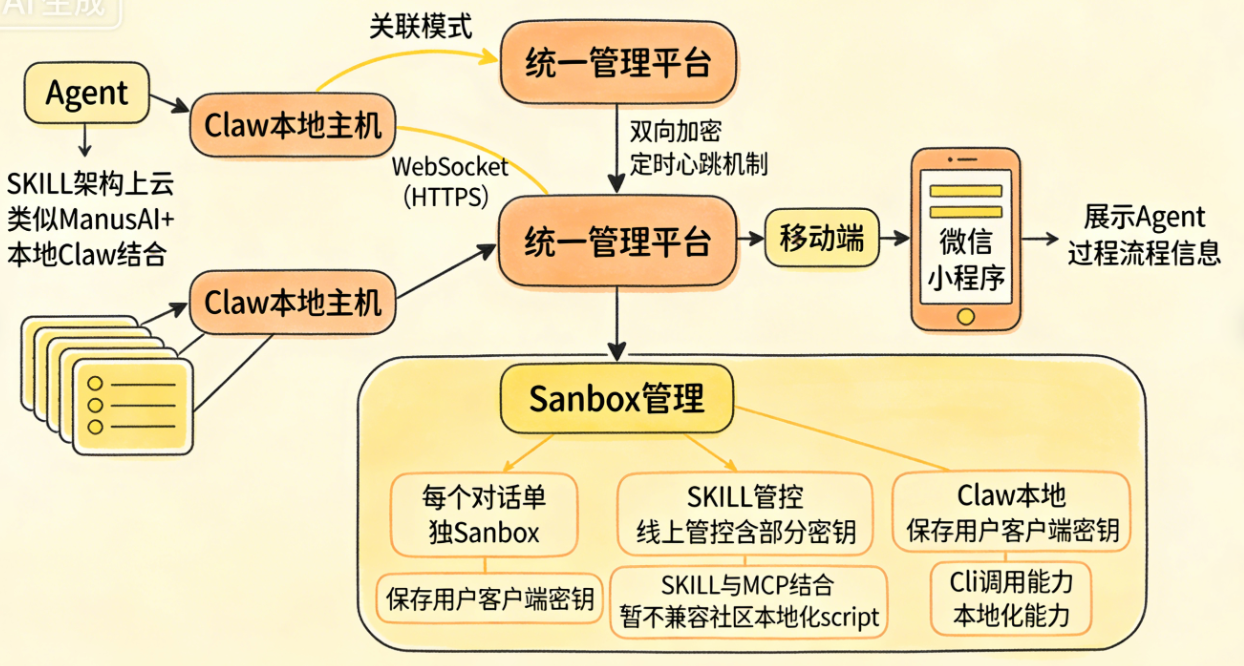
另外就是底层框架上不要使用外部的开源框架,重新封装,然后做好多个场景下的异常重试机制。这个前期的时候,也是考虑了很久,维护一个框架的成本并不低,但是后面的时候,优势就比较体现,比如可以随时加可观测能力,还有用户权限的控制等。
在模型的选择上,目前只考虑阿里或者字节两家,其它的基本上不考虑,在体验环境里面,印象里除了一两次敏感字眼出现异常以外,其它基本上都是比较稳定,至少没有反馈说无法使用的情况,还有后台报异常的时候,是模型的无响应或者限流等异常,有过,但是概率很低,基本不会出现。
再有一个是交互也是类似,如果卡住无响应,这也是很难以让人接受的,包括过程缺少步骤,看不出AI思考过程等,这个过程ManusAI效果就是很好。
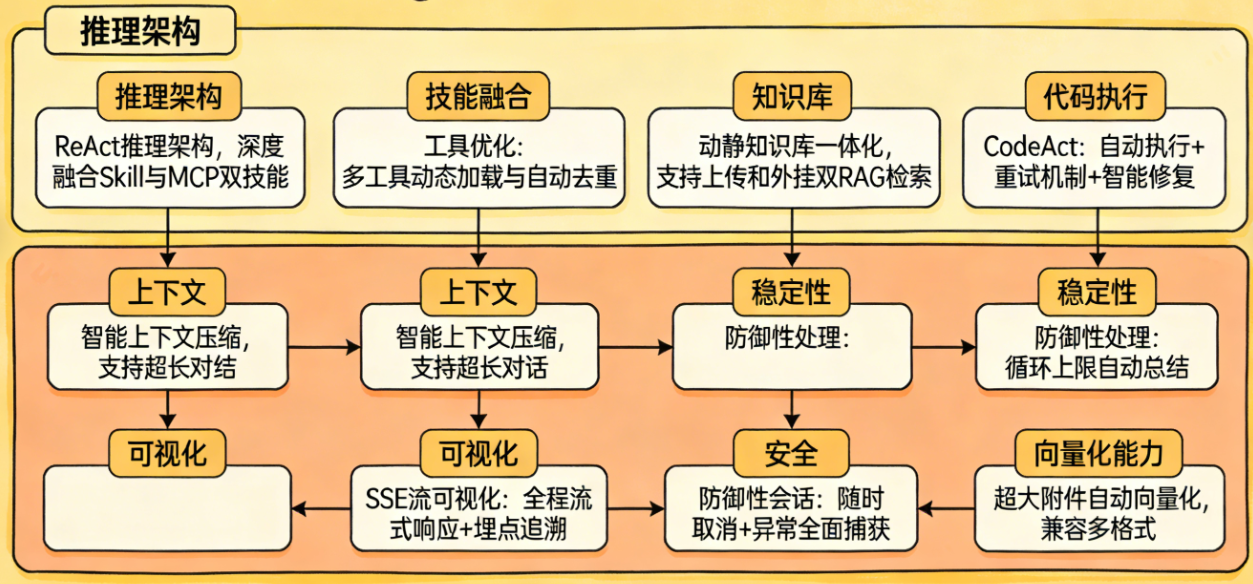
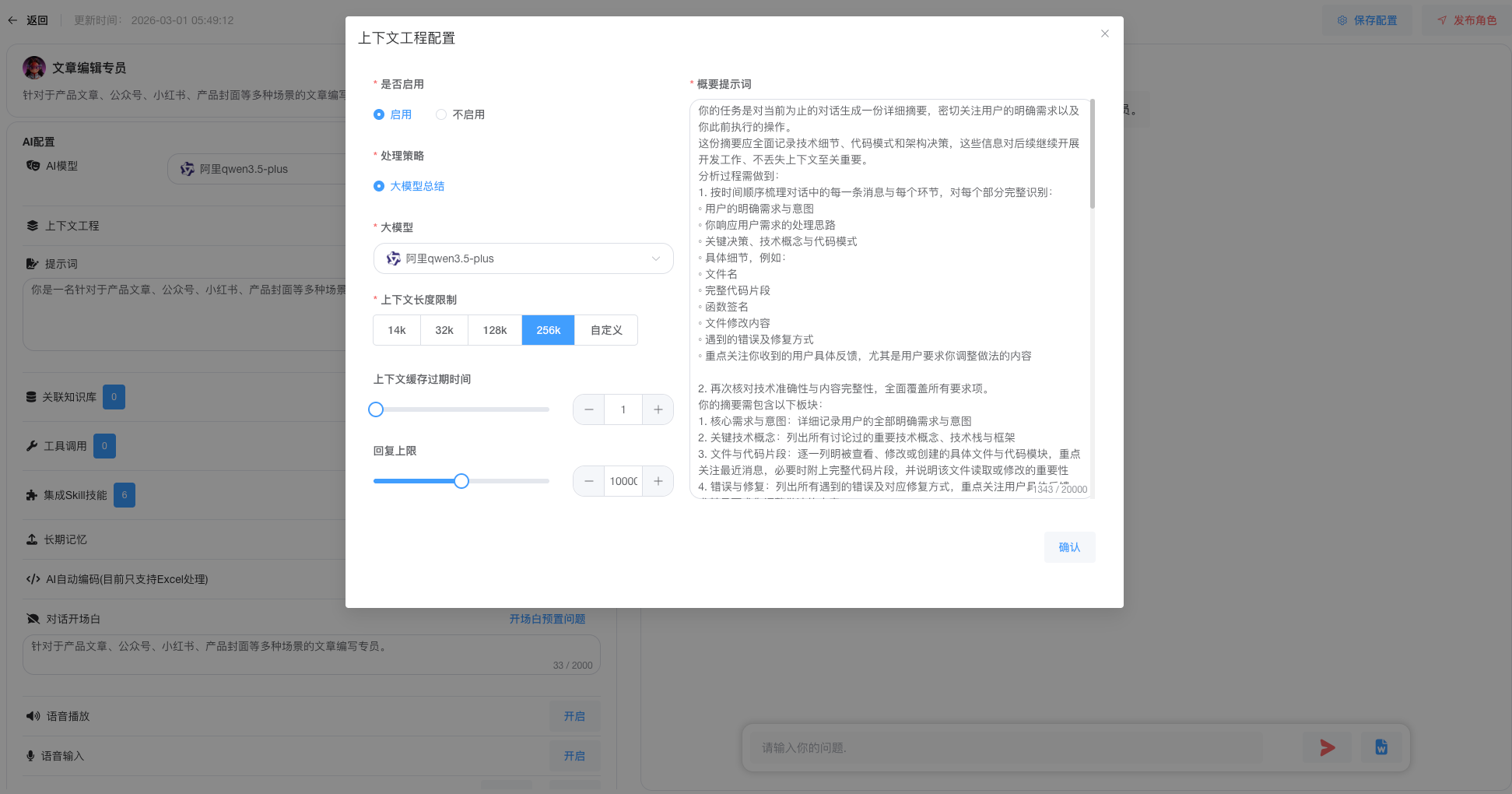
接下来就是上下文的技巧,这里主要是压缩,还有上下文窗口丢弃策略,目前的大模型上下文长度比较大,这里主要是聚焦和过程压缩,还有去掉多余历史记录。如果长任务使用规划再到执行,单个Agent对话每次不能超过15次迭代,超过的就做防御性总结。当然还有很多上下文技巧,比如Skill技巧,约定规则,任务模版,动态拼接、历史顺序,知识库处理,内置工具工具等,主要还是是稳定性为主。
自定义全局Prompt及优化
这个是主要的点,优化的内容很多。
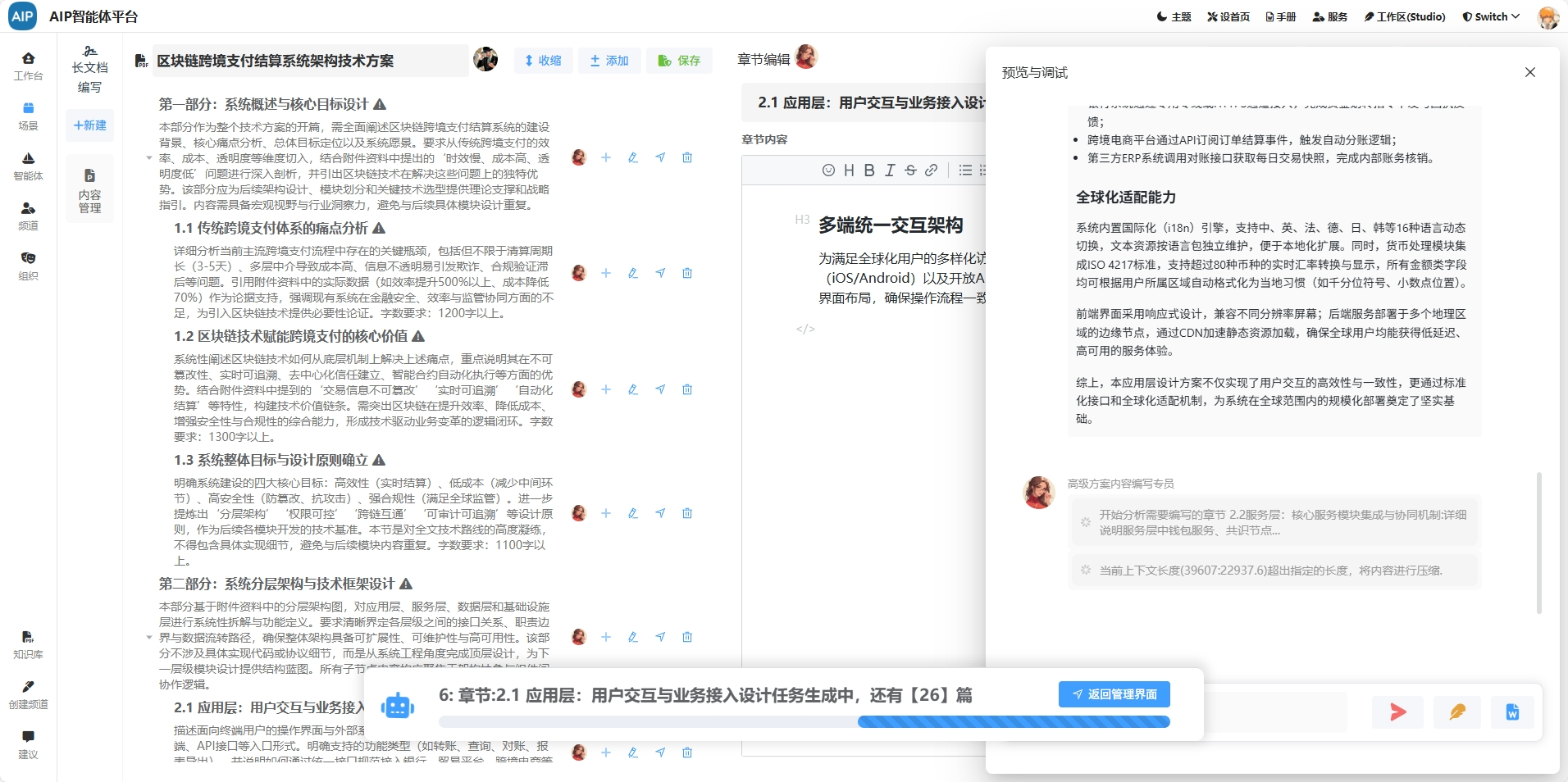
一个是约束和自定义底层框架。目前实现Agent的思路,前期主要是ReAct和CodeAct两个结合,后面再加上了部分System 2 ,这样从防御性原则上,该有执行能力上,通用能力做好约束,无论如何,就是不要让太多的Prompt和历史对话混乱在一起,如果任务点比较多的,就会分开执行不同的任务,比如CodeAct触发的时候,会跟主线的Agent分开,做好之后结果再返回给主Agent,后面很多思路都是这个。按场景加载,另外就是子任务(也可以理解成subagent)的上下文分开,不要污染主任务。
优化的部分,还有各个工具的优化包括Sandbox还有预装环境,包括Python还有docker,数据的预先解析,比如OCR,主要是能做到先做,合并起来,这个有好有坏,会消耗很多上下文,但是耐不住速度快还有稳定,就是能固定程序的就固定,还有提供出来。
这些就需要过程中调试好Prompt,基础的Prompt模版,前期看过其他开源项目的prompt,但是你会发现,不同的工具他们本身结合的工具,Prompt都是互相匹配的,比如CrawAI、LangGraph、GaminaCli等,也尝试过直接参考,但是调试下来,基本上都是千差万别的。
在这个过程中,定义好全局的Prompt模版、动态拼接过程优化也是消耗了不少时间。
Agent的对话和工具优化
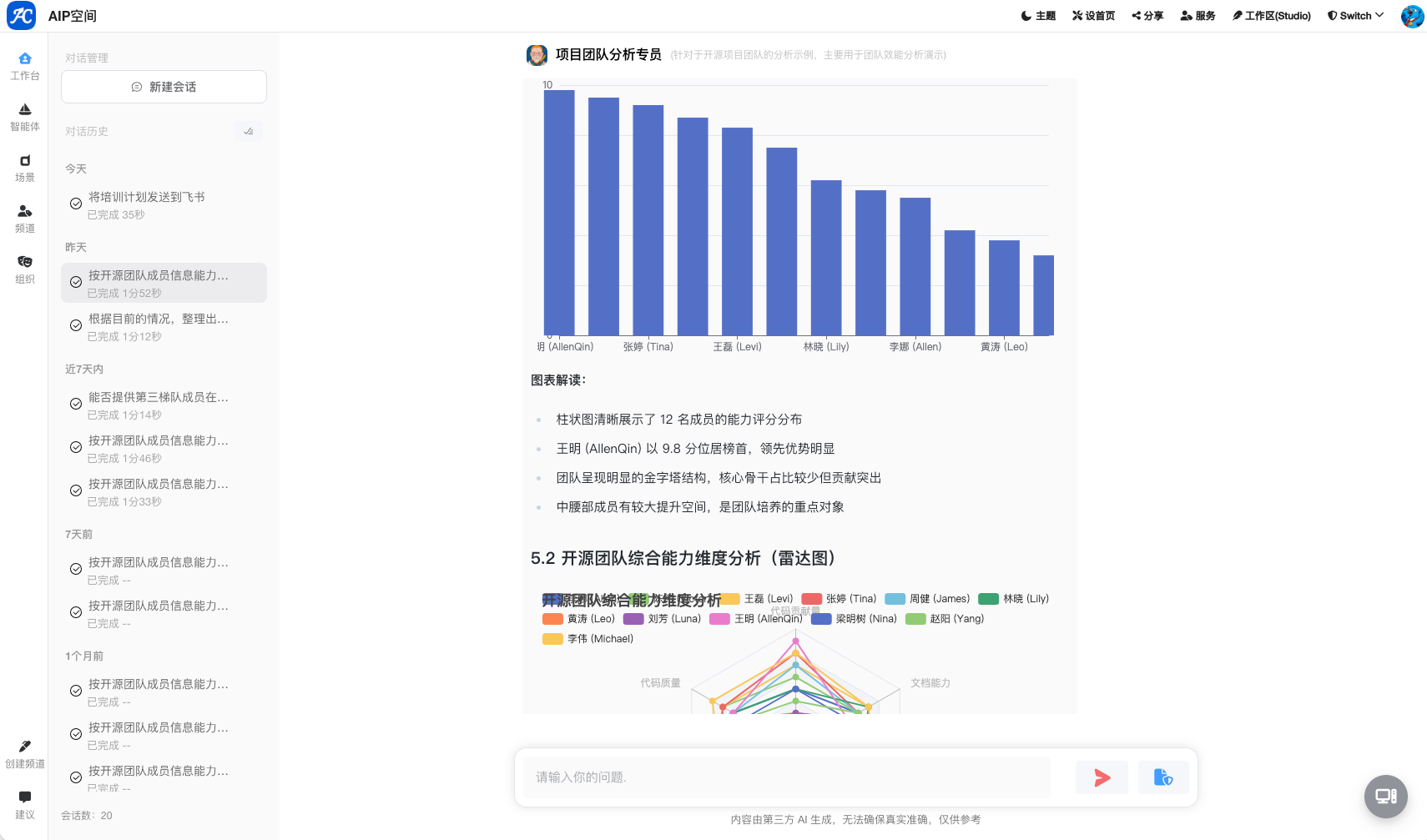
在自研Agent平台的实际体验版运行中,对话与工具的联动效果直接决定用户可用感,我们围绕思考可见性、执行流畅度、工具可靠性、对话可控性做了大量针对性优化,核心经验如下:
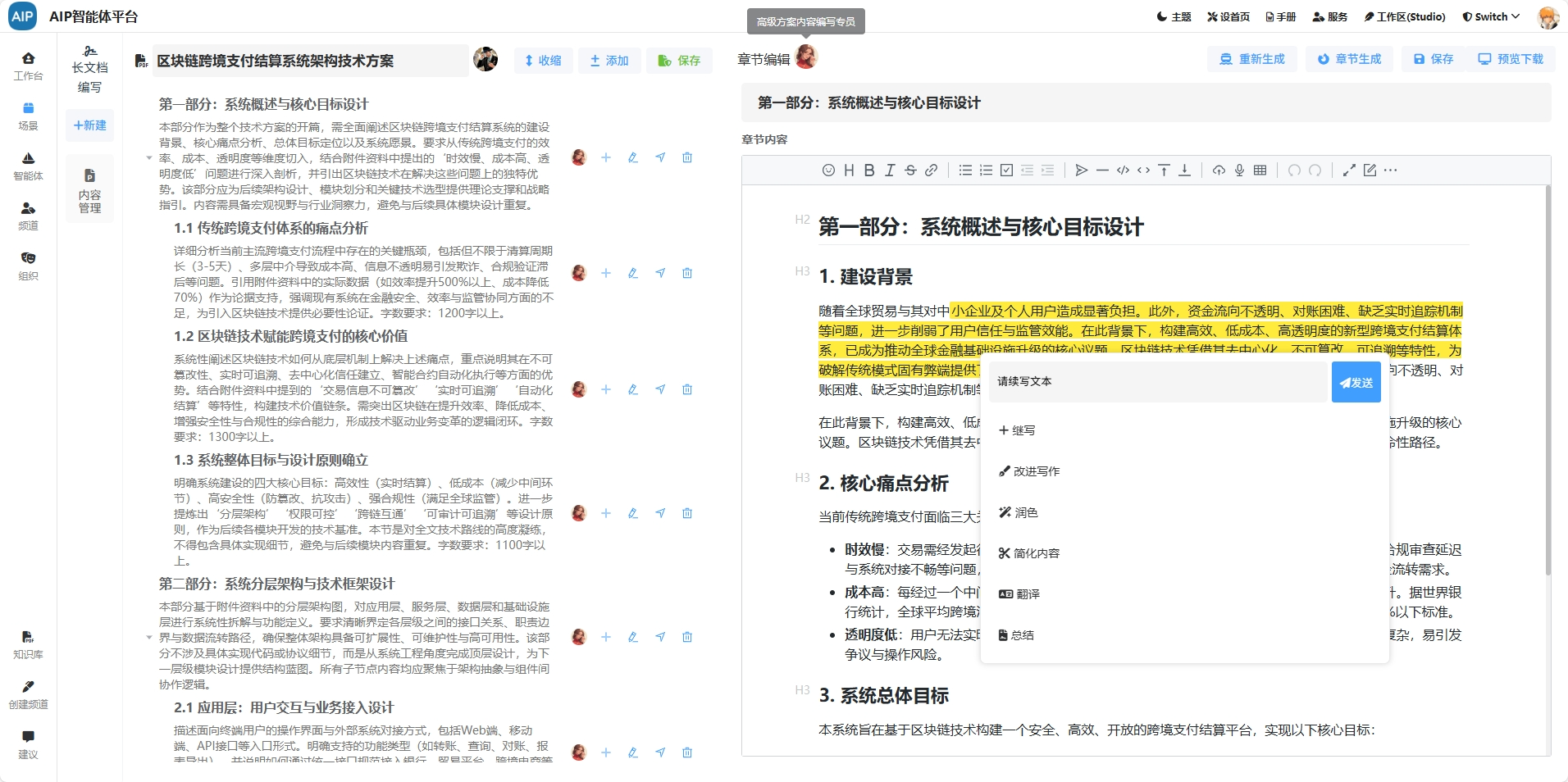
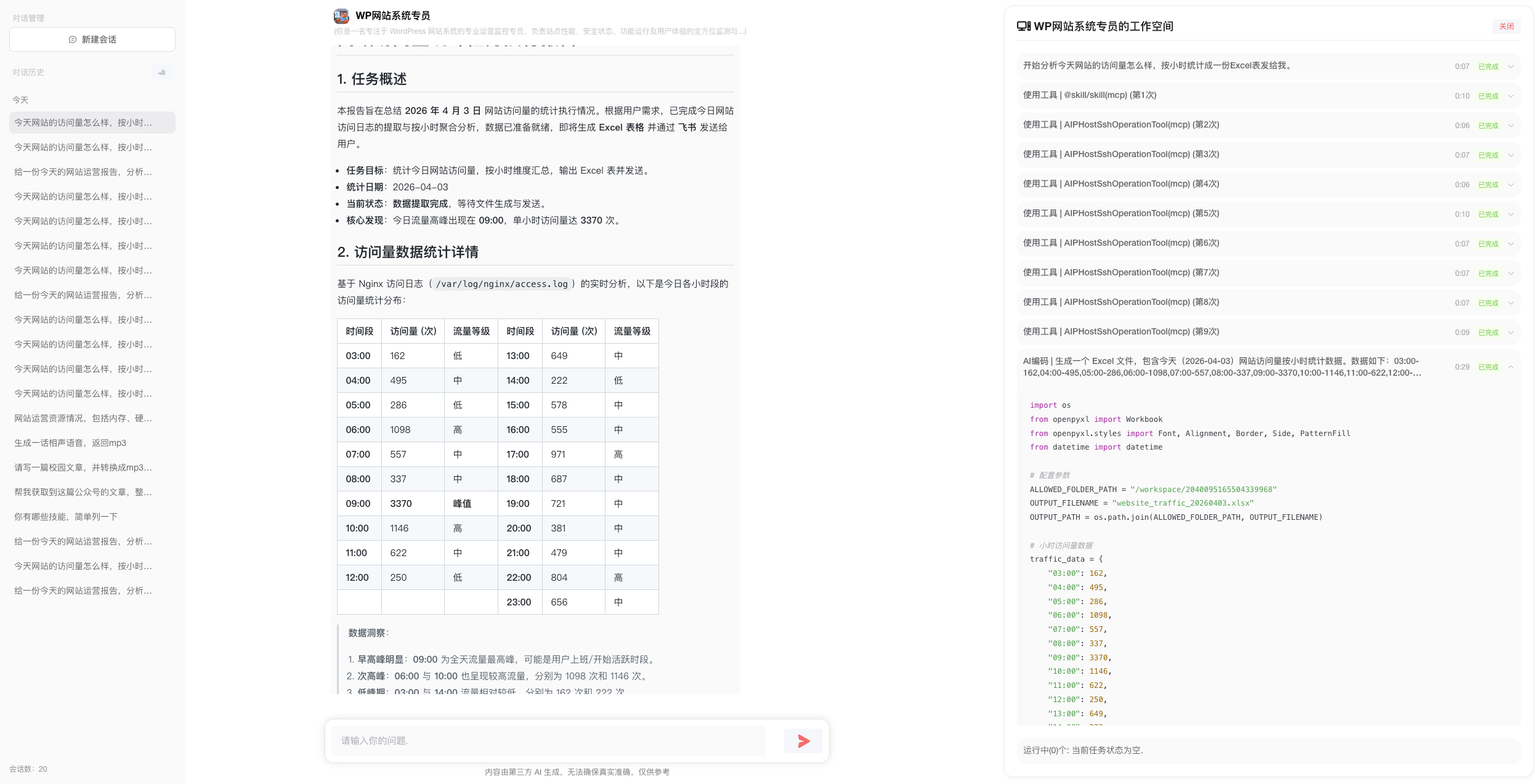
对话过程可视化,避免“黑盒卡顿”,参考ManusAI等优秀产品的交互逻辑,放弃纯结果输出模式,把Agent推理、工具调用、步骤执行的中间状态流式推送前端。用户能清晰看到AI在思考什么、调用了哪个工具、执行到第几步,既解决无响应焦虑,也方便排查异常。同时对长对话做步骤分段,单轮对话迭代严格控制在合理区间,超出则自动触发阶段性总结,防止上下文膨胀导致的响应变慢。
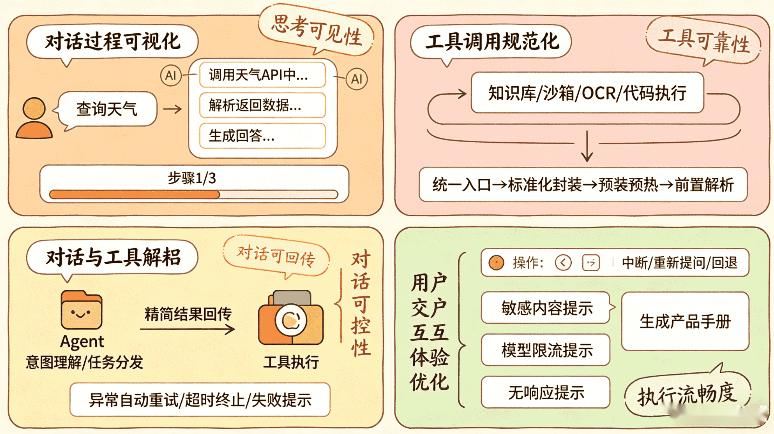
工具调用规范化,减少无效执行,统一工具入口与调度逻辑,内置工具(知识库、沙箱、OCR、代码执行等)与自定义工具做标准化封装,避免工具参数混乱、调用失败。针对Sandbox、Python环境、Docker等执行环境,提前做好预装与预热,数据解析(如文档OCR、格式转换)前置处理,减少Agent实时计算压力,提升工具调用成功率。
对话与工具解耦,防止互相干扰,主对话Agent专注意图理解与任务分发,工具执行交由专用子Agent处理,执行完毕后只把精简结果回传主Agent,不把工具执行日志、冗余参数带入主上下文。同时建立工具调用失败兜底策略:异常自动重试、超时自动终止、失败给出明确提示,避免单次工具异常导致整段对话崩溃。
动态Prompt适配工具场景,不同工具匹配专用对话Prompt模板,而非一套通用Prompt适配所有场景。比如代码工具触发时自动加载CodeAct专属Prompt,规划任务时切换为Planning模式Prompt,通过动态拼接保证对话指令与工具能力高度匹配,既提升执行准确率,也降低上下文混乱概率。
用户交互体验优化,支持对话中断、重新提问、步骤回退,避免一旦启动多步执行就无法干预的问题;对敏感内容、模型限流、无响应等异常做友好提示,而非后台静默报错;同时对AI文档生成这类重工具场景,对话只保留核心指令,减少无关闲聊占用上下文,保障工具执行效率。
多Agent和后台任务的管理
体验版中大量AI文档为多Agent循环协作生成,对话也存在主从Agent配合,因此多Agent调度与后台任务治理是保障平台稳定的核心,相关实践总结如下:
串行优先,严控并发,保障稳定性,早期多Agent并行执行(Planning模式批量任务)频繁出现线程冲突、资源抢占、模型限流叠加等问题,直接导致任务中断。后续全部改为串行执行,放弃并行速度换取整体可用度,即使同时触发多个Agent任务,也按队列依次执行,避免并发带来的不可控异常。
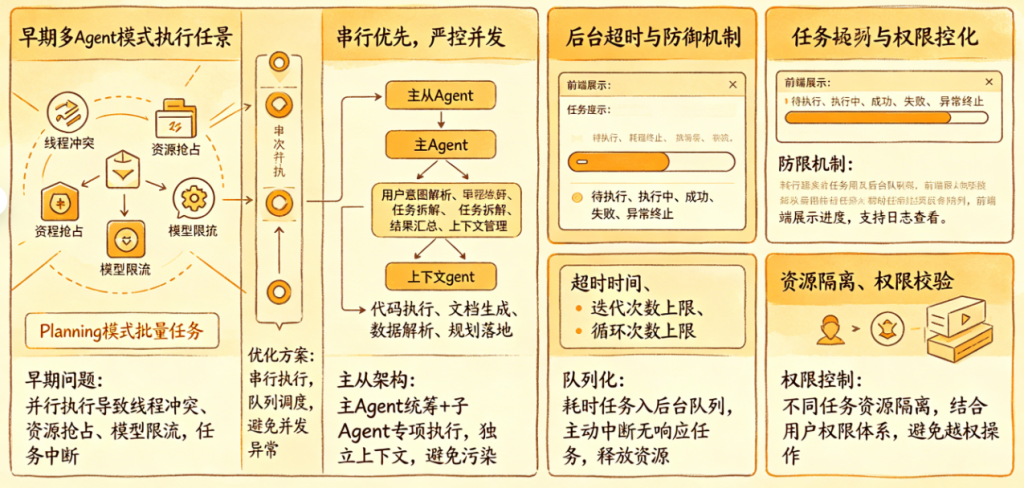
主从Agent架构,职责清晰不污染,采用“主Agent统筹+子Agent专项执行”模式:主Agent负责用户意图解析、任务拆解、结果汇总与上下文管理;子Agent(SubAgent)专注单一任务,如代码执行、文档生成、数据解析、规划落地等。子任务独立上下文、独立生命周期,执行完成后销毁,不污染主Agent对话历史,也避免多任务之间互相干扰。
后台任务队列化,支持异步与可观测,对耗时任务(长文档生成、多步骤规划、批量工具执行)统一放入后台任务队列,前端展示任务进度,不阻塞前端对话。任务状态实时同步:待执行、执行中、成功、失败、异常终止,支持查看执行日志。同时自研框架内置任务可观测能力,可追踪每个Agent的调用链路、耗时、异常点,方便快速定位问题。
任务超时与防御机制,防止死循环,为每个Agent任务设置执行超时时间,单Agent迭代次数上限、多Agent循环次数上限,超出则强制终止并做防御性总结,避免因模型思考发散、工具死循环导致资源耗尽。后台任务支持手动取消、自动重试,对无响应任务做主动中断,释放服务器资源。
资源隔离与权限控制,不同Agent任务做资源隔离,防止单个任务异常影响整个平台;结合用户权限体系,对后台任务做权限校验,避免越权调用工具或执行高危操作。自研框架的灵活性在此体现明显,可快速适配多Agent场景下的权限、资源、日志等管控需求。
总结
这一年AI平台体验版的运营数据与实际落地经验,虽整体体验用户规模仍偏初期,为自研Agent平台交出了阶段性的实践反馈。目前更专注于AI工程化落地与Agent体系打磨,全程围绕稳定性优先、体验可控、架构自主可控的思路推进。
每个产品设计思路不一,这个是建设Agent平台的一些经验,期望给有兴趣的朋友参考,也欢迎交流。