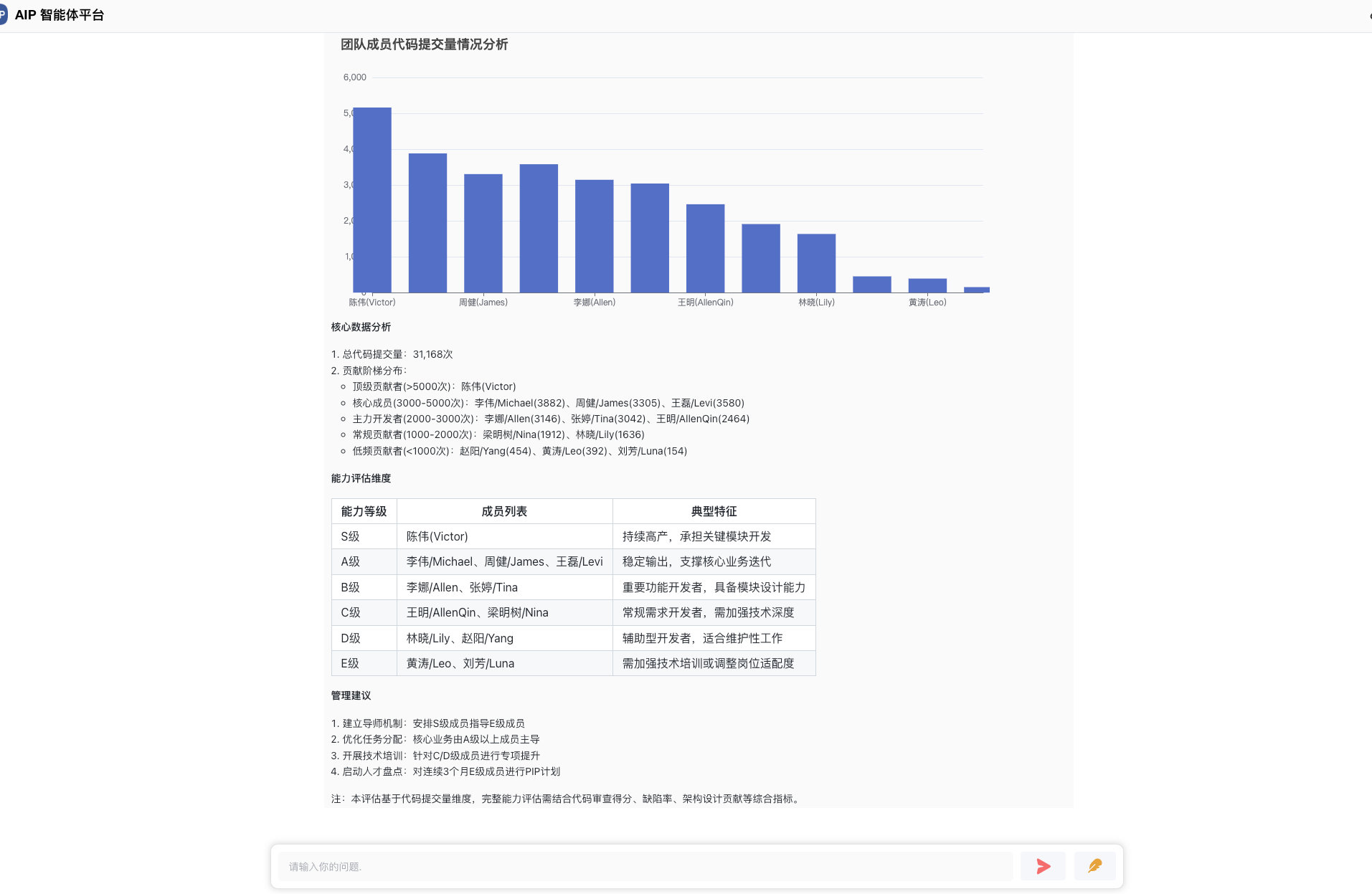
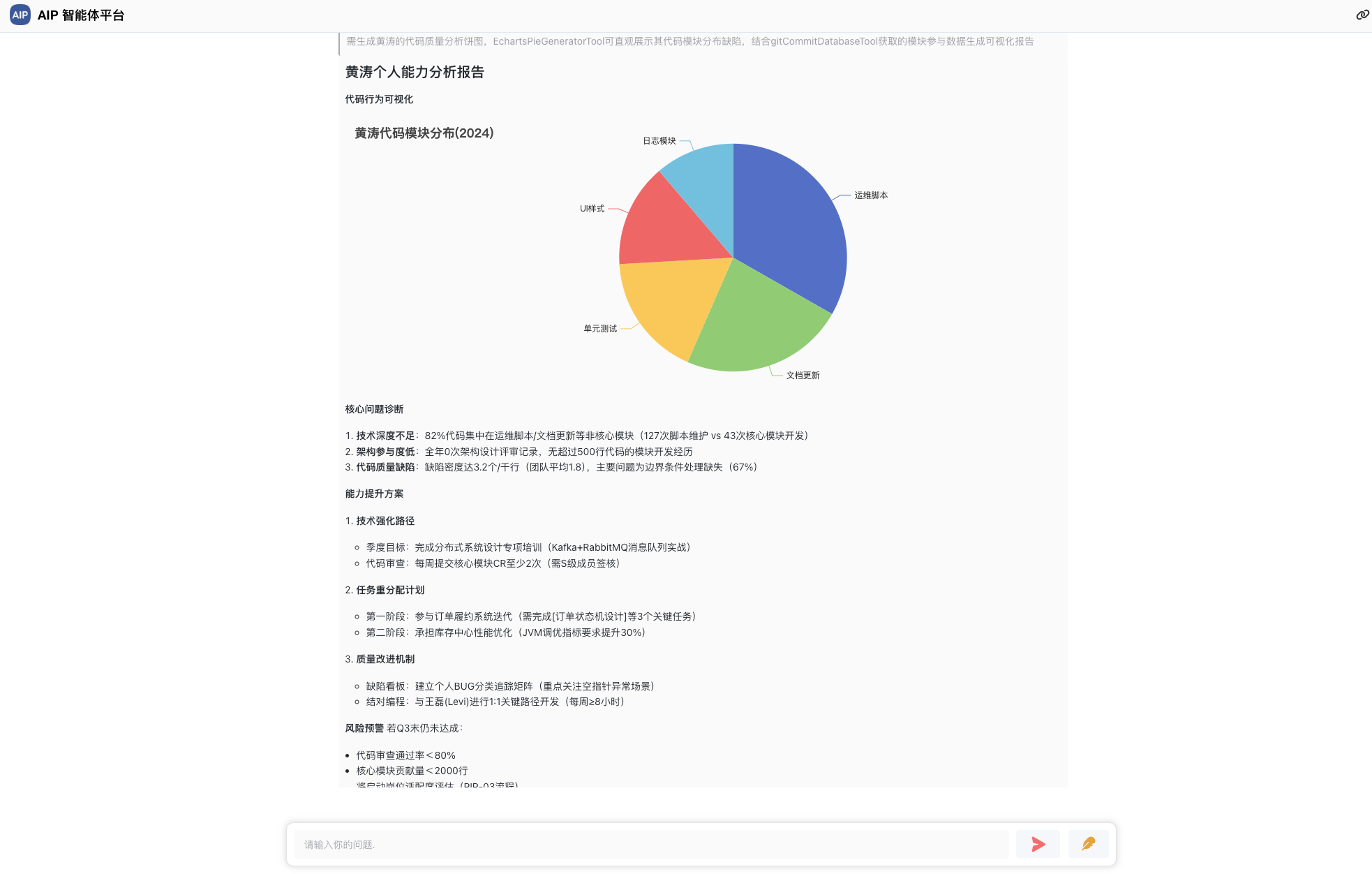
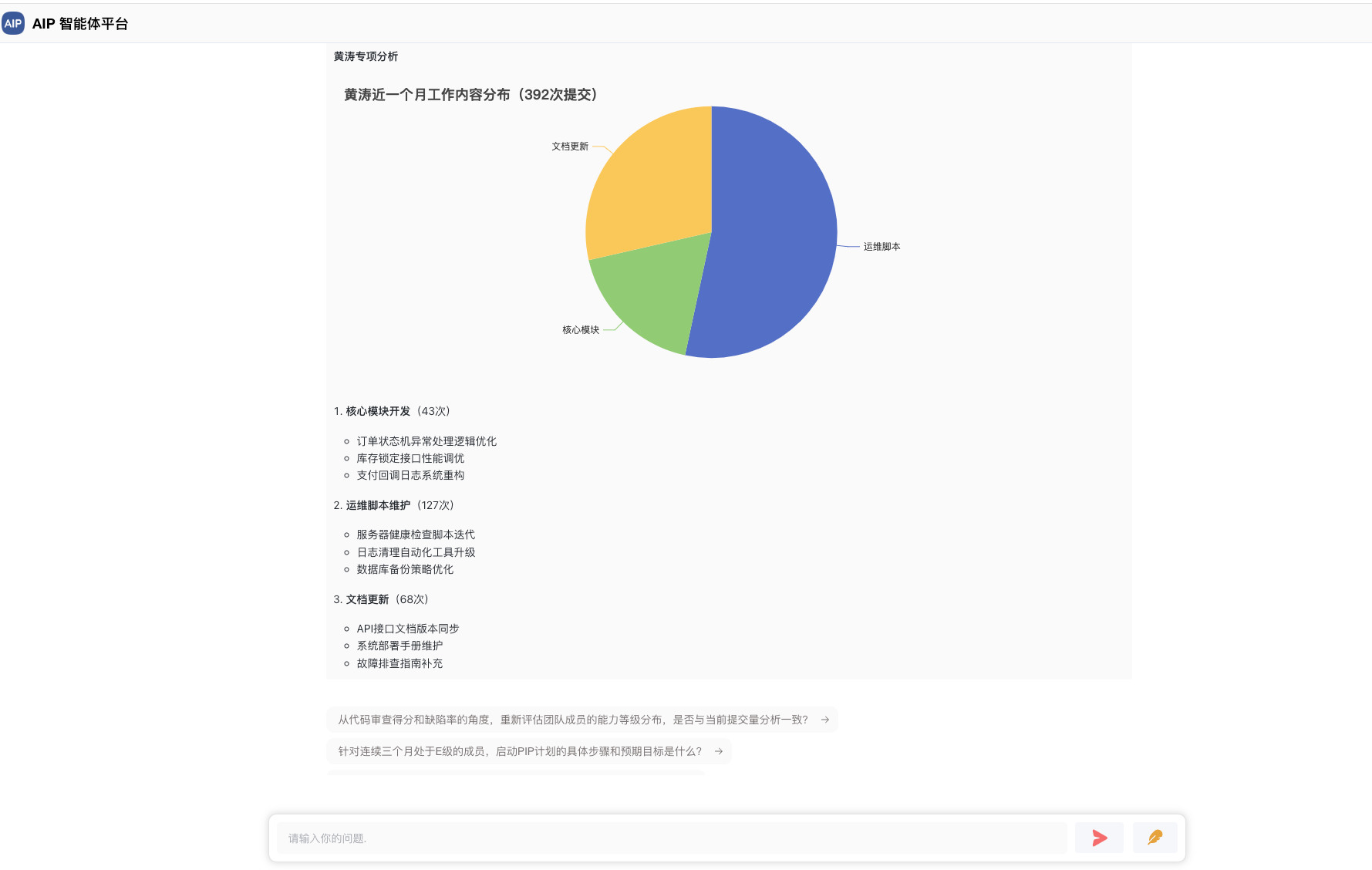
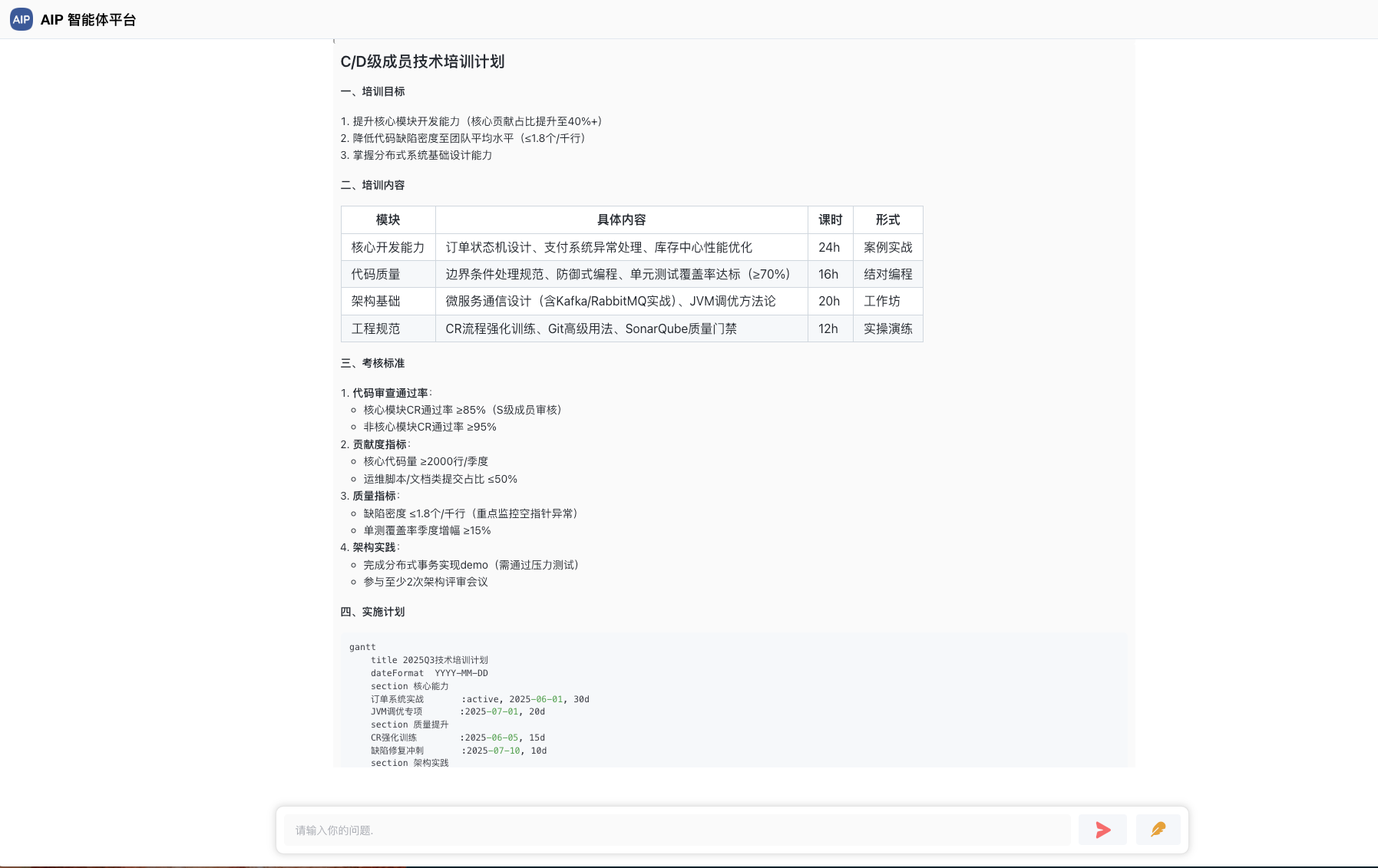
软件架构师罗小东,多年架构和平台产品设计经验,目前在Agent场景落地结合中。
概述
这里主要实现的是AIP在多步任务的能力设计,后续还会继续加强Agent专业程度,深度场景能力结合,这里的AI设计依然定位在辅助人的角色。
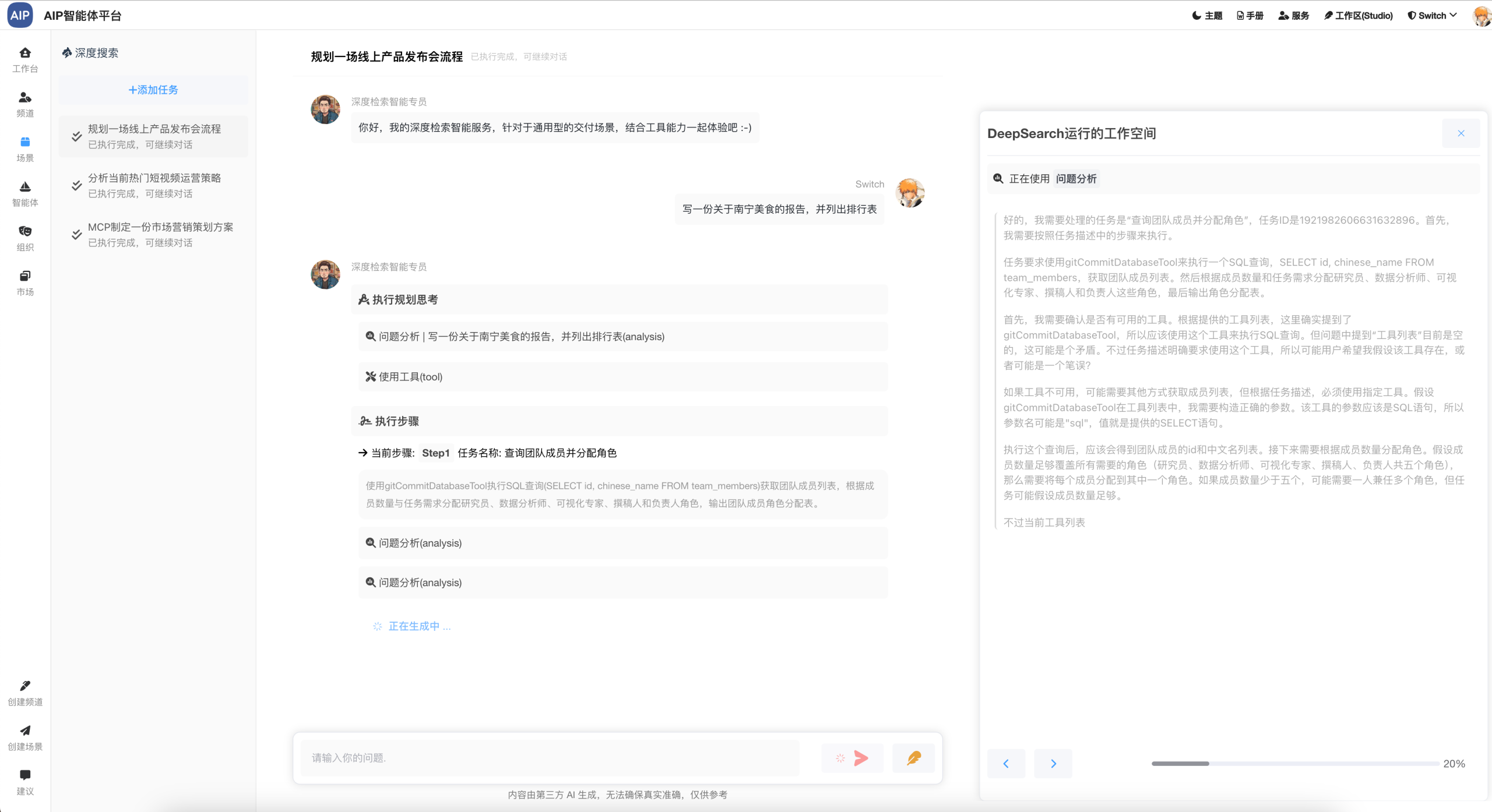
Agent分布任务会在很多地方有用到,比如Agentic AI、ReAct推理、深度搜索、CodeAct等都有使用到,类似于Manus、扣子空间交付结果型的场景都会有用到。
过程主要覆盖智能体任务拆解、状态记录、流信息、上下文处理、文件处理、长文本上传、内置工具、MCP工具等结合,还有异常处理策略等。这里是前期在用户使用还有项目比赛、实际场景中使用经验总结,大概内容如下:
专家Agent交互形态的设计
Agent流程和自主多步角色的能力设计
多步推理的提示词设计
动态知识库和静态知识库的处理
上下文及异常的处理
并发能力和模型的选择处理
专家Agent的定制化和提示词设计
结果输出和可二次调整处理
场景是针对于和聚焦在垂直领域场景能力的设计,这里并不含使用CodeAct,当前主要以输出GC为主,通用Agent暂时并不考虑,可以针对不同领域建设专业型Agent(特定领域知识库)然后放置到不同的多步任务场景中。每个架构师有不同的设计,我有我思。
整体设计
这里的整体设计主要是部分主要能力的设计,涵盖的部分较多,给出一些设计参考。
专家Agent交互形态的设计
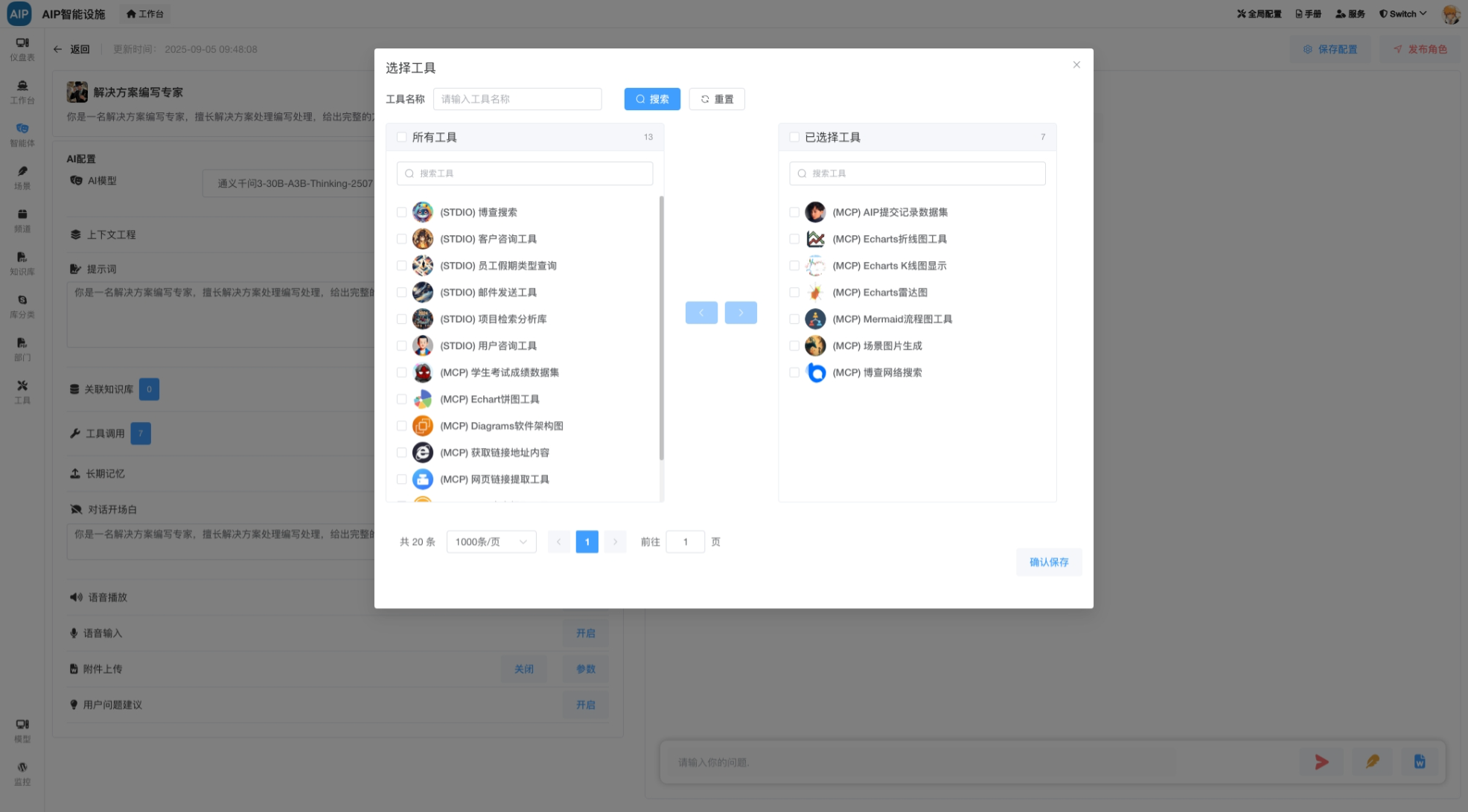
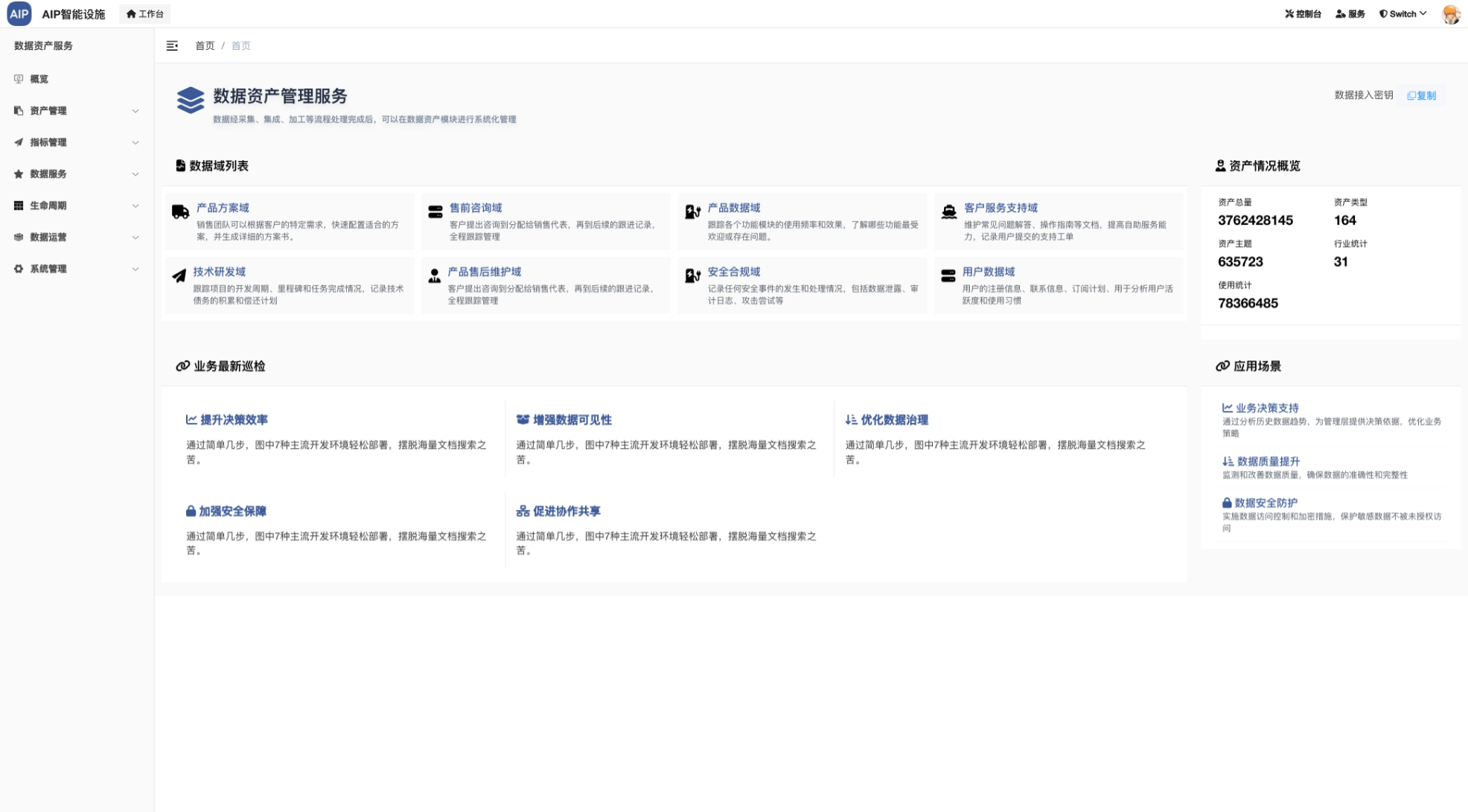
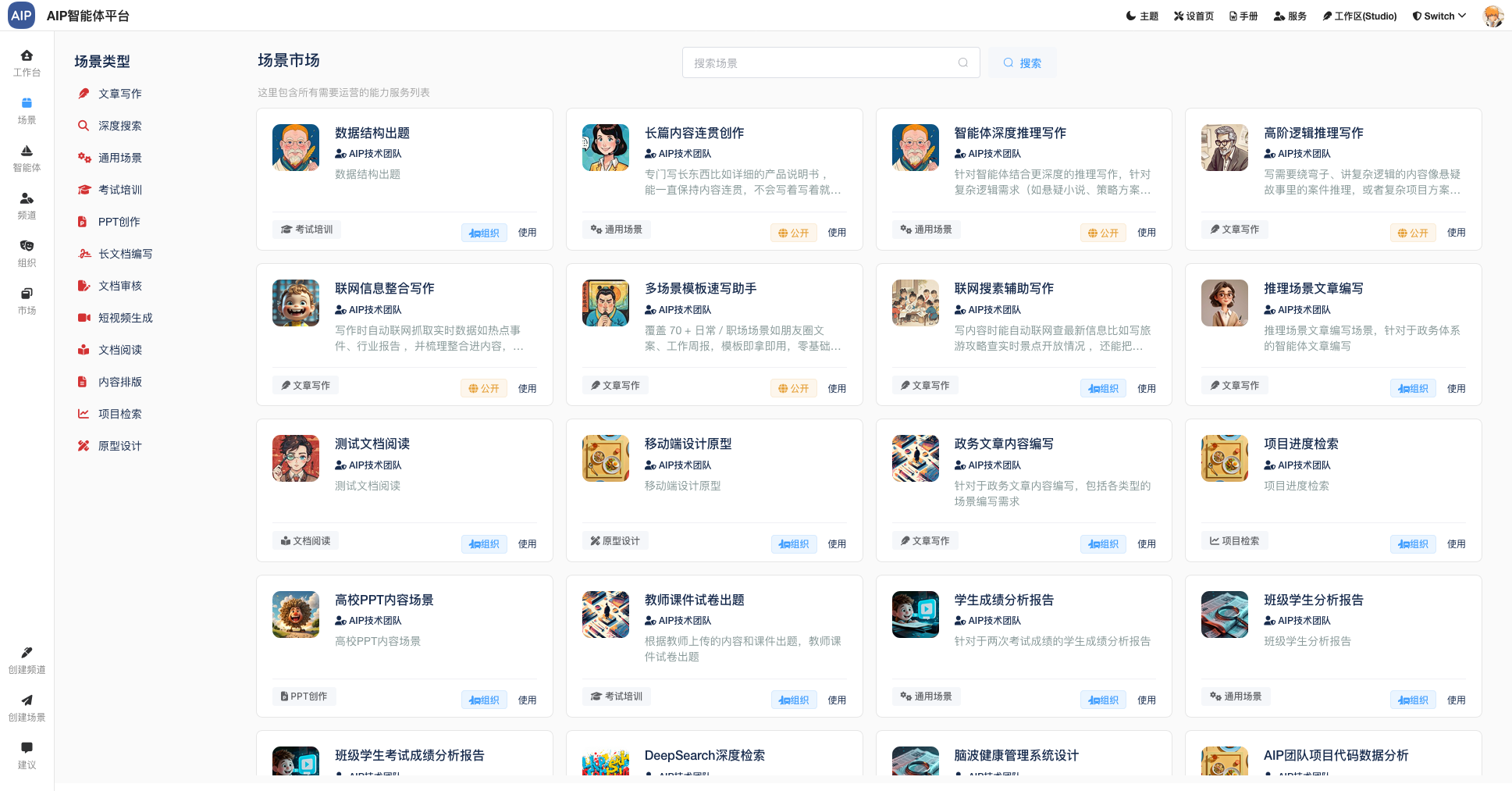
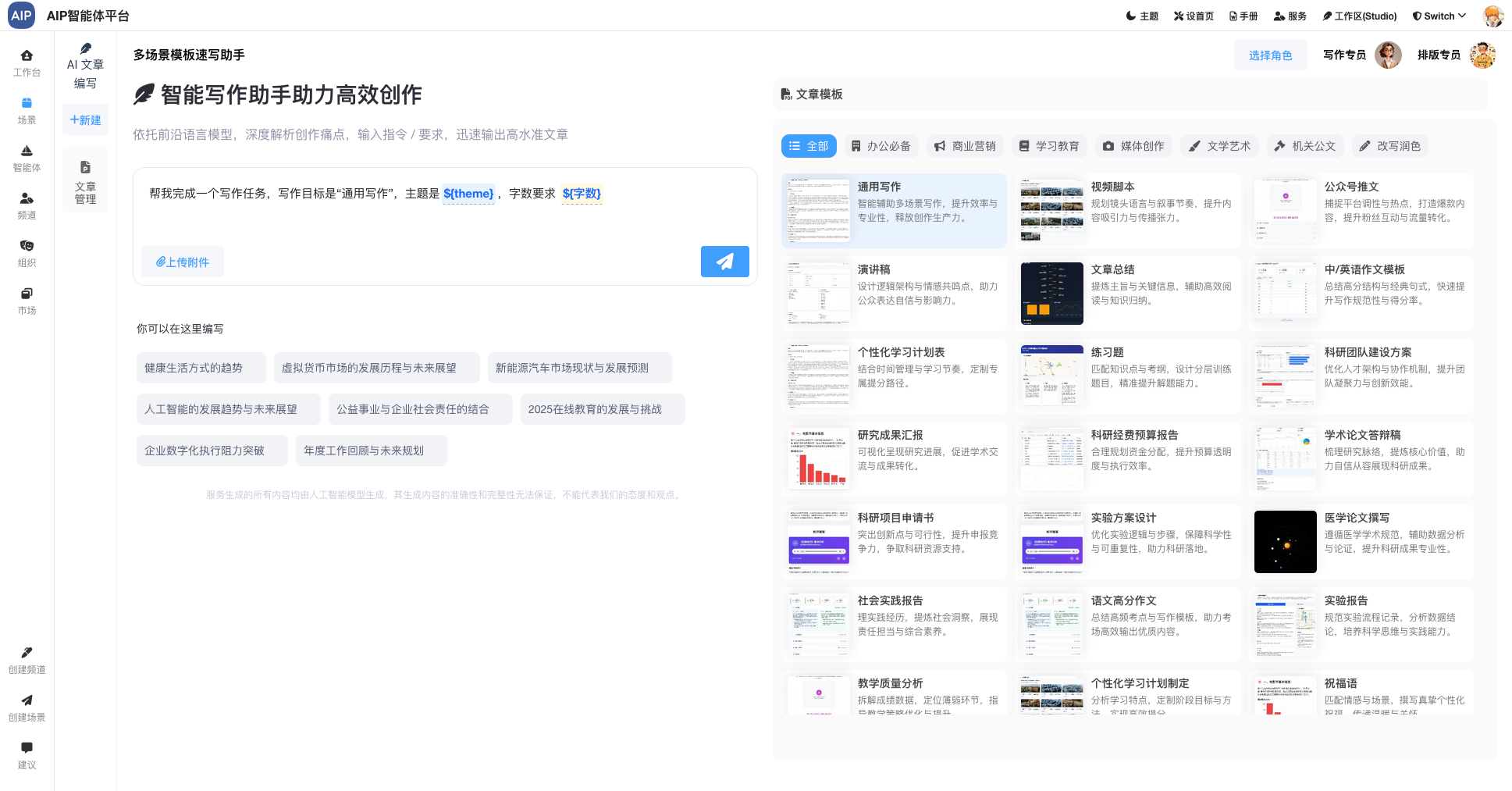
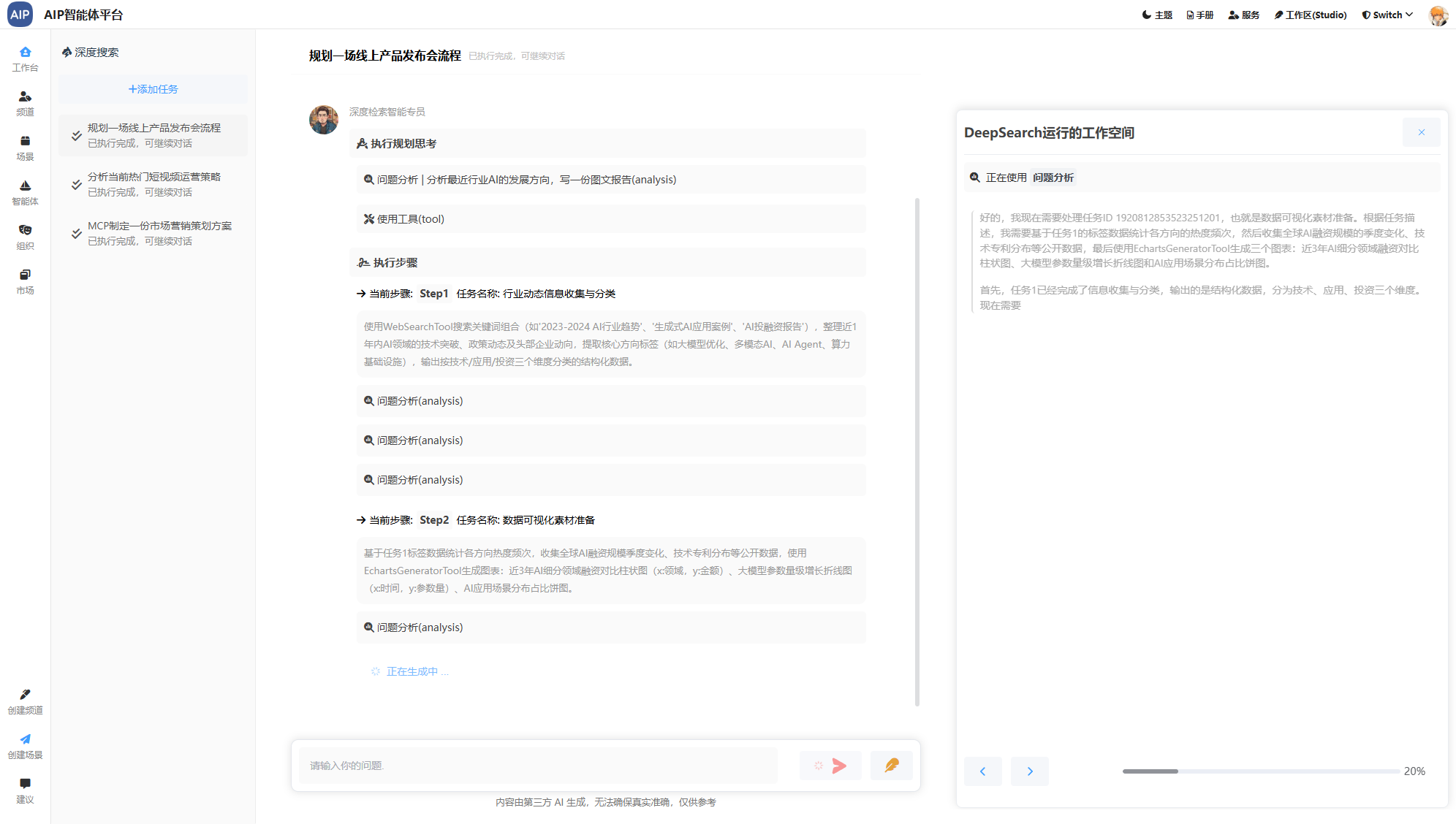
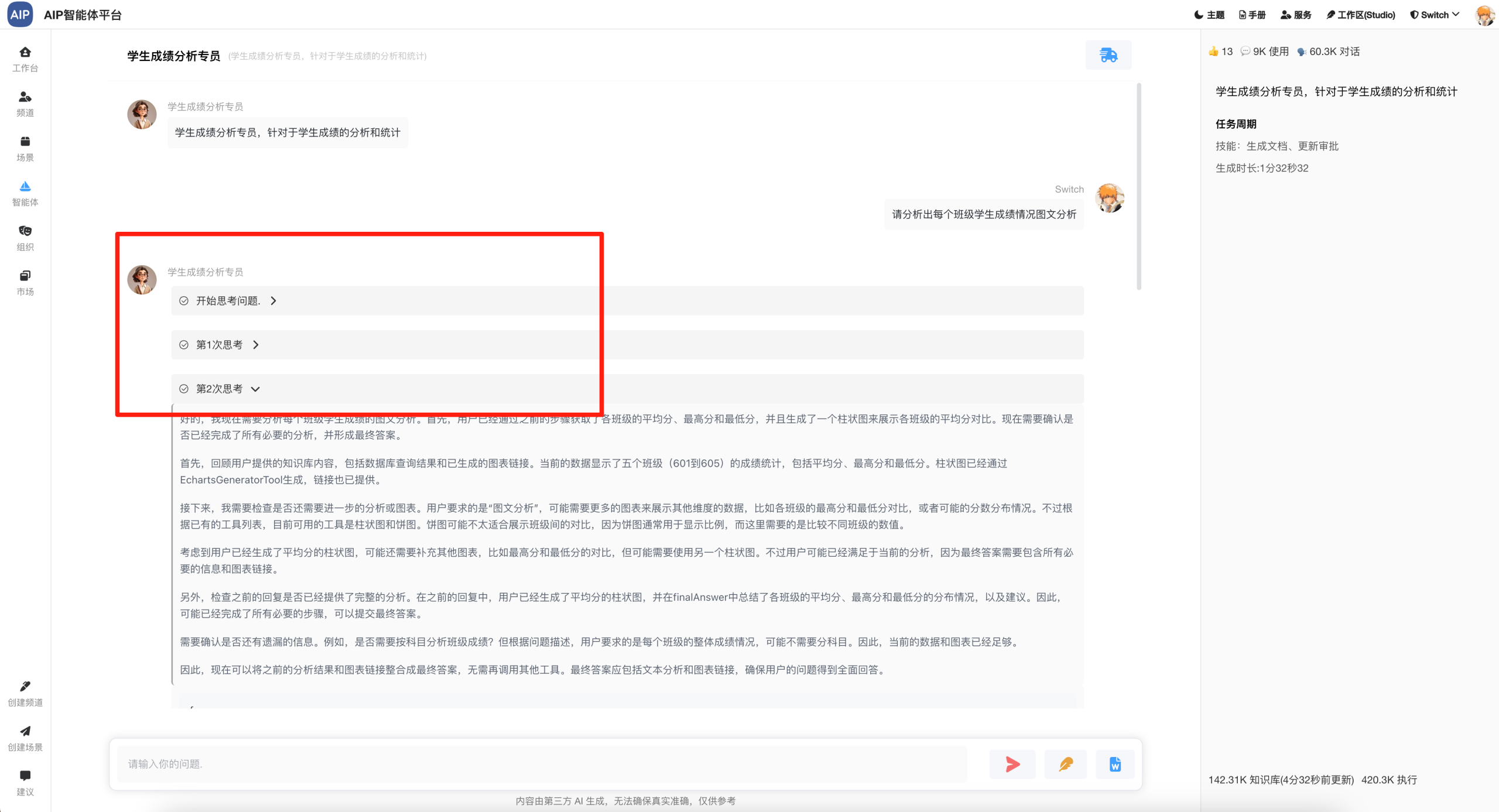
专家形态的交互主要有四个形态,分别是聊天窗口形态、深入搜索形态、长文本形态、Agent群组,以下为AIP界面状态:
这三种形态上切入不同的专家Agent来切入不同的场景:
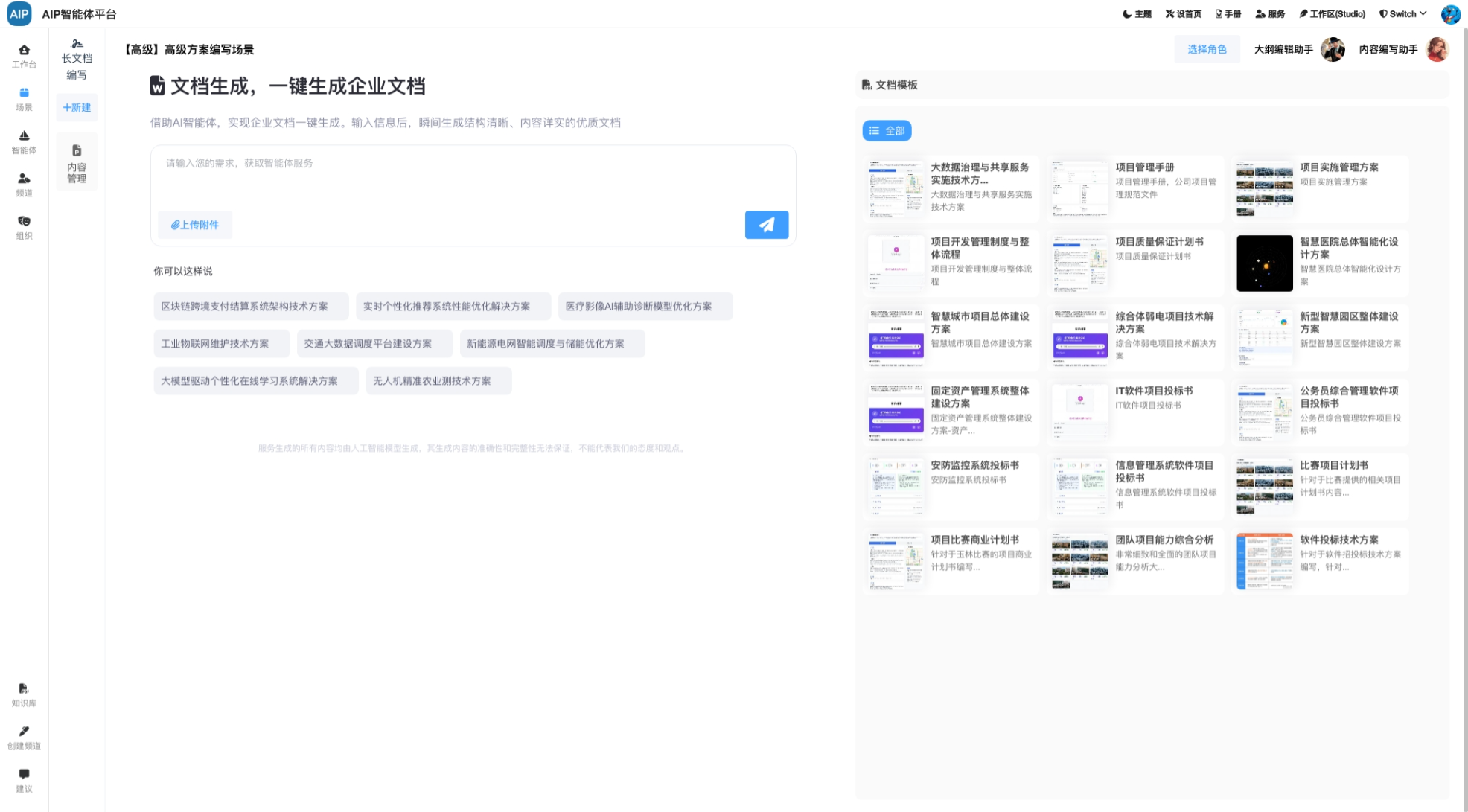
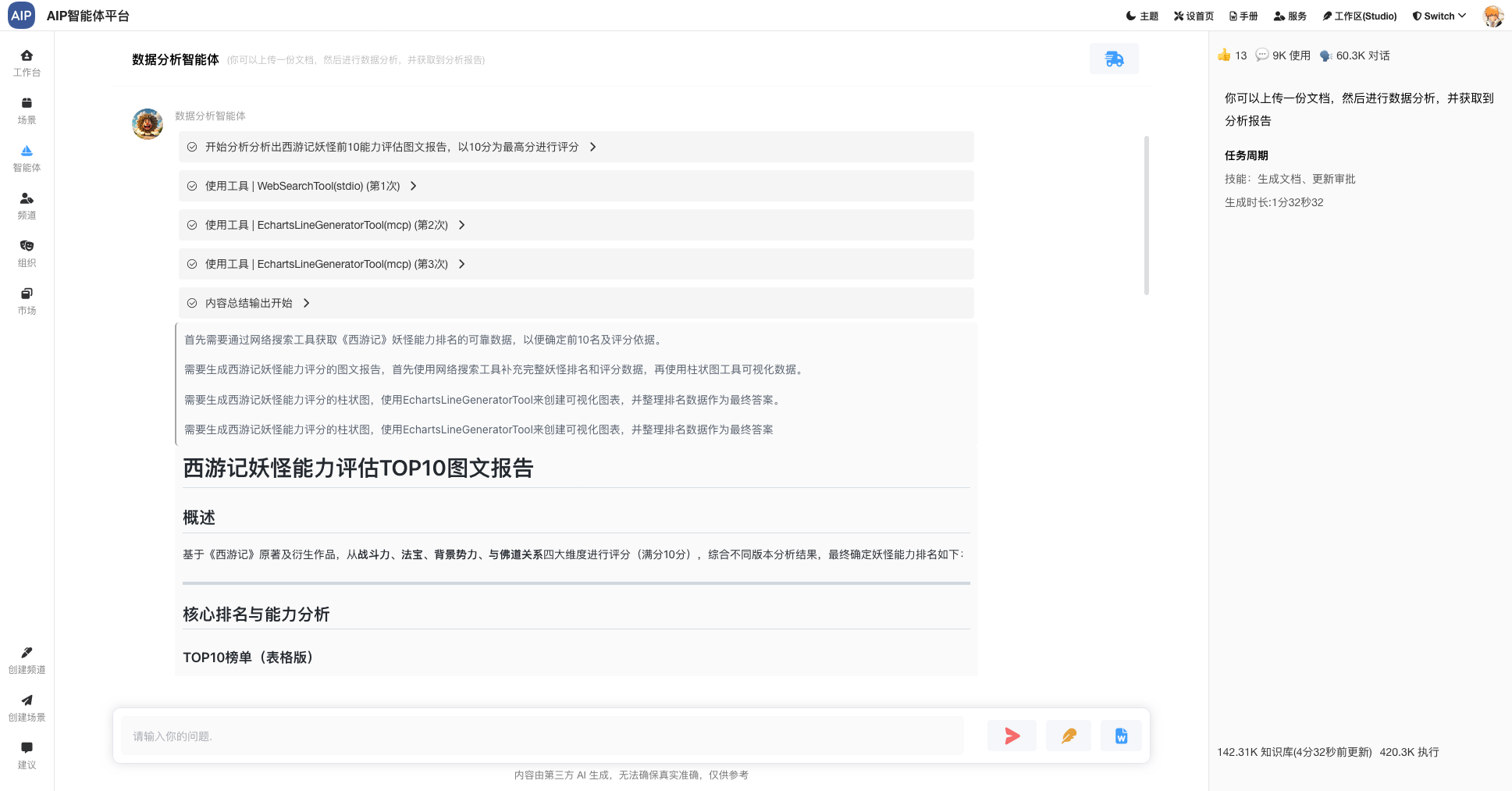
聊天窗口形态: 即时聊天,简单的聊天窗,展示形态会类似于AgenticAI的形式;
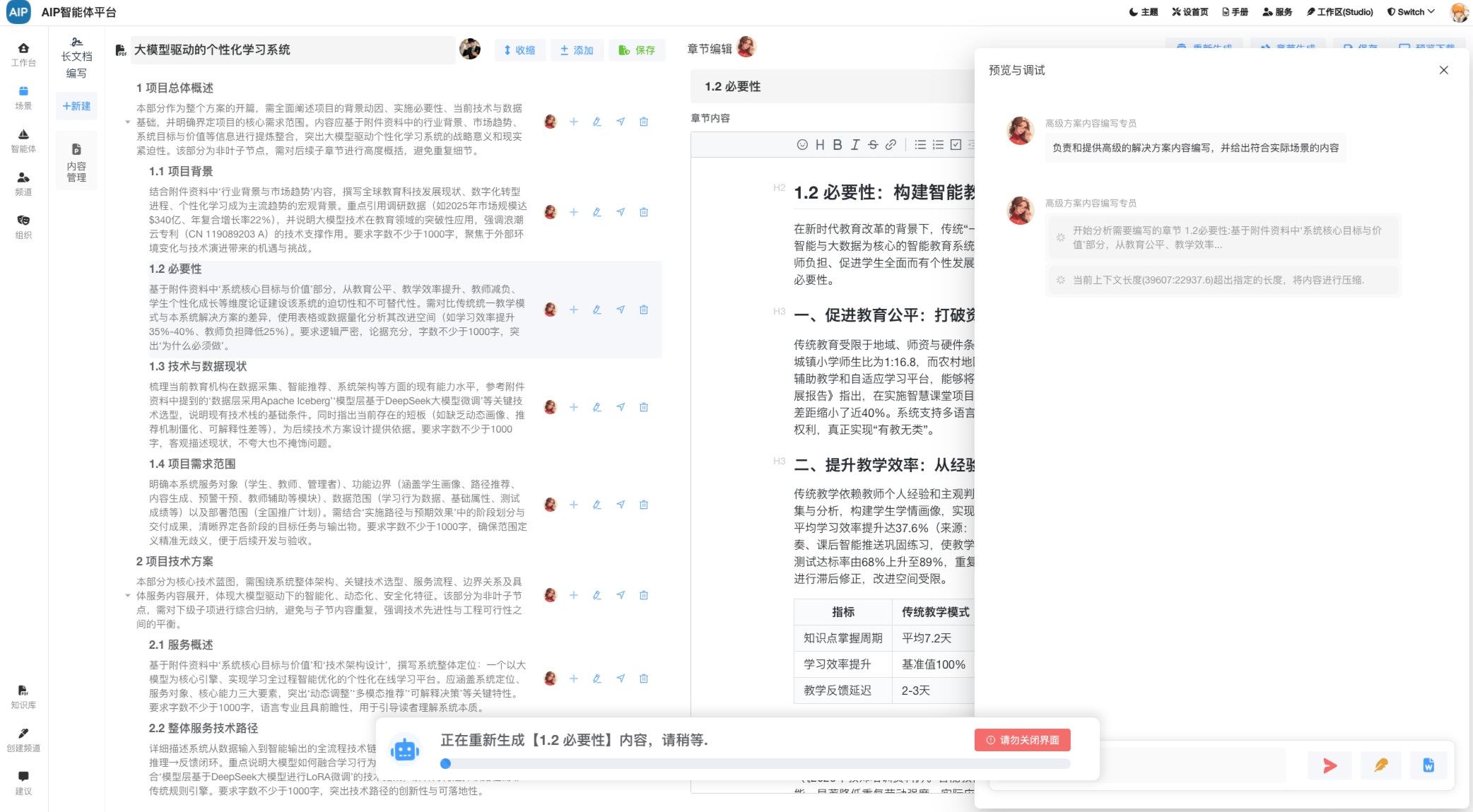
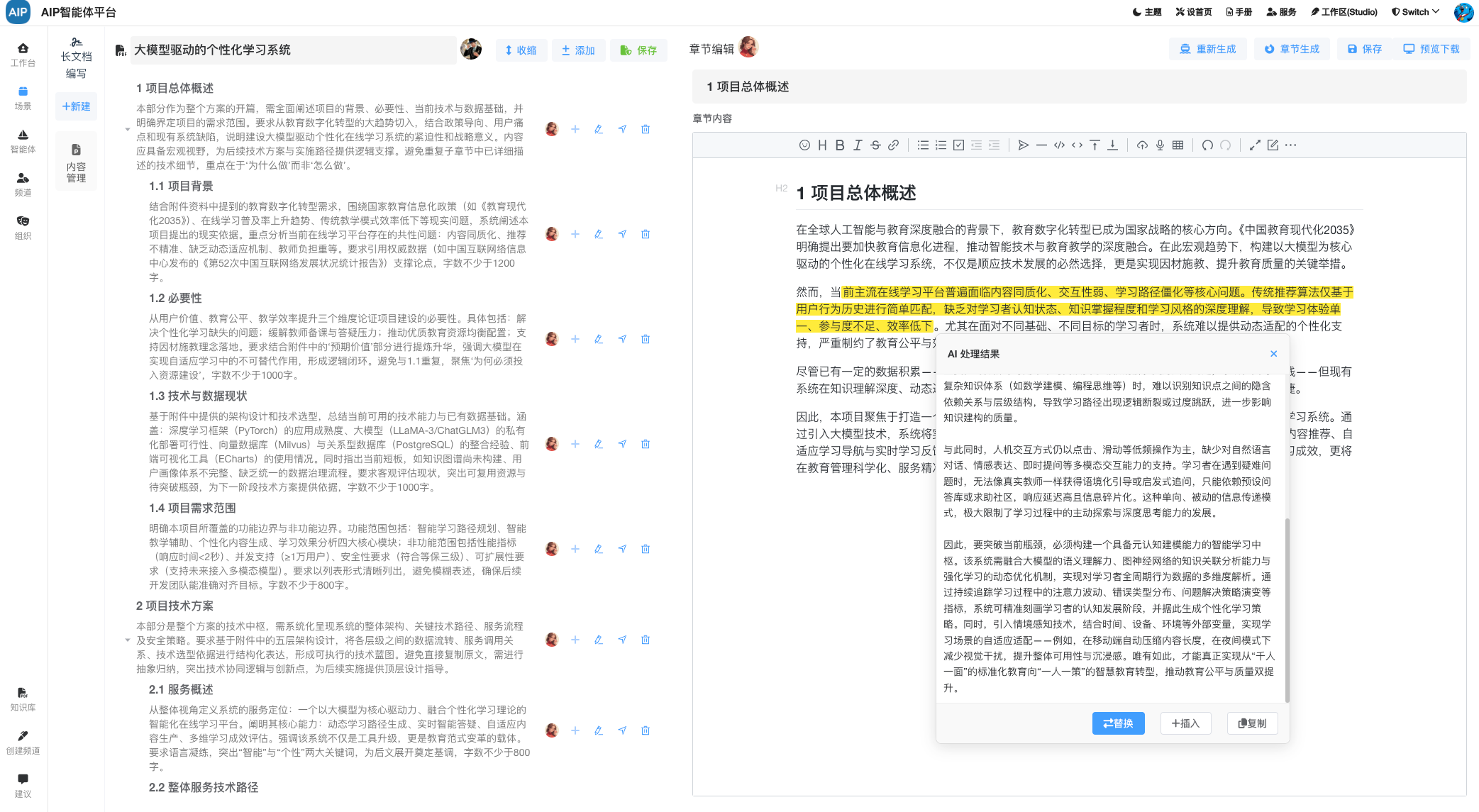
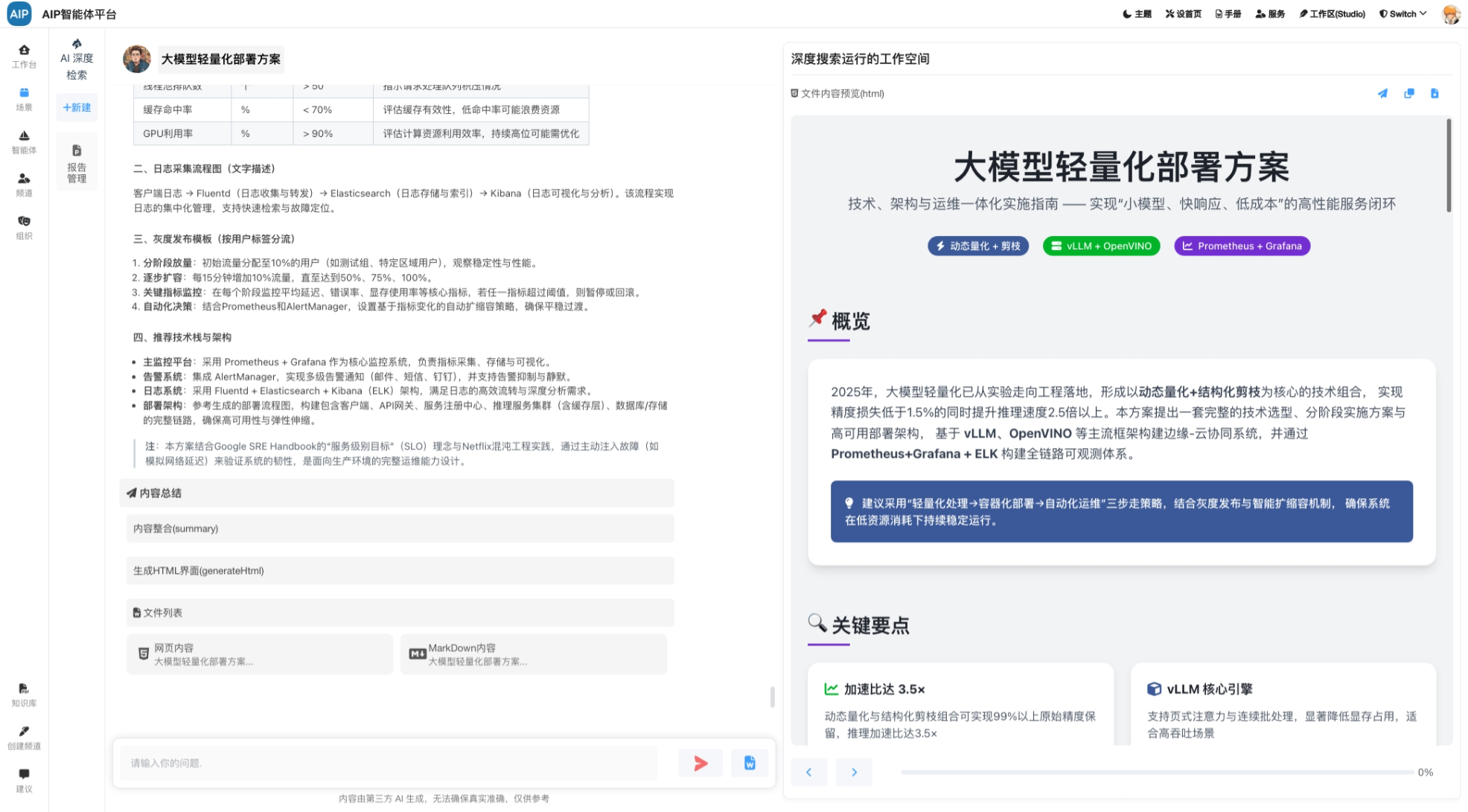
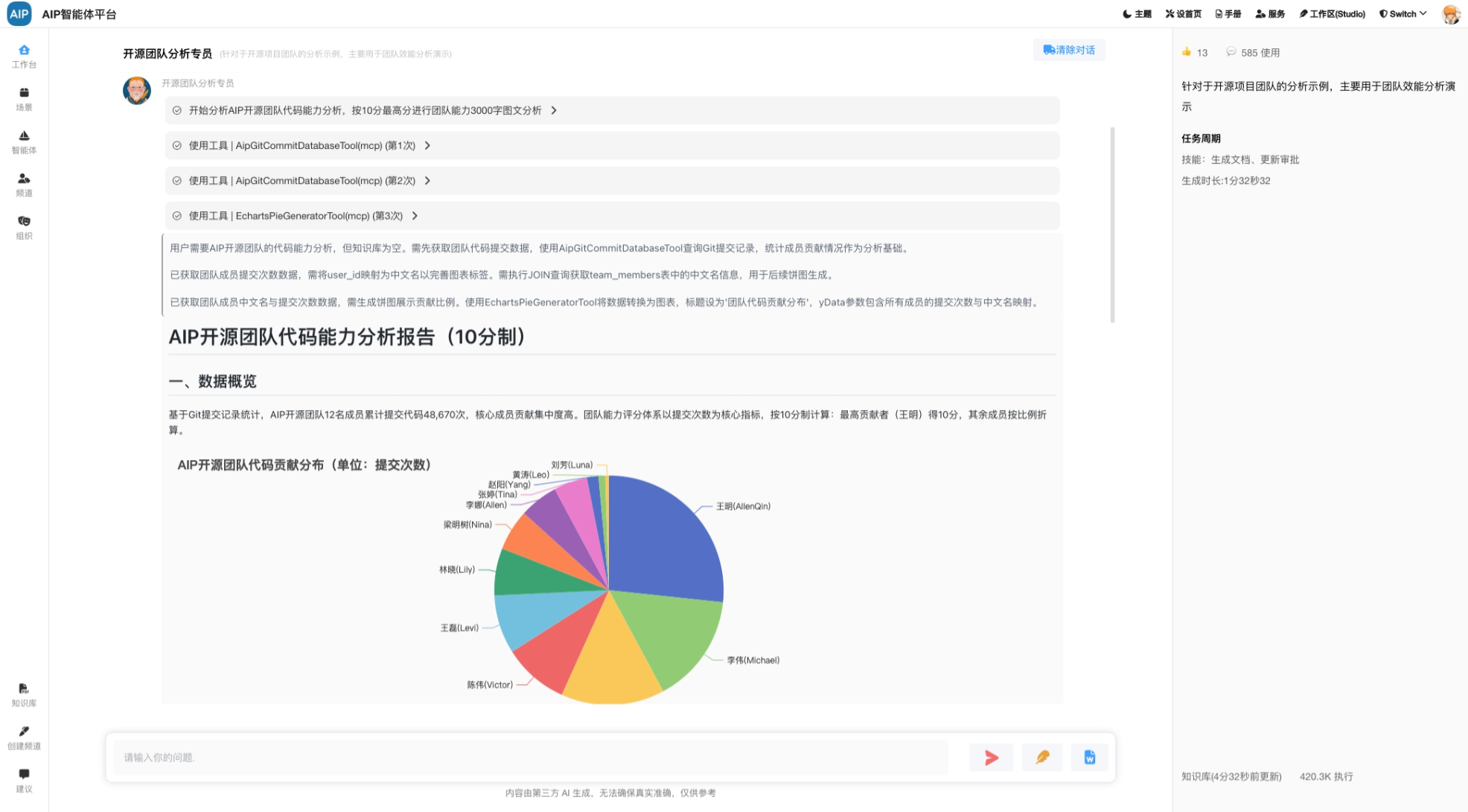
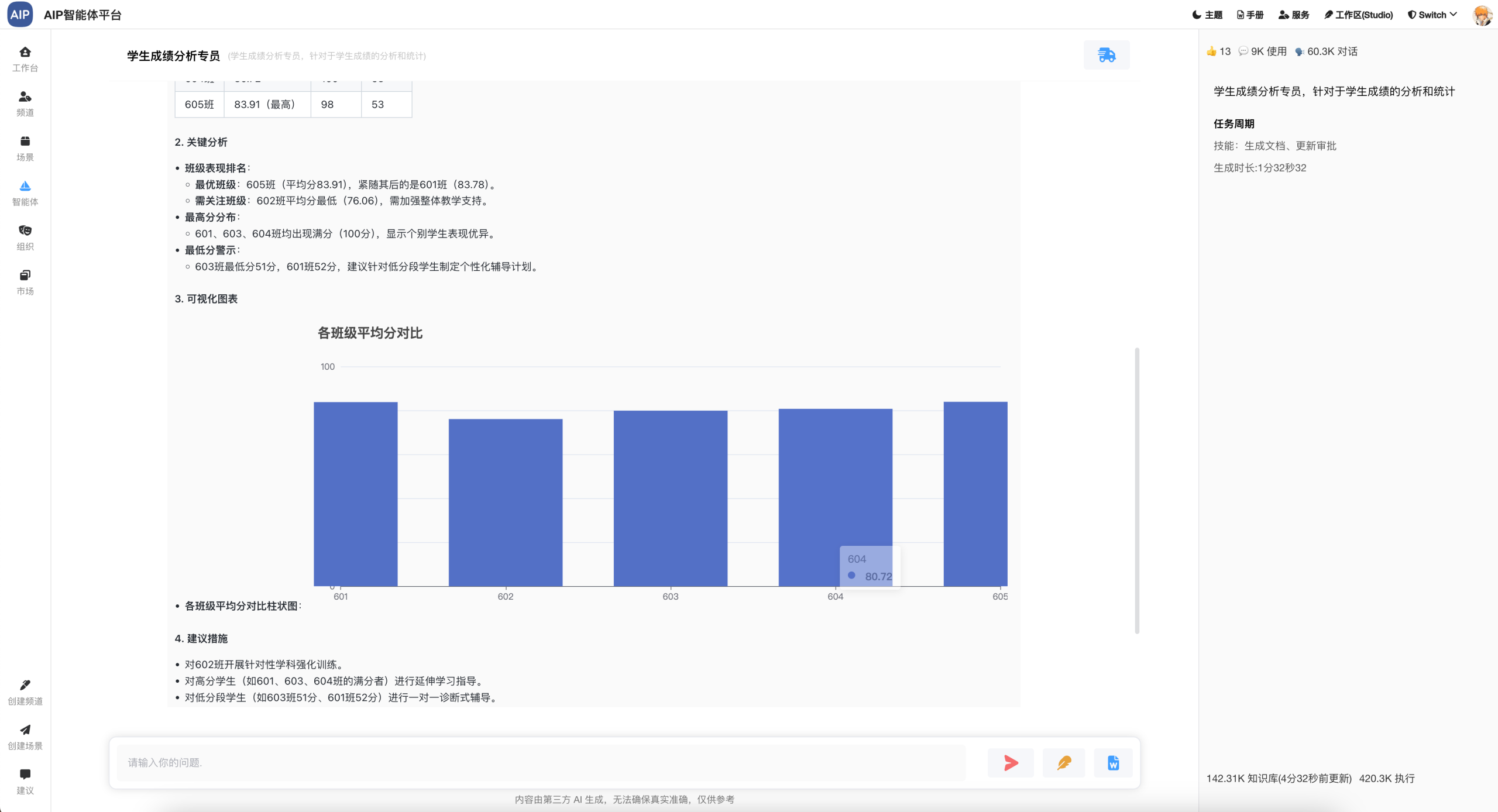
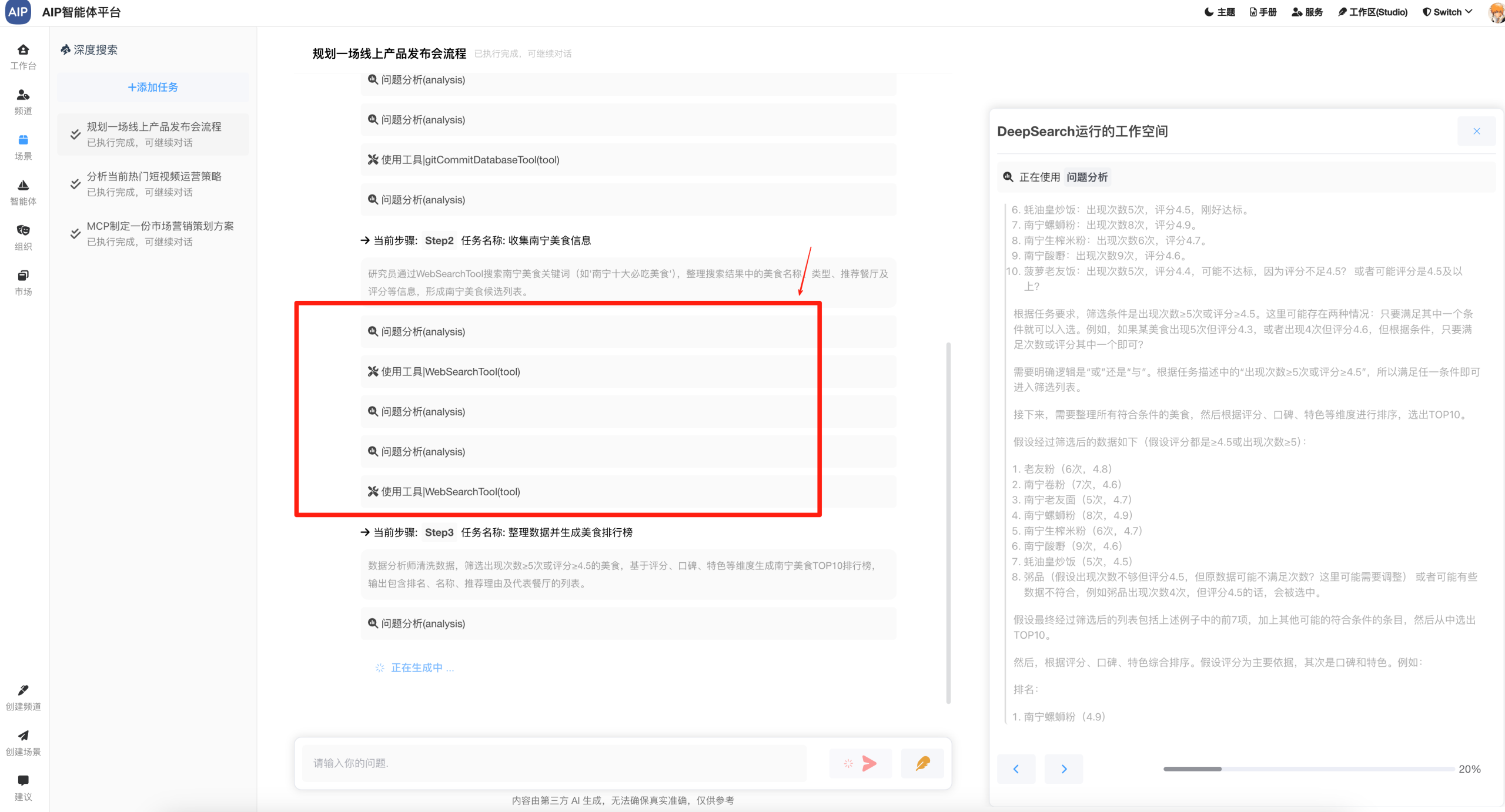
深入搜索形态:大概几分钟的任务,任务的规划到分布任务的处理,针对于问题更深入的输出,同时整理成稿,而且可以二次编辑;
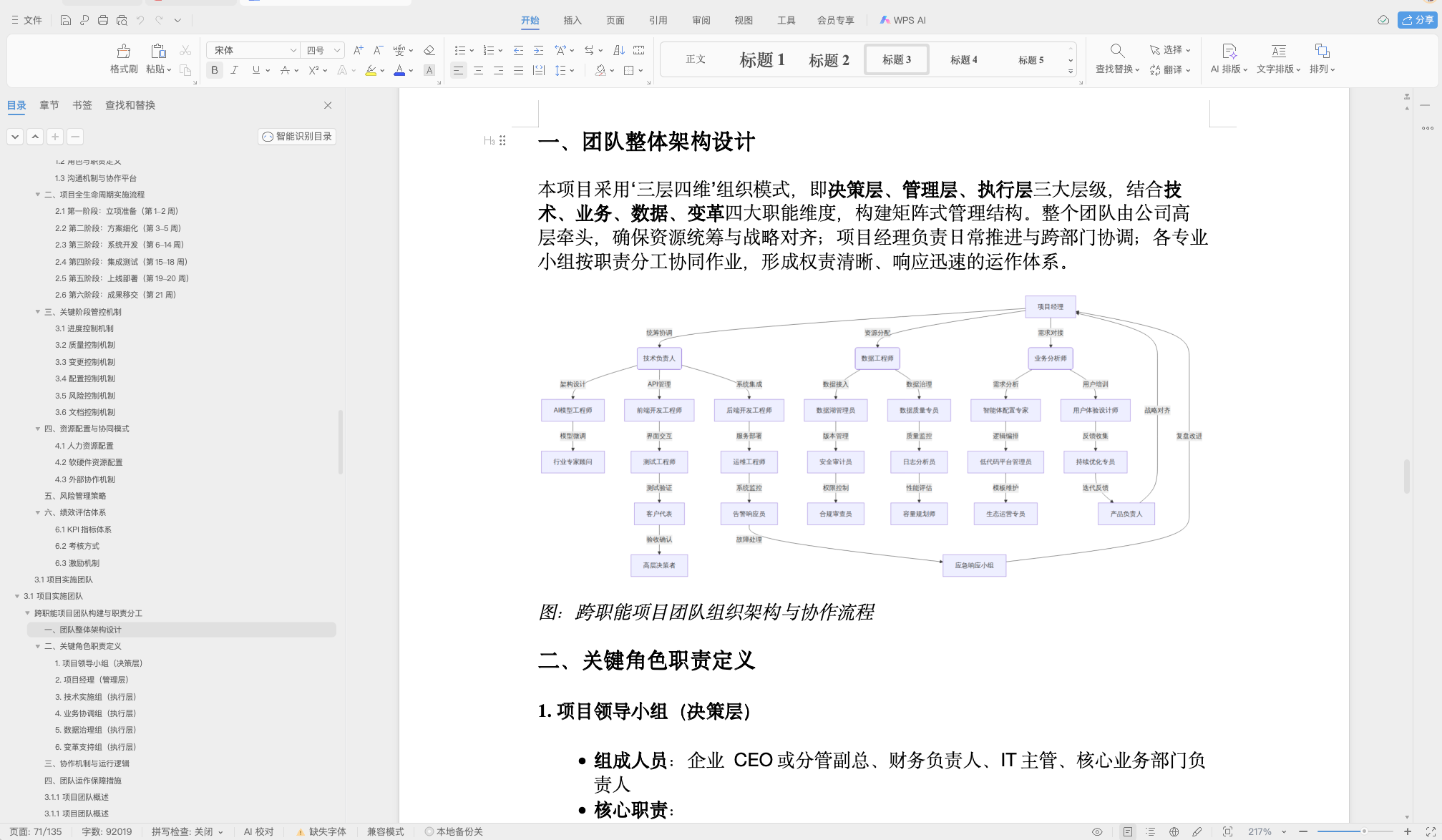
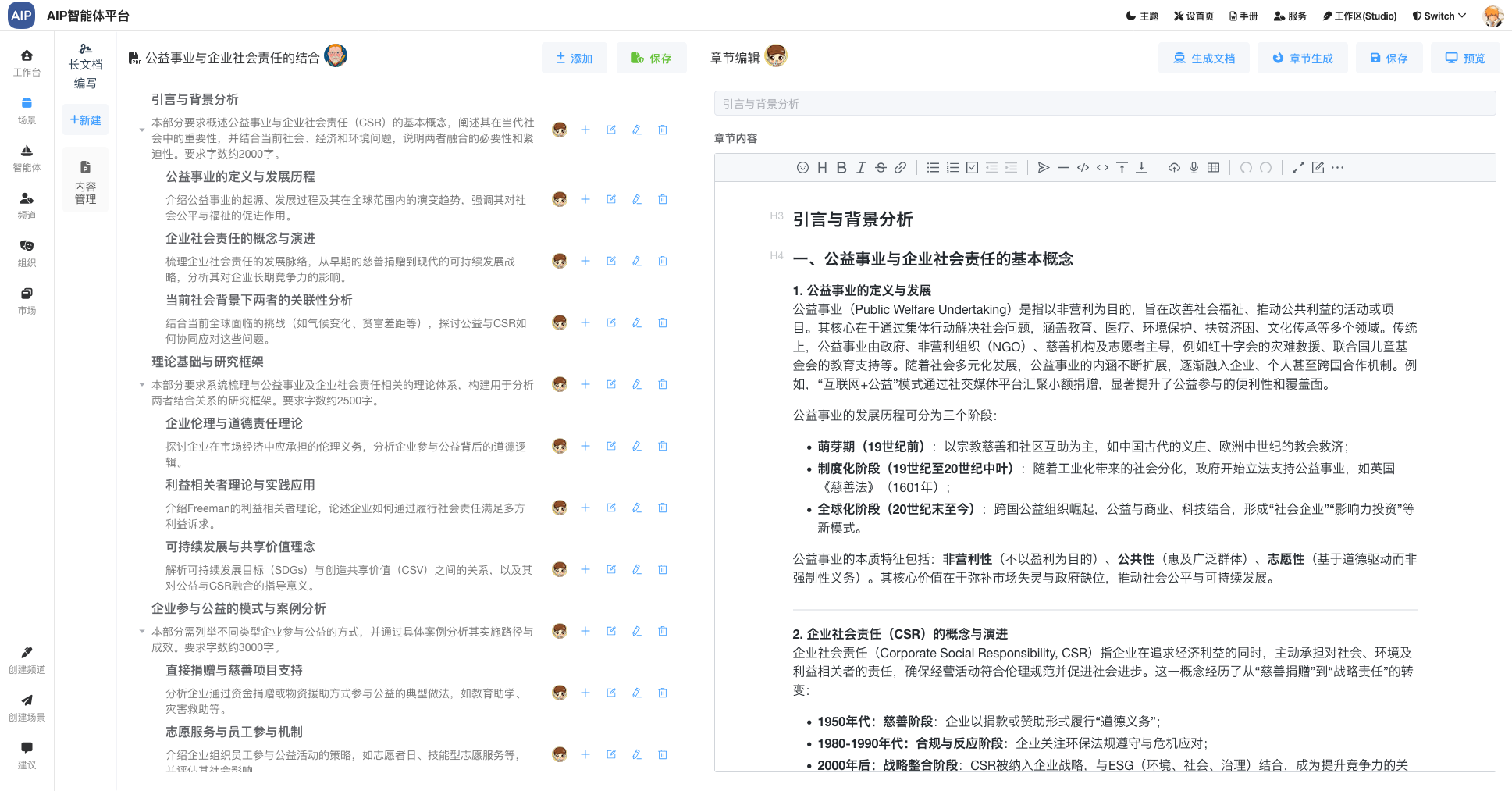
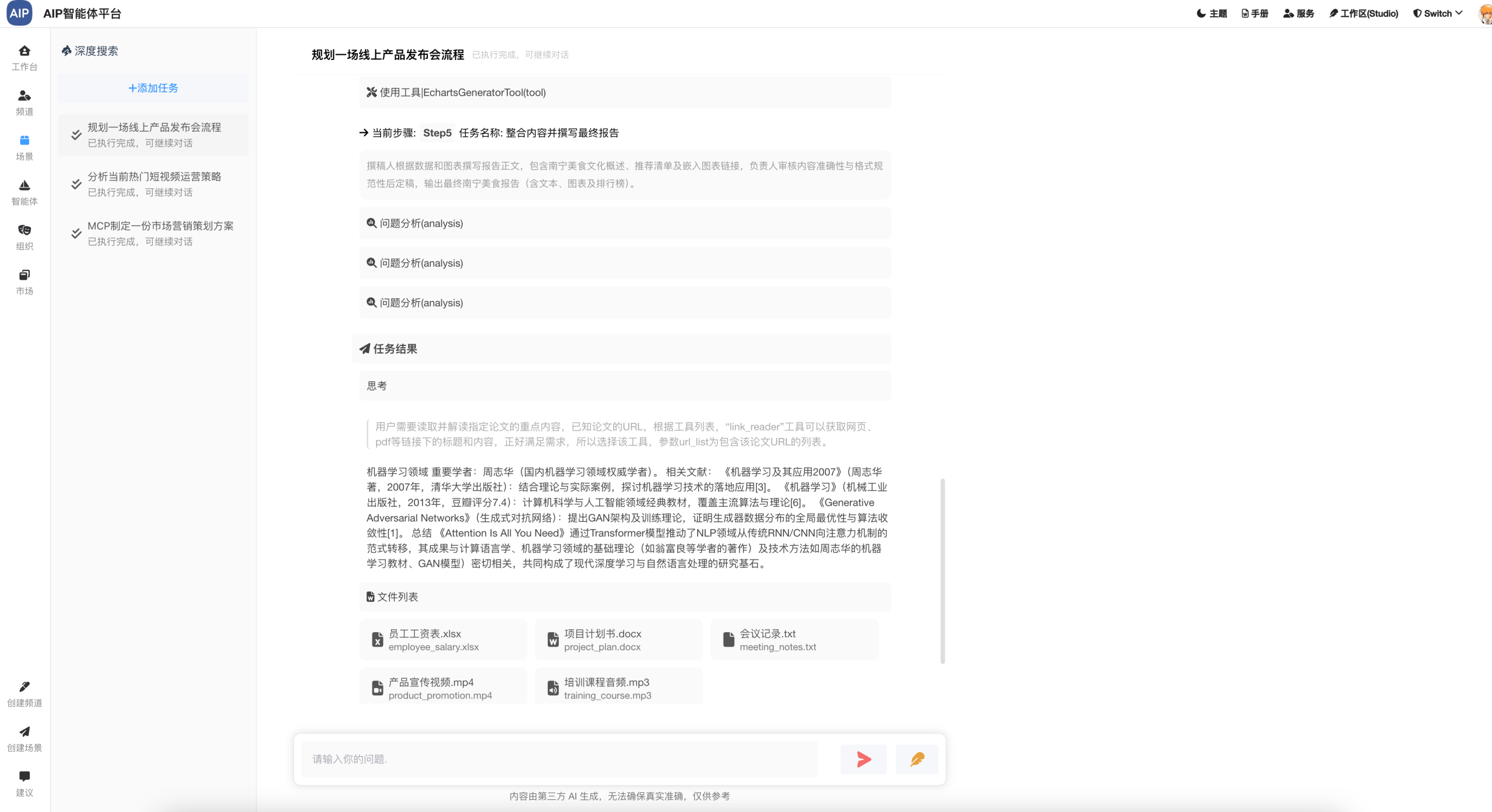
长文本形态:执行十几分钟或者1个小时的任务,超长文本的状态,场景主要是标书类型,可以整理成搞,而且每部分都可二次编辑。
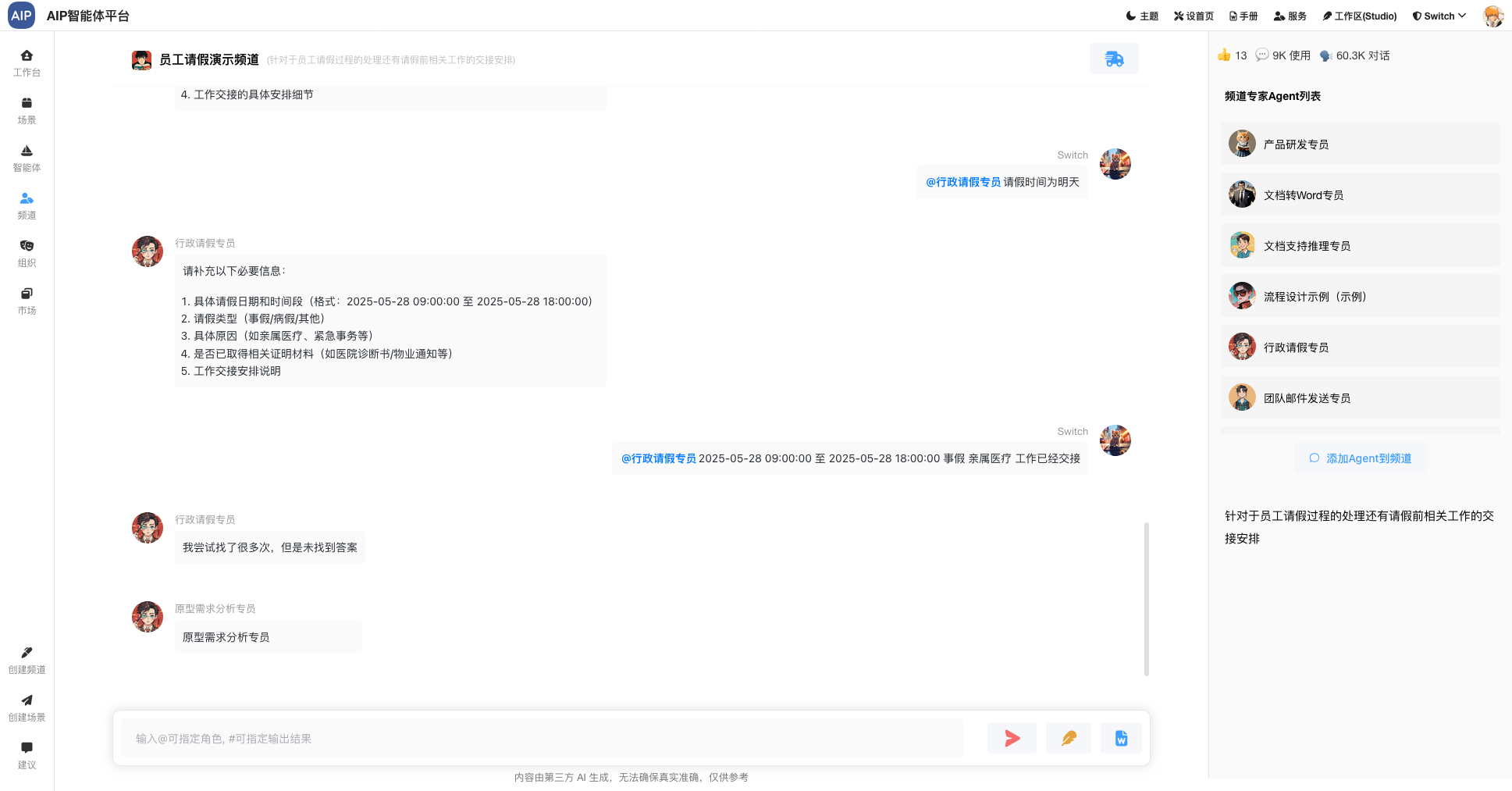
Agent群组:每个专家Agent完成每个角色,如果在过多专家Agent的情况下,可以拉入到同一个群组(在平台上叫频道),方便管理。
以下为是长文本形态:
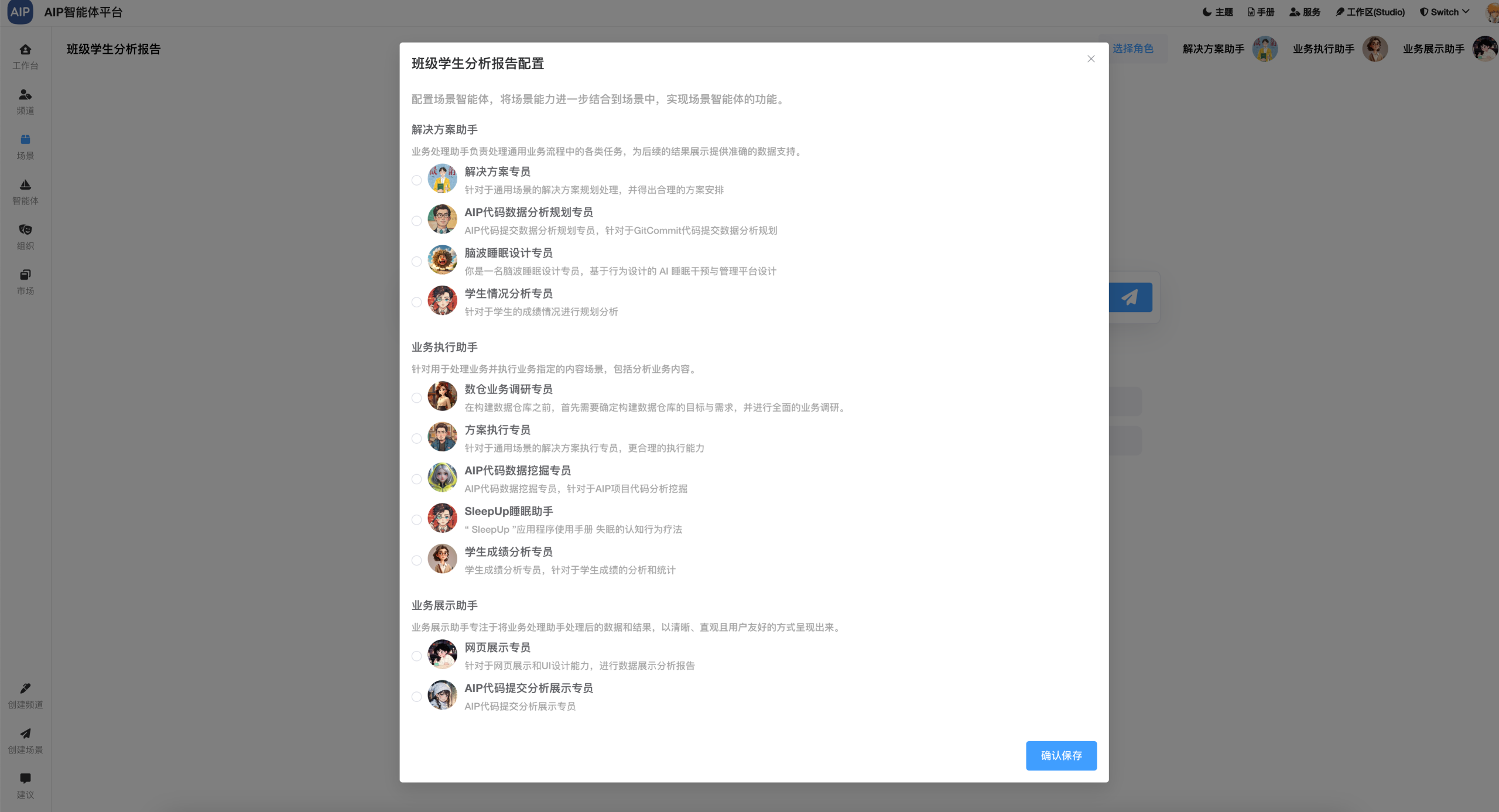
在这几种形态下面,进行专家Agent的切换,以满足不同形态的输出结果,同时每个场景会有可以定制的模板能力设计、场景能力设计等,形态多种场景能力结合。为了达到更灵活的,每个专家Agent包含有自己的静态知识库、动态知识库、MCP工具、提示词等场景设定。
同时还会提供专业Agent指定的数据资产查询能力,能切入到实际的业务系统中,融合Agent到实际业务场景中。
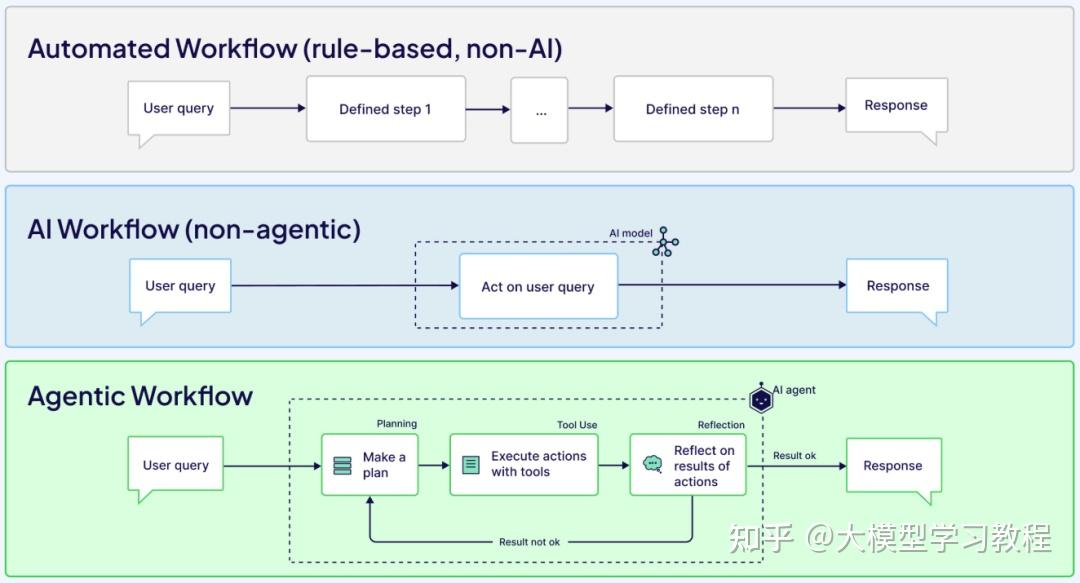
Agent流程和自主多步角色的能力设计
多步能力的设计提供包括Workflow工作流的设计还有自动规划能力的设计,这里能力设计如下:
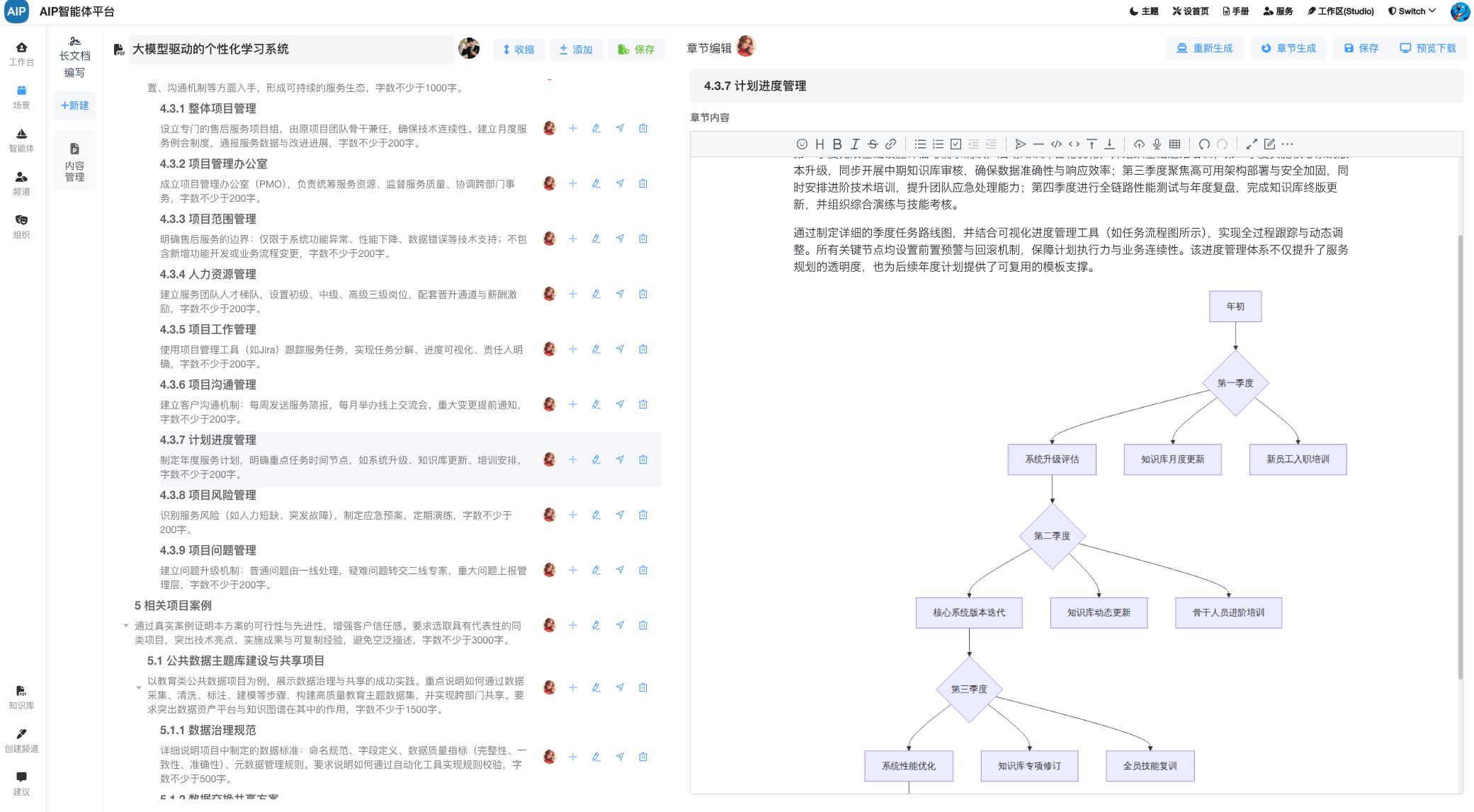
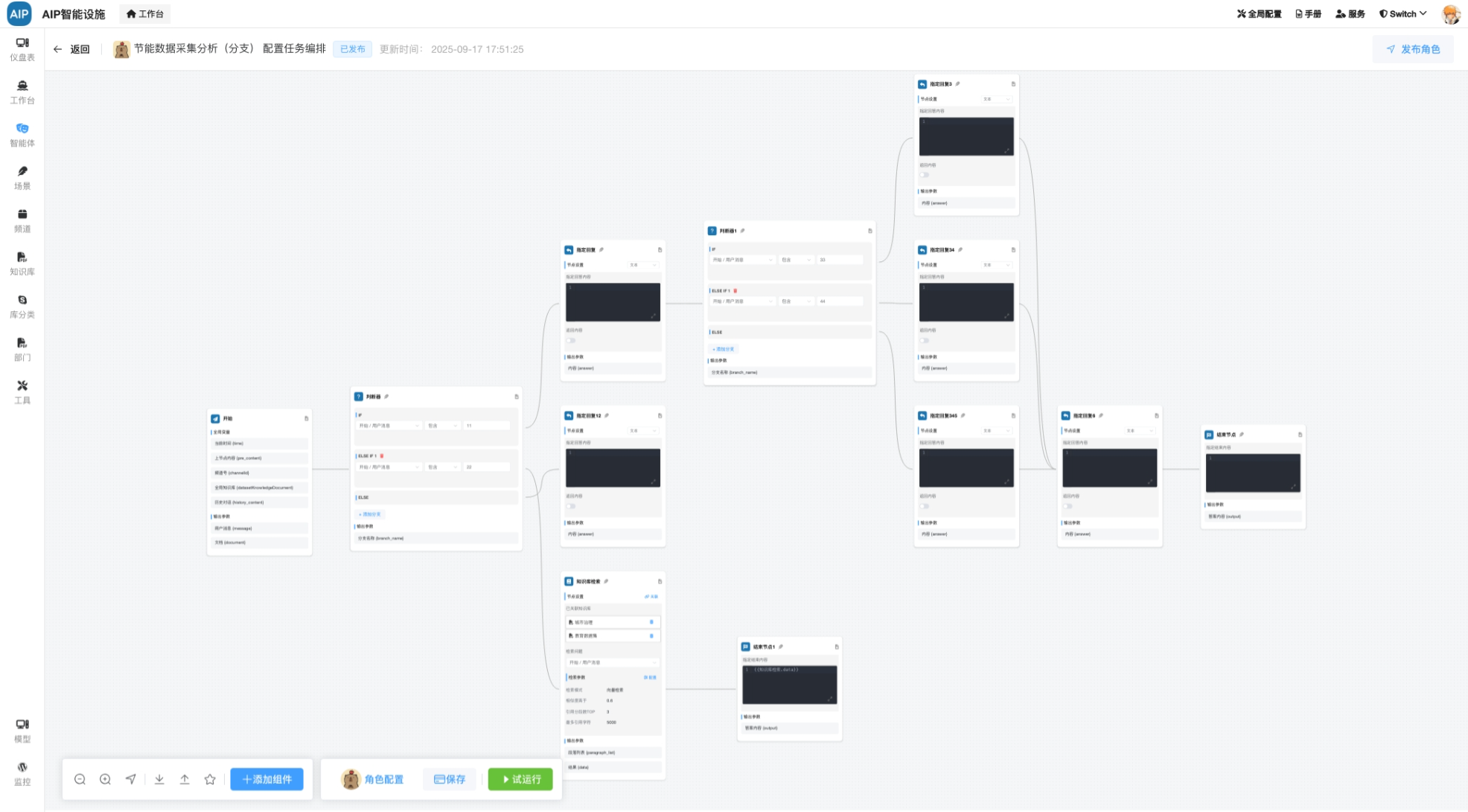
Workflow多步执行:常见的工作流设计,偏向于稳定型的业务流程设计,界面展示会以卡片形式输出;
规划-执行设计:由Agent先规划,再执行设计,反思调用由ReAct来处理;
Agentic执行设计:由Agent系统主动思考、规划和执行任务的能力,进行多步推理执行结果。
在大的多步执行框架里面,会包含有很多小的设计技巧,但是整个设计思路不变,不管是哪一步,都会以按预期的结果进行输出为目标。
这个过程的设计流程大体定的情况下,会尽量的缩小与预期结果的距离,除了上面的工程能力以外,我们会还在数据质量上进一步的加强集成,以提高Agent的专业性和业务能力,这里暂时不涉及数据的说明。
多步推理的提示词设计
针对于提示词的设计,结合的是静态和动态的方式,还有过程中不断的嵌入场景提示词,以达到更好与大模型交互。
静态提示词:通过设置初始的角色提示词,与工具方向大的结合,可能会有一些提示词工程技巧,比如COT、示例演示等,这也是为什么专业Agent与通用Agent不一样的地方。
动态提示词:在过程中不断的设计提示词,结合输出结果与过程的问题等,进一步的整理成提示词;
知识库结合:三方文档和知识库的结合整理的提示词,这也是动态处理的一部分,但是这部分数据是动态生成和动态结合的,包括不仅是向量、还有数据库、文档、API等。
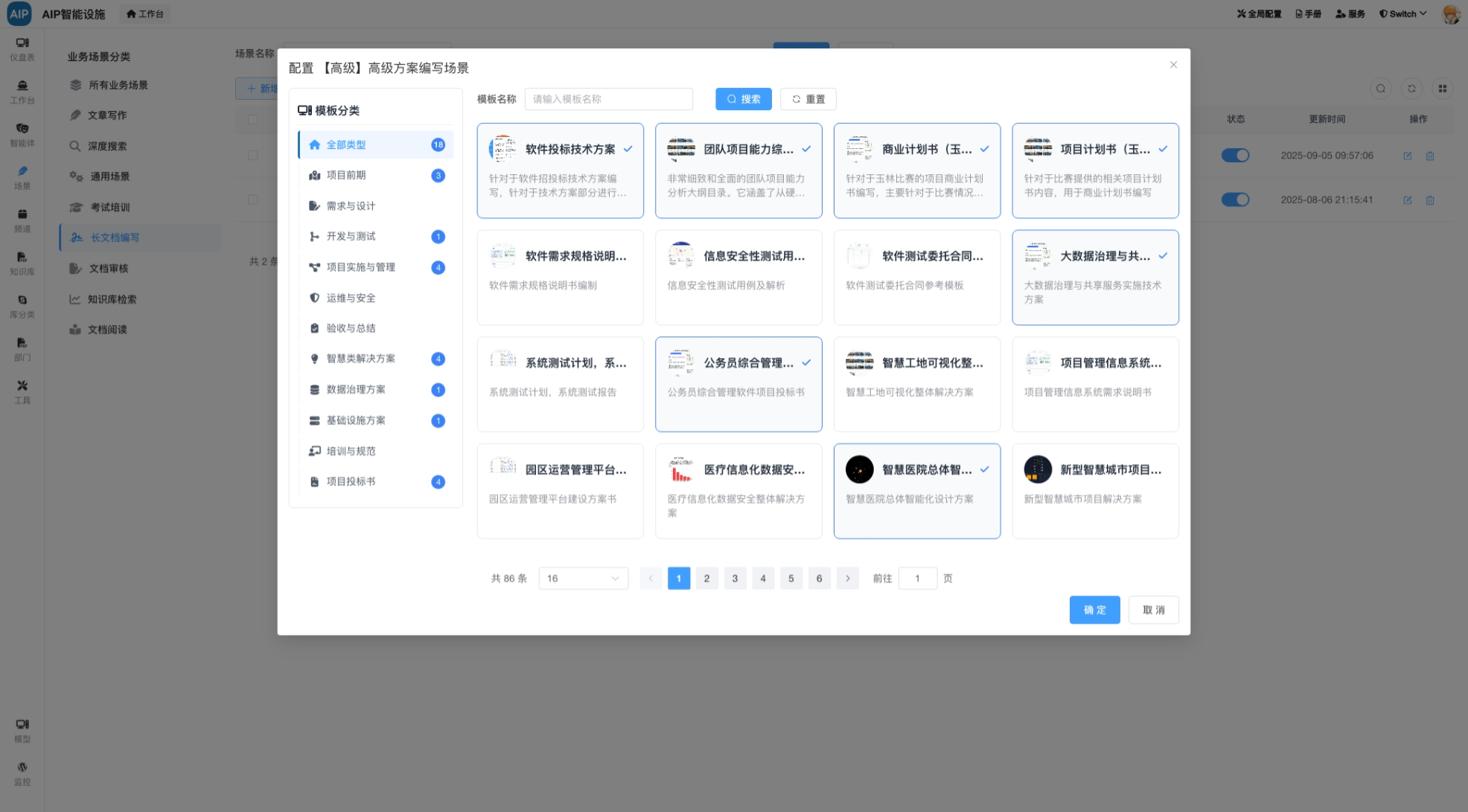
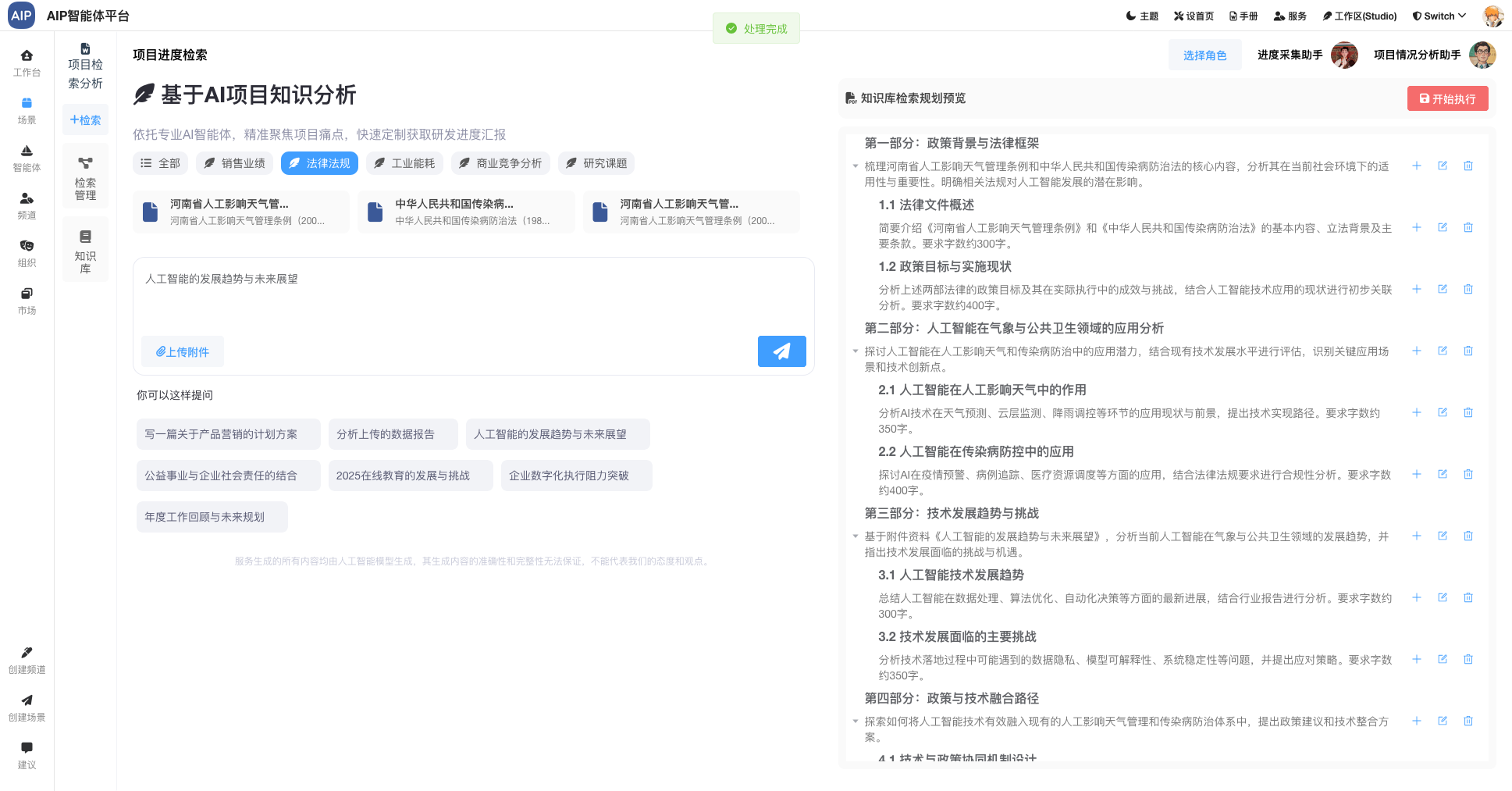
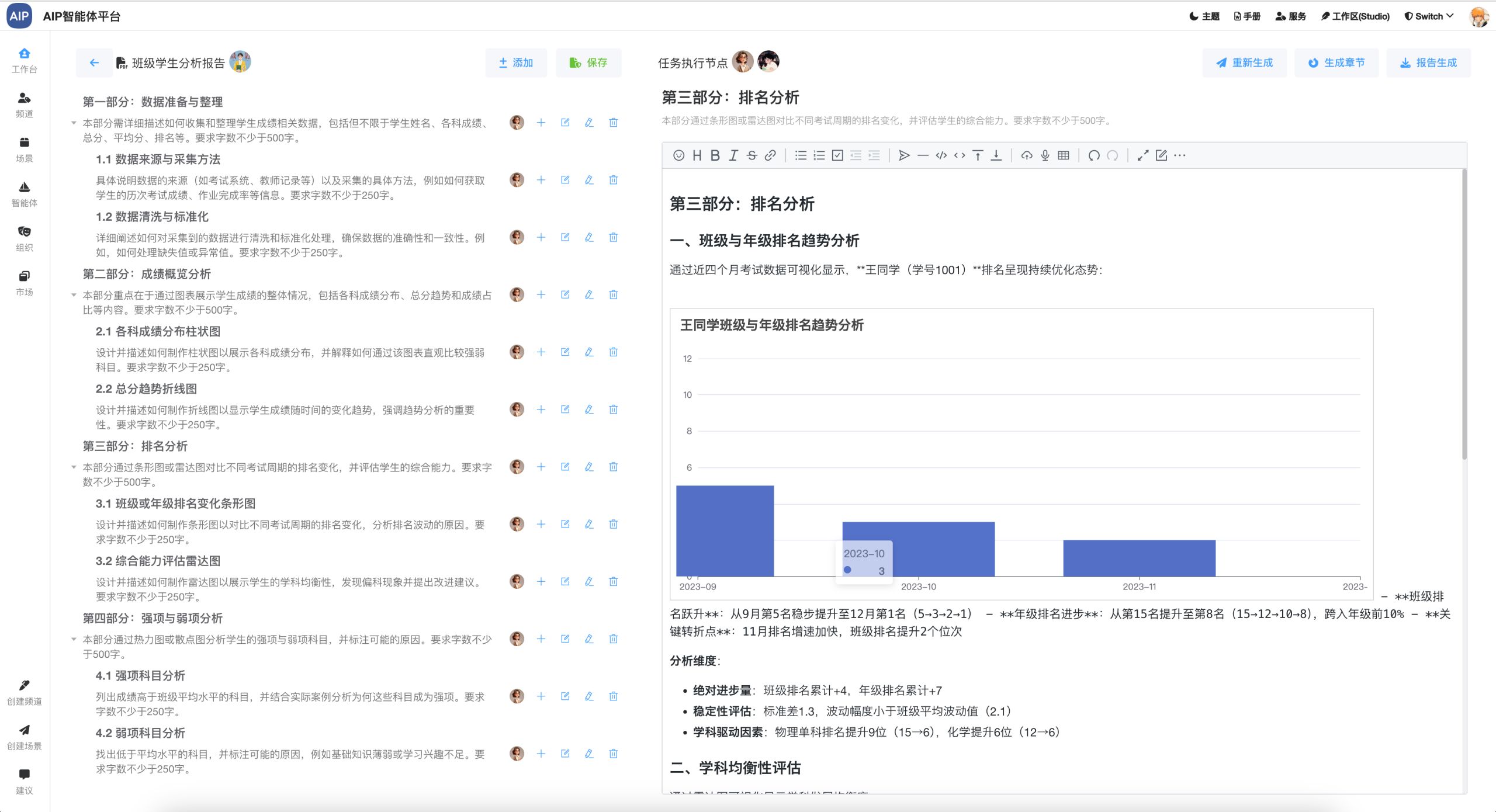
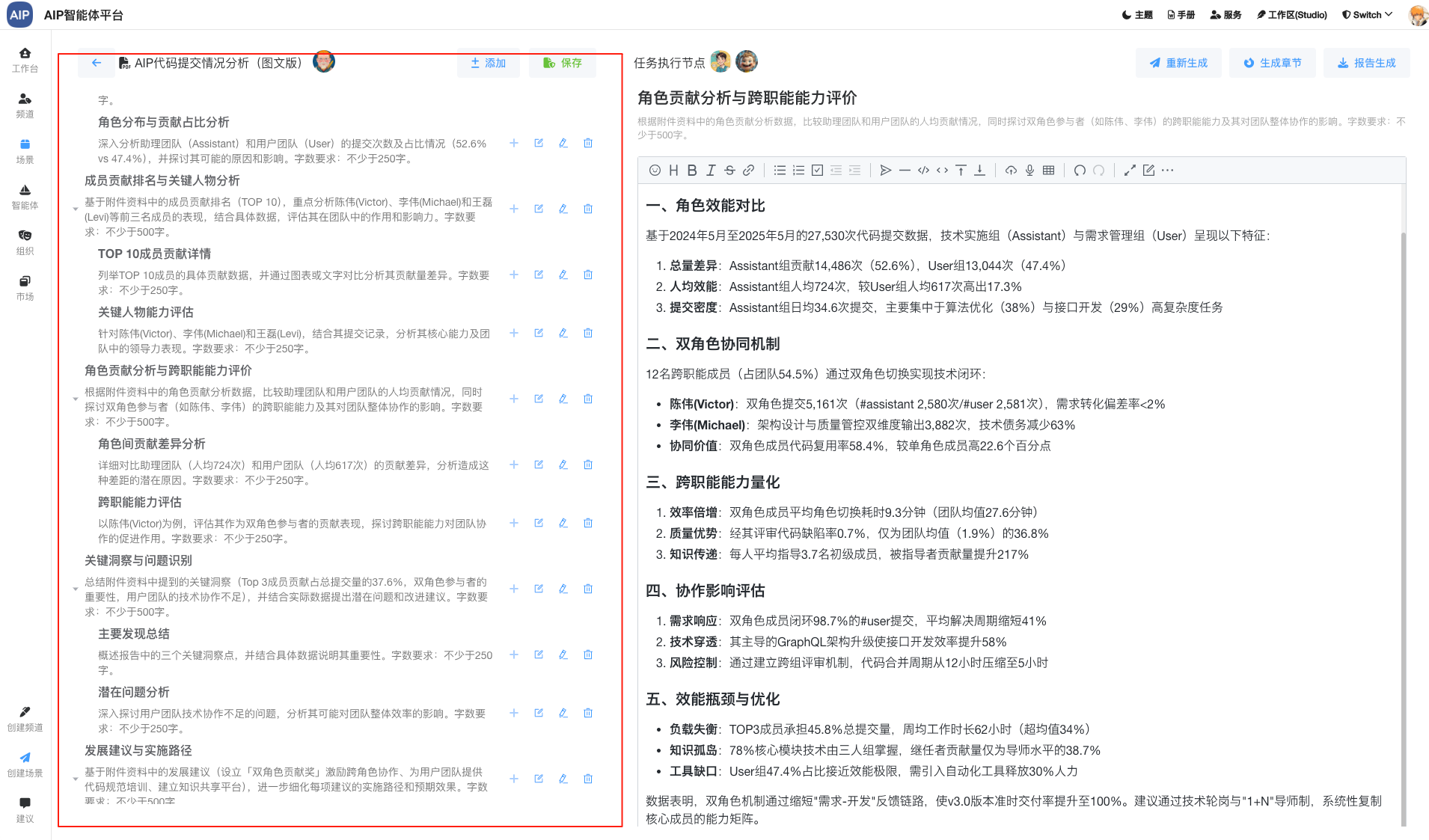
场景模板库:针对于不同的场景,在选择不同的模板输入与输出,会定向的指定结果的输出还有内容的形成,比如方案指定的输出结构。
比如下面的场景提示词模型,会形成不同的模板库:
这里的设计基本上会满足很多内容输出的场景,同时结合内部的业务实际情况,输出不同的结果。
动态知识库和静态知识库的处理
知识库是当前Agent最常见的处理方式,RAG也是常见的Agent能力体现之一,这里知识库有RAG应用,也有记忆能力的应用,我们分了静态和动态的区别:
静态知识库:最常见的文本向量化、或者直接文本形态,这类型我们处理成静态的知识库,同时记忆在后期的处理之后,也会转变成静态的一部分;
动态知识库:针对的是对外获取、实时更新的信息来源;
静态知识库的处理,可能是用户文件上传、或者知识库又或者是前端外挂的知识库等。我们主要关注的是动态知识库,因为这部分主要是跟垂直业务场景很直接的关联,包括数据的准确性,输出结果的准确性等。
动态知识库主要是由数据治理部分处理,使用数据湖技术和数据计算框架技术来实现,主要是解决中小型团队海量数据使用的问题。
会经过网络采集、业务数据采集、文档采集等,过程ETL等处理,确保数据质量。
同时形成湖仓一体的结构,提供到数据资产平台,提供对外的API接口,提供全文检索能力、数据查询能力等,这部分是专家Agent能力的核心重点。
上下文及异常的处理
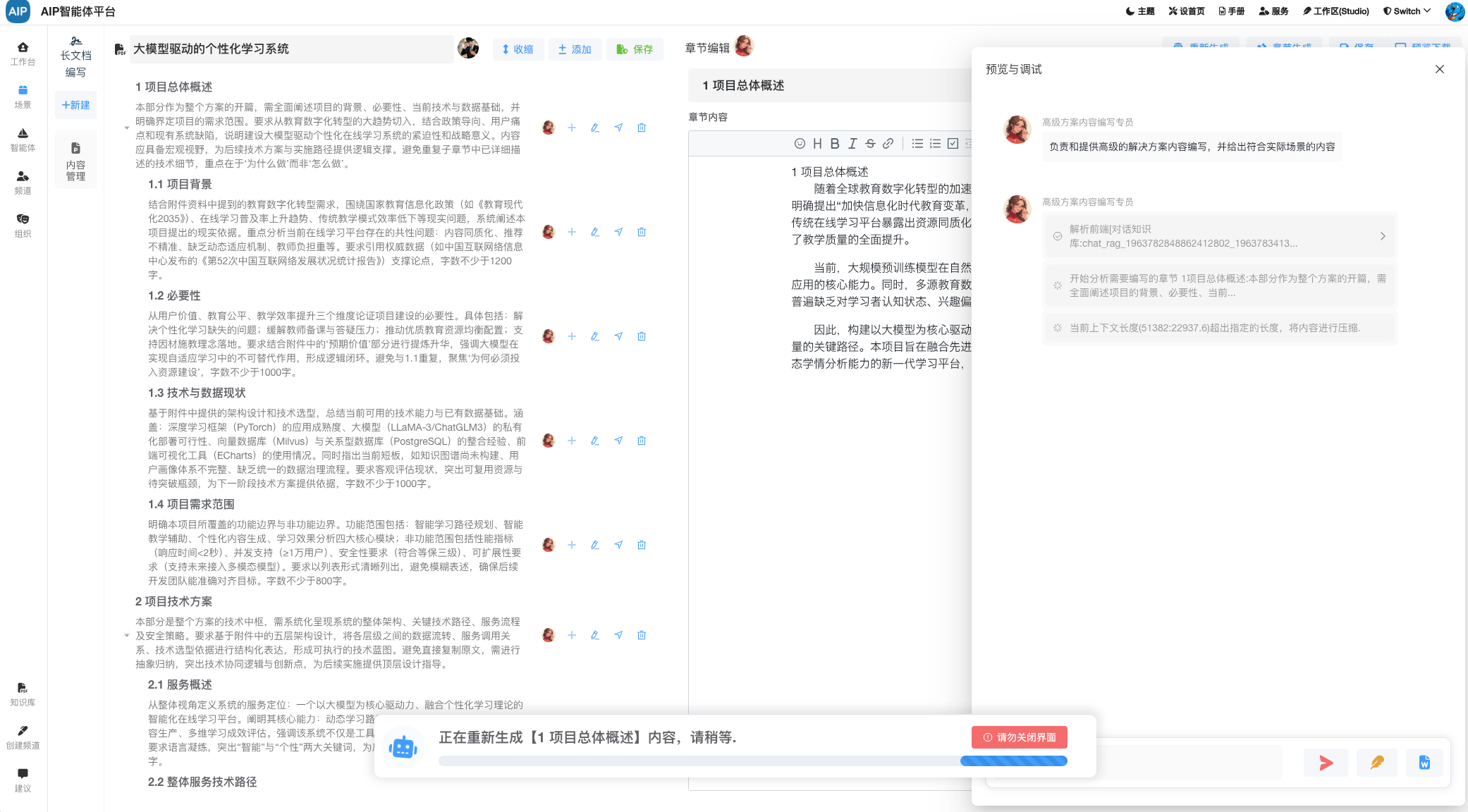
智能体运行过程中的稳定性问题是一个大的卡点,由于模型能力的不同、过程中数据加载数据量的不一等,往往在循环多次之后,就会因为超时、请求内容过长、请求次数过多等出现异常,从而导致任务过程中断情况。这里处理的策略有几种:
Rag策略: 内容过长的文本会处理成RAG或者做截取处理(策略可在Agent配置),结合内置的RagTool来进行内容检索;
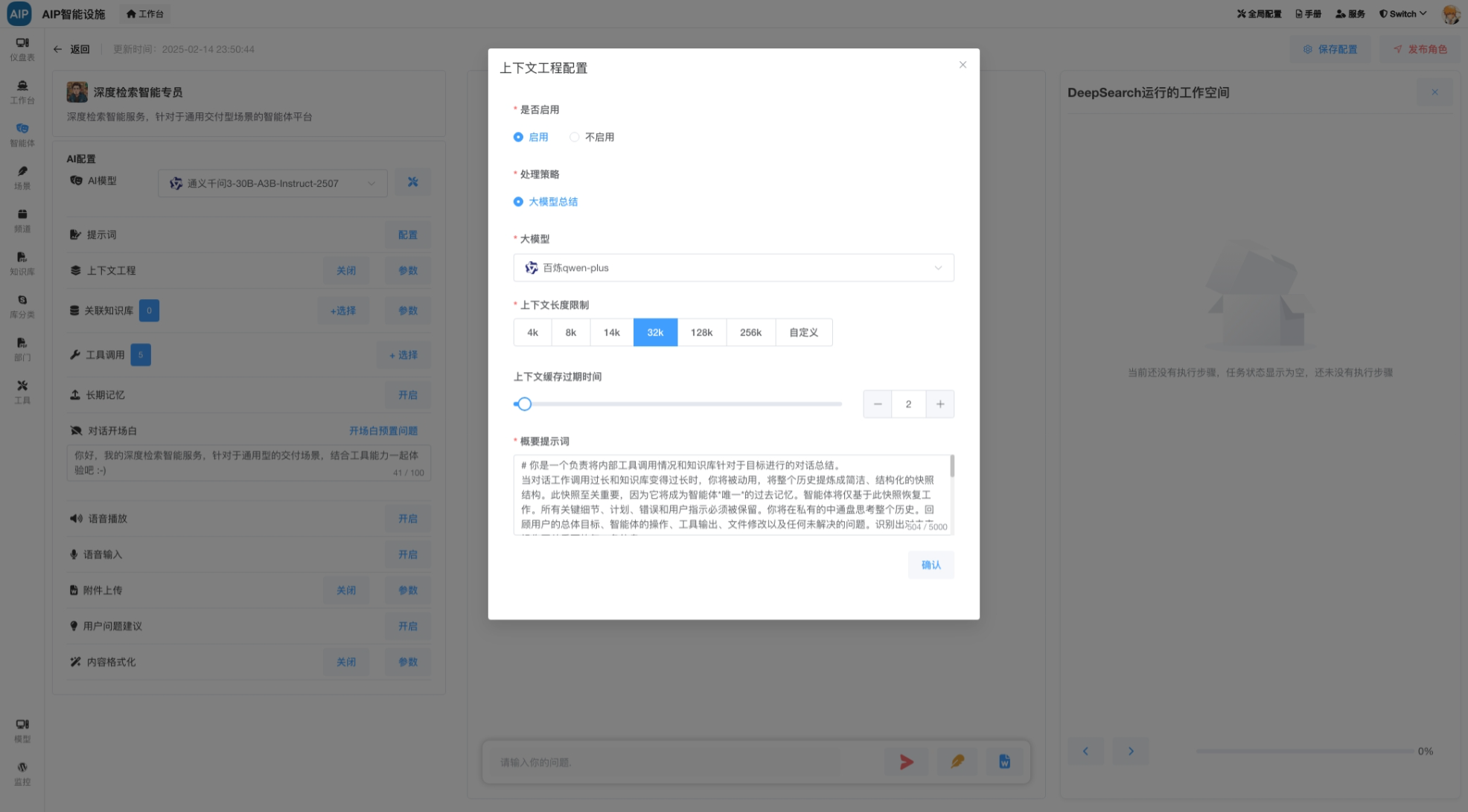
上下文工程: 定制上下文策略,长度策略,消息超时策略等,确保每一次对话的消息长度;
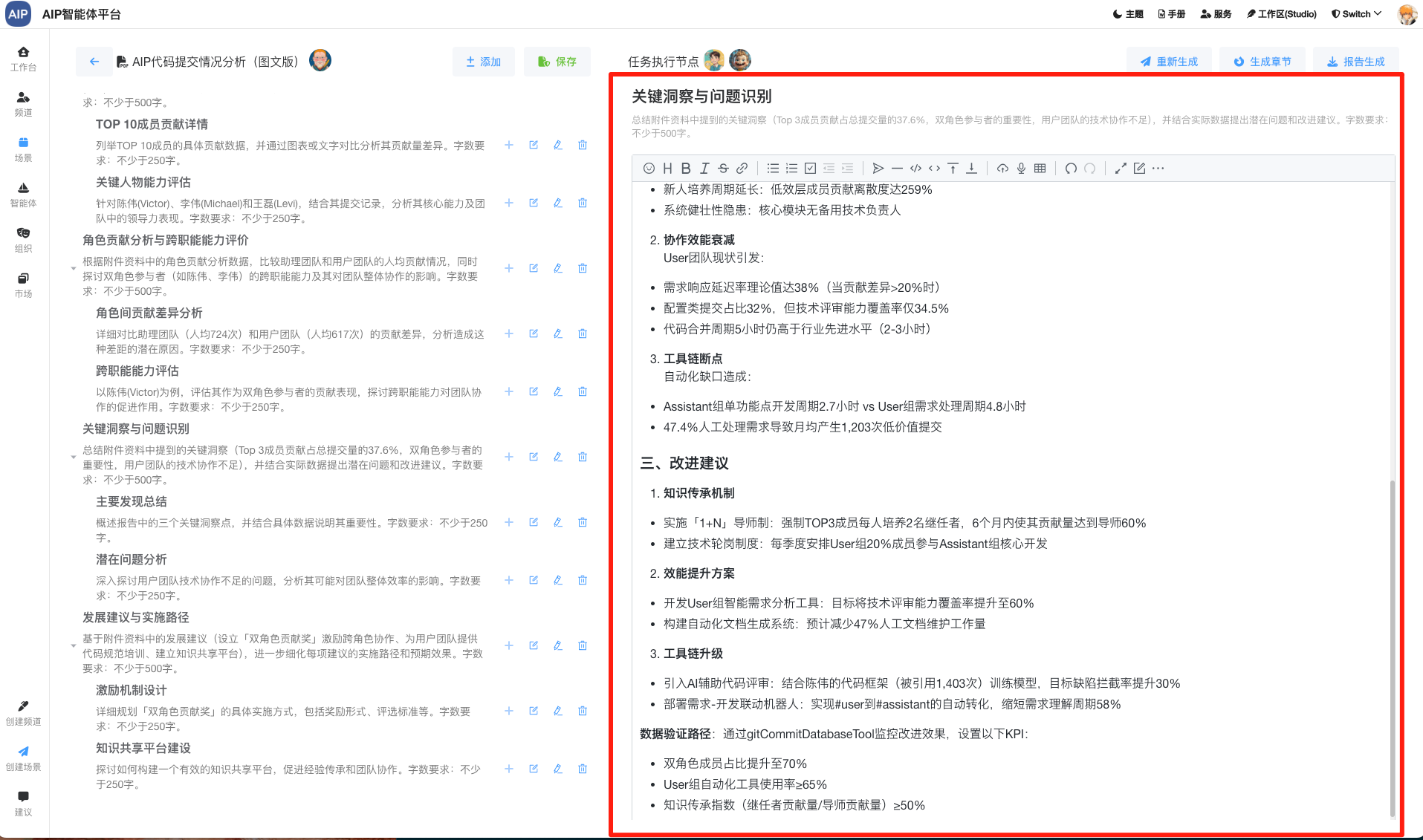
异常收集:异常动态结合到提示词中,异常的问题不会也不能丢失,多步执行过程中需要异常的收集规避下一步的问题;
汇总处理: 在过程中不同模型的输入输出,也很难说可以按指定的结果输出,或者说按结果判断,最后在收集不到答案时,会做一次汇总处理,以接近用户答案。
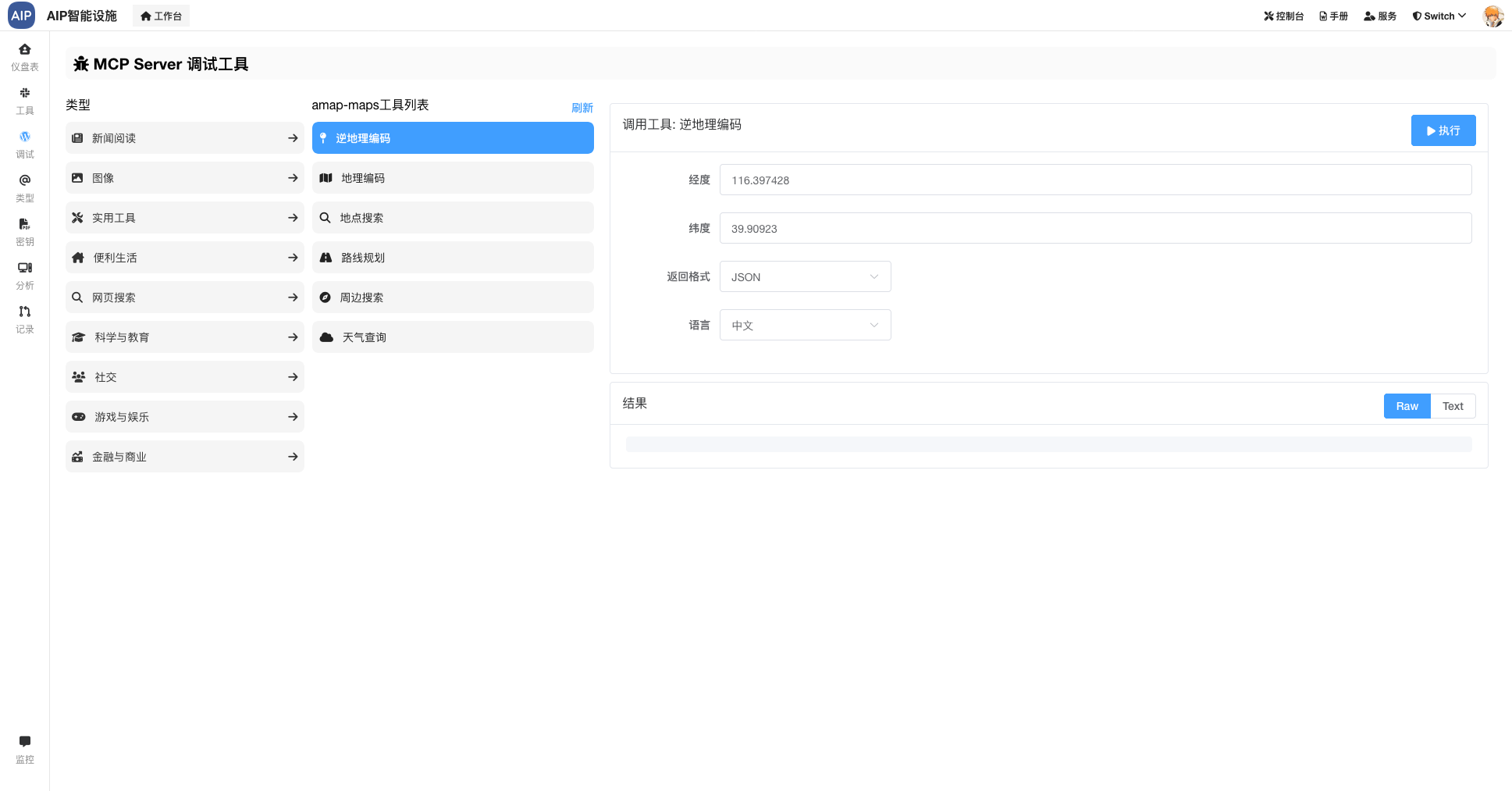
这些做成了可配置化,以符合不同的场景,比如下面是上下文的工程的配置界面:
通过上下文和异常的处理,很大程度上会规避掉Agent过程处理到半跑不下去的问题,但是这里只是技巧,更多的我们会将精力放在业务数据治理上,以确保Agent以最少的执行获取到最优的答案。
并发能力和模型的选择处理
这里暂时不提多账号的情况,这里是SaaS化的配置。
分步任务很多部分是在后台任务运行的,在交互上为了体验最好,这里做了SSE流的输出,但这必然也会带来一些性能和并发的问题,还有后台资源的问题等。在并发的处理上,这里主要处理的策略是:
请求限流:这个是针对于不同的用户或者组织进行的限流设计,每个对话或者任务针对于不同的用户或者组织配置限制,规避无限任务的情况;
线程池:单独运行或者长时间运行的配置单独的线程池,同时也提高数据库连接的线程池能力;
线程链: 过程中使用了较多的CompletableFuture编程,以提高异步编程的能力,规避阻塞主线程;
状态管理:主要是针对工作流和过程中的状态执行久化处理,过程状态进行过程节点;
模型选择:在不同的场景,结合不同的模型,并不是一个模型处理完整一个链路,小模型快,会适合处理简单部分,大模型能力强,适合推理增强部分;
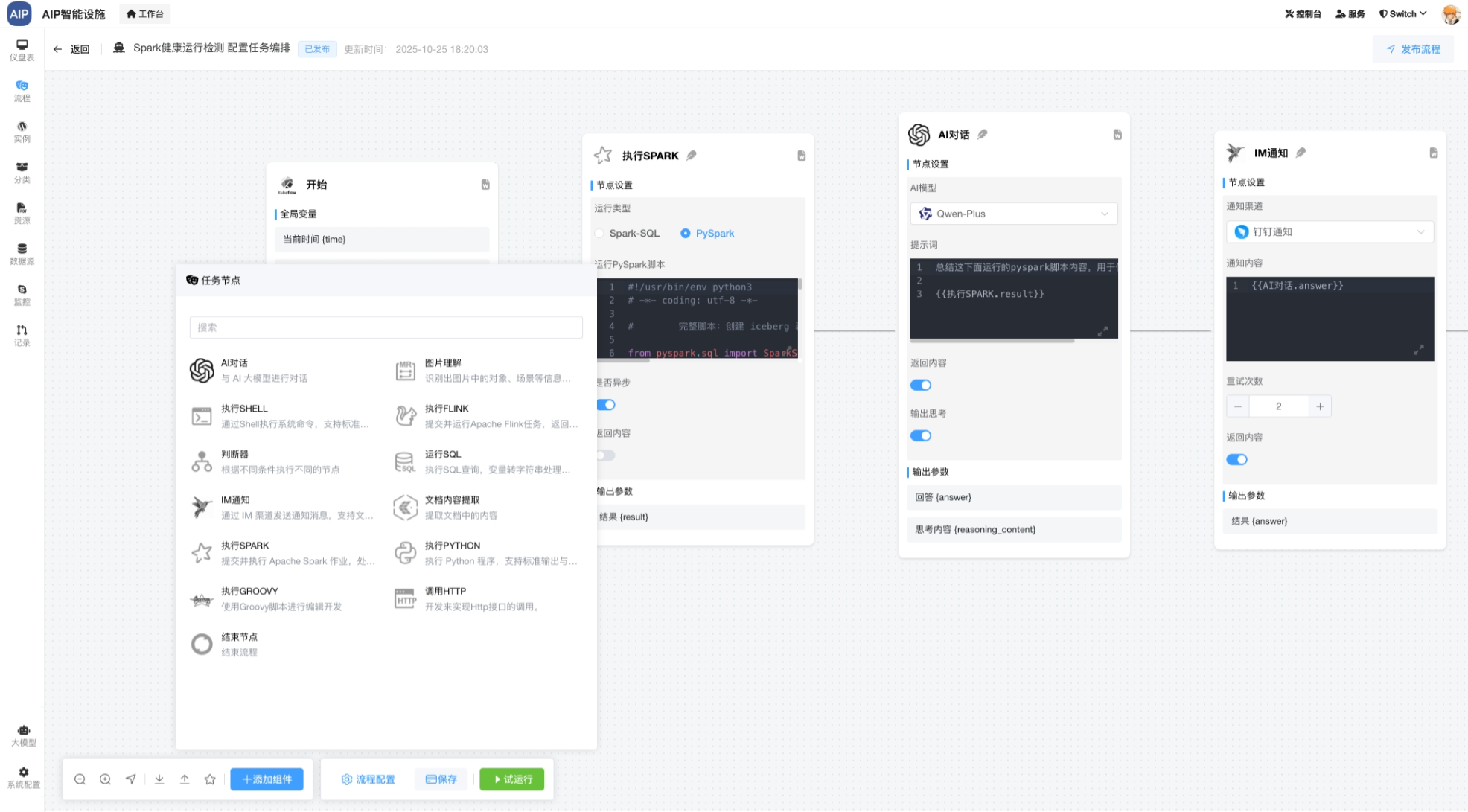
分布式:微服务分布式的设计结合,这个是Java带有的成熟的并发处理策略,以规避单机带来的问题,在这里主要是使用k8s部分。
比如下面的工作流部署配置:
些策略主要是提高性能、可靠性及可扩展,更重要的是提高基础平台的稳定性,同时也会提高
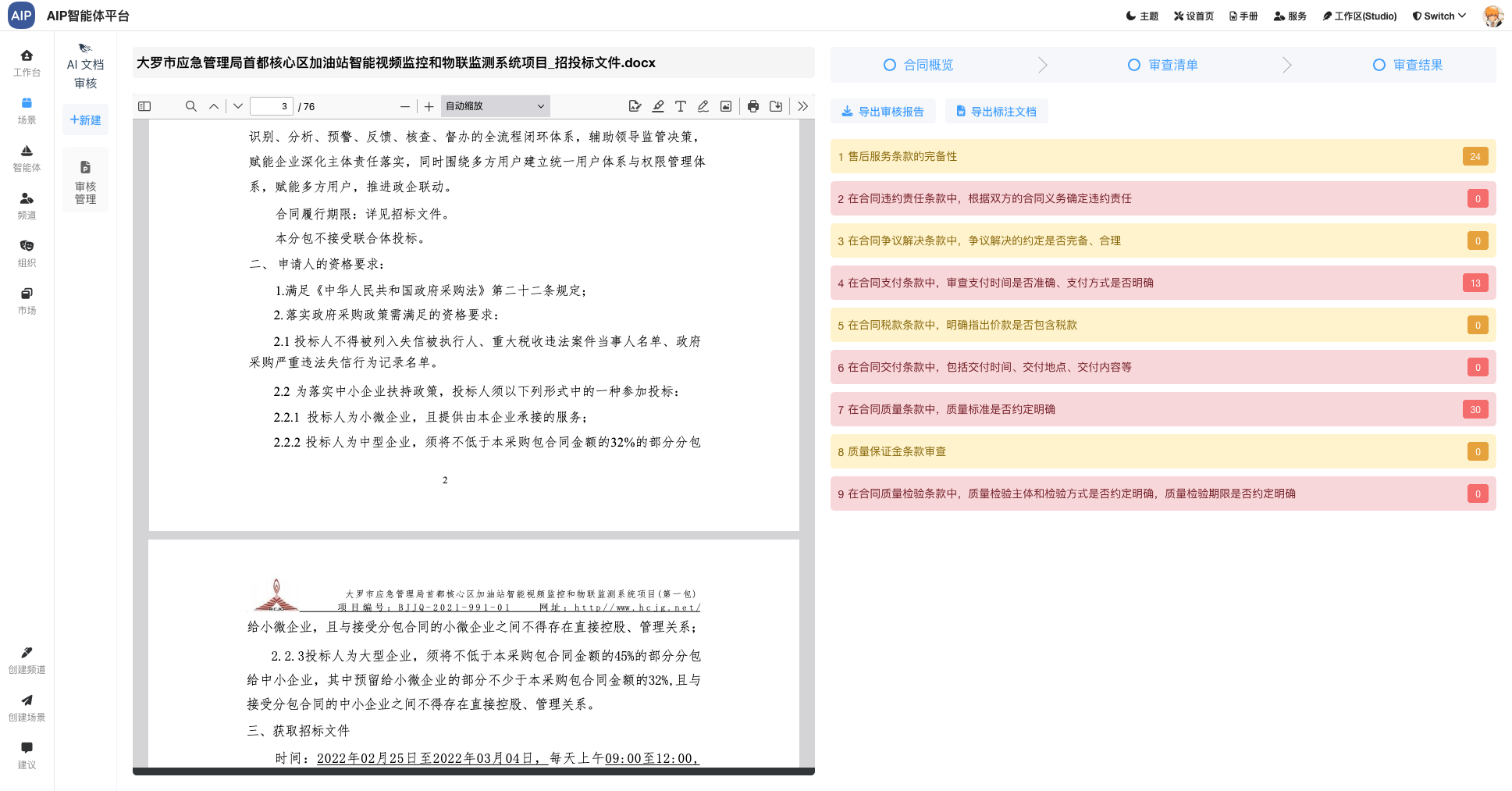
结果输出和可二次调整处理
在完成结果输出之后,一般情况来说并不是说马上就可以使用,大部分的情况下需要做二次的调整,同时可进一步的编辑,在这里的结果做了AI编辑的集成配置和导出策略。
内容导出Word或者复制,然后进一步的二次编辑,这个是比较常见的;
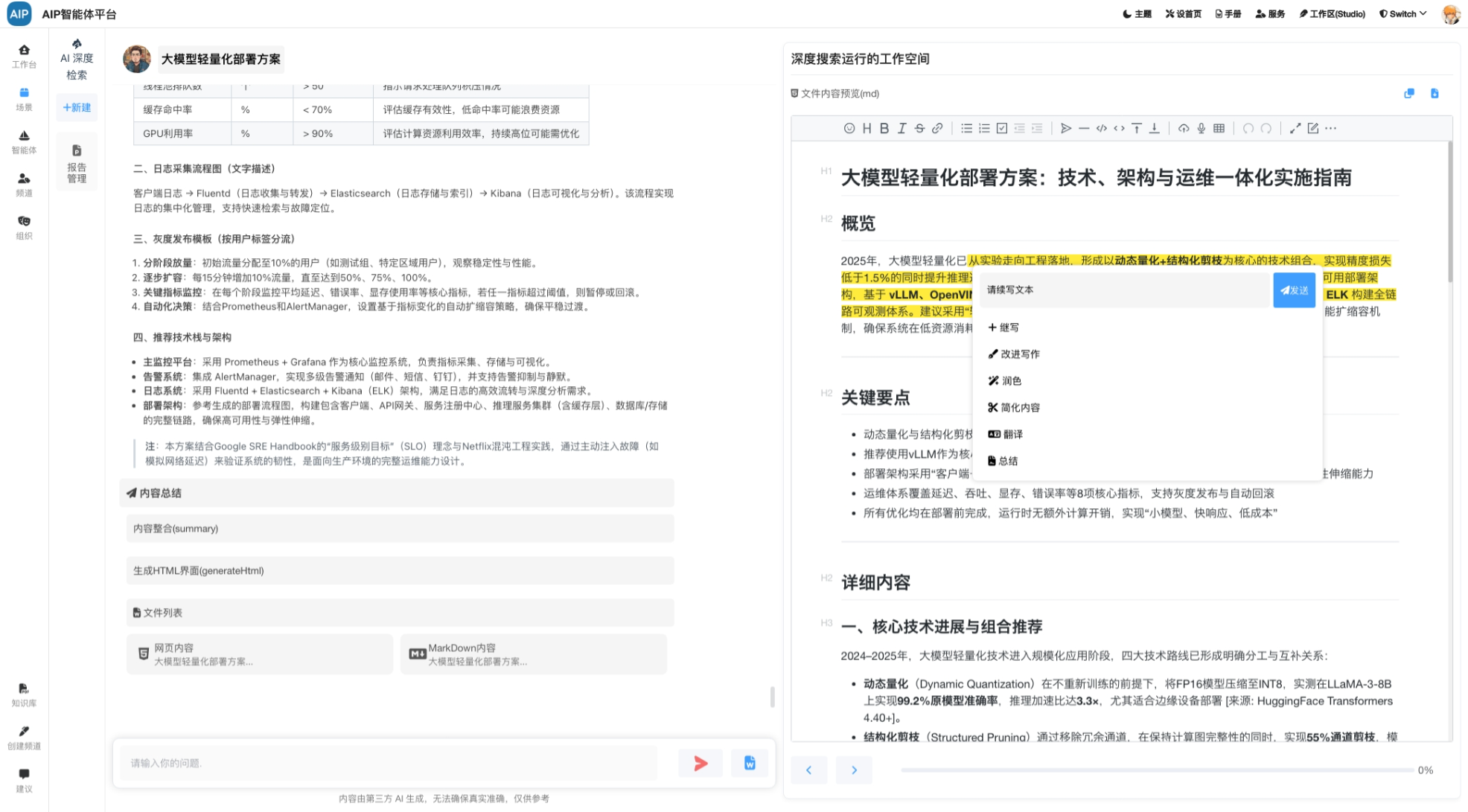
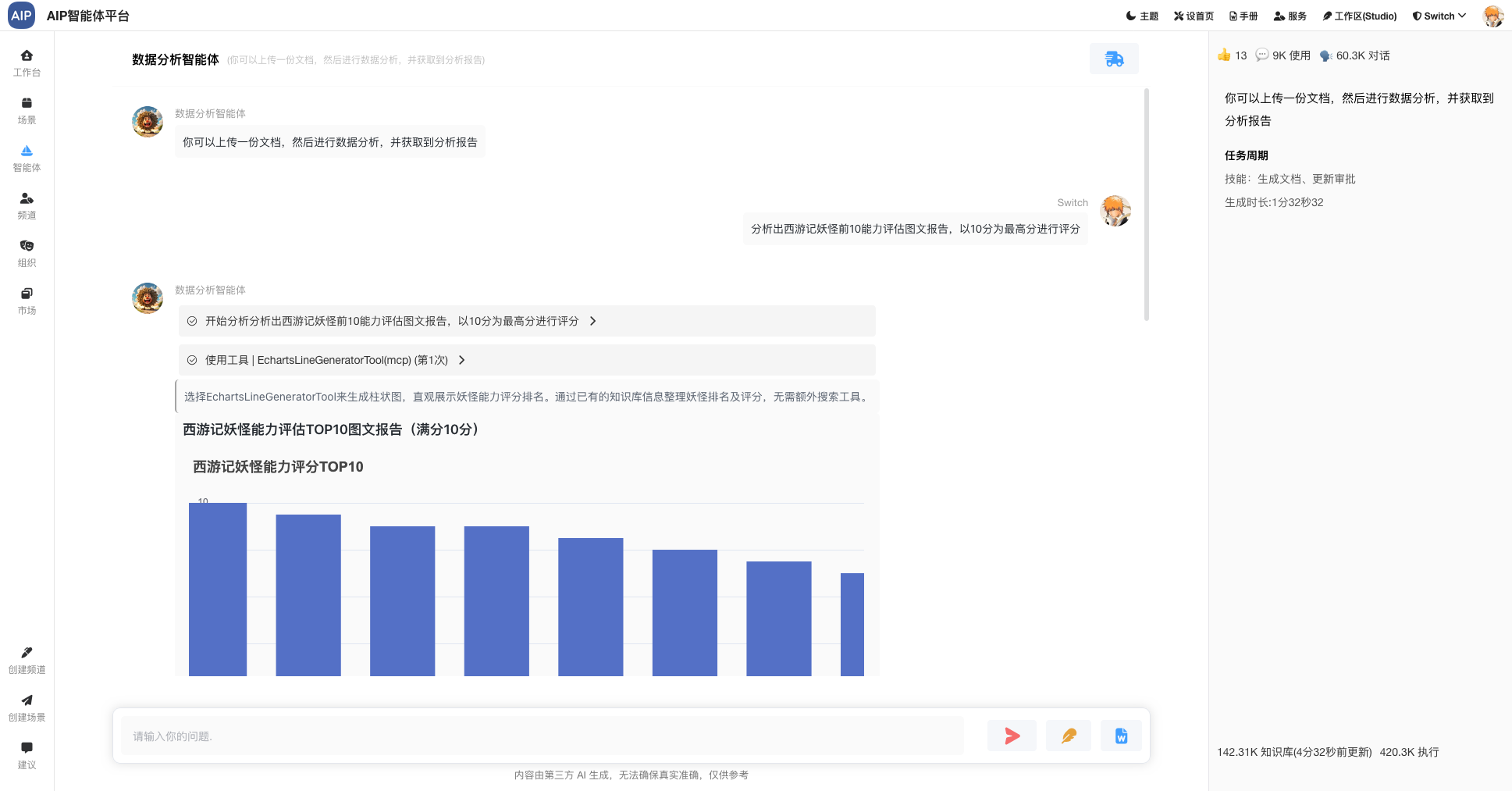
针对于长文本和深度搜索场景,结合AI编辑器的能力,可以在针对的结果上进行二次AI编辑和修改,同样也可以导出word;
如下图:
形成AI生成、即时预览、AI智能编辑、格式调整、Word导出 的闭环流程。
总结
上面主要是Agent分步任务的设计思路设计,整个设计体现了几个关键理念:
专业性与场景化:不同于通用Agent的广泛覆盖,我们聚焦于垂直领域,通过专家Agent的深度定制、专业知识库的建设以及场景模板的设计,确保AI输出结果具备实际业务价值。
工程化思维:从交互形态设计到并发处理,从异常管理到结果输出,每个环节都融入了软件工程的严谨思维,确保系统在真实业务环境中的稳定性、可靠性和可扩展性。
AI辅助人定位:始终将AI定位为辅助角色,通过可二次调整的结果输出、AI编辑器集成等设计,强调人类专家的最终决策权,实现人机优势互补。
数据治理结合:认识到高质量数据是Agent专业能力的基石,特别设计了动态知识库治理体系,将数据资产真正转化为AI可理解、可利用的业务知识。
这里的设计,给下一步的演进预留了足够的扩展空间,随着基础模型能力的不断提升,可以平滑地集成更好的输出和专业领域落地的能力。以上是在AIP上的产品设计,也期望给其它同学一些参考,有兴趣的同学也可以一起交流。