软件工程师罗小东,多年架构和平台设计经验,目前在研究平台与新技术结合中。
术语
- 频道:多Agent结合交互,类似群,可以拉Agent进入
- 场景:针对特定要求的多Agent编排,目前集成大文本、管理Agent
概述
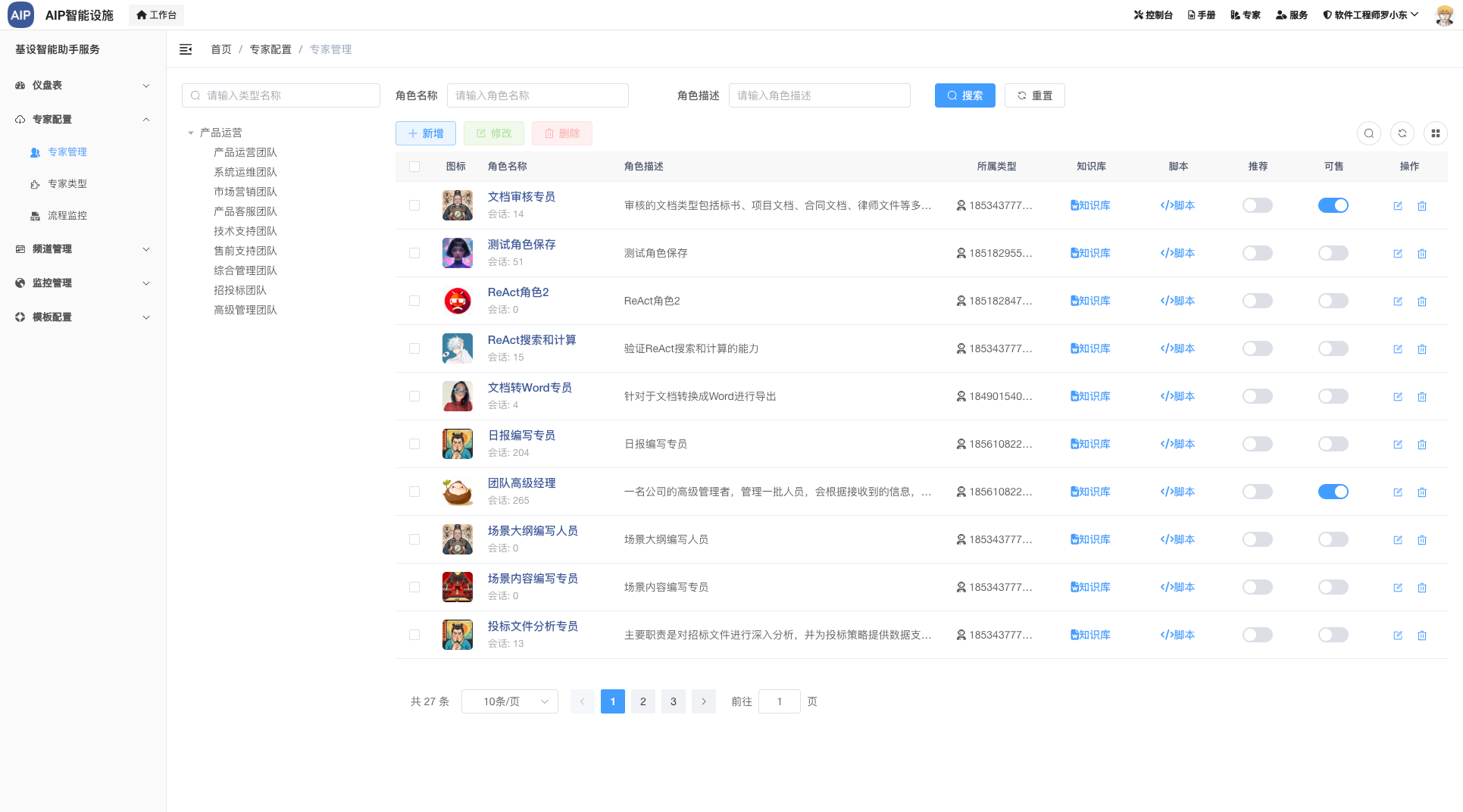
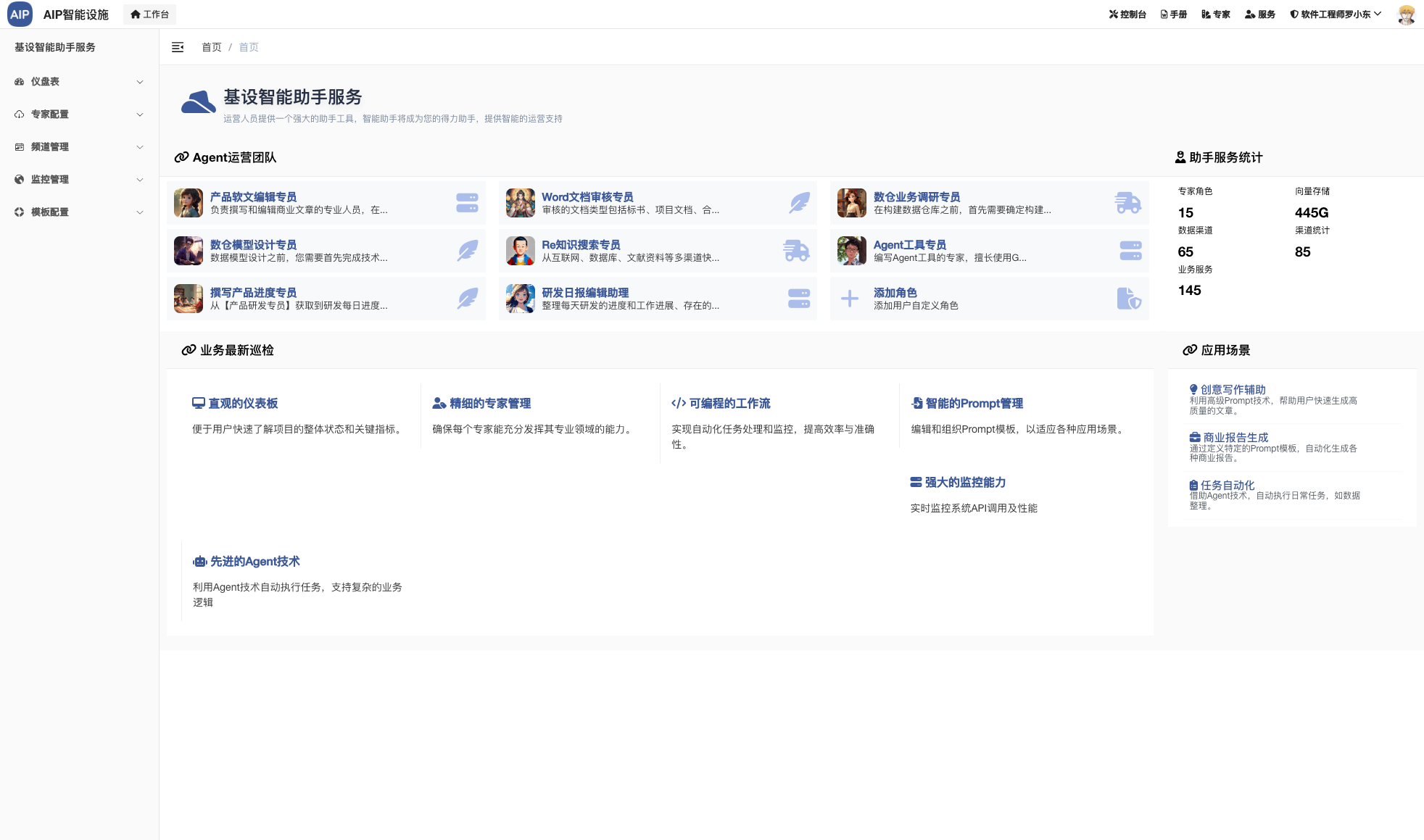
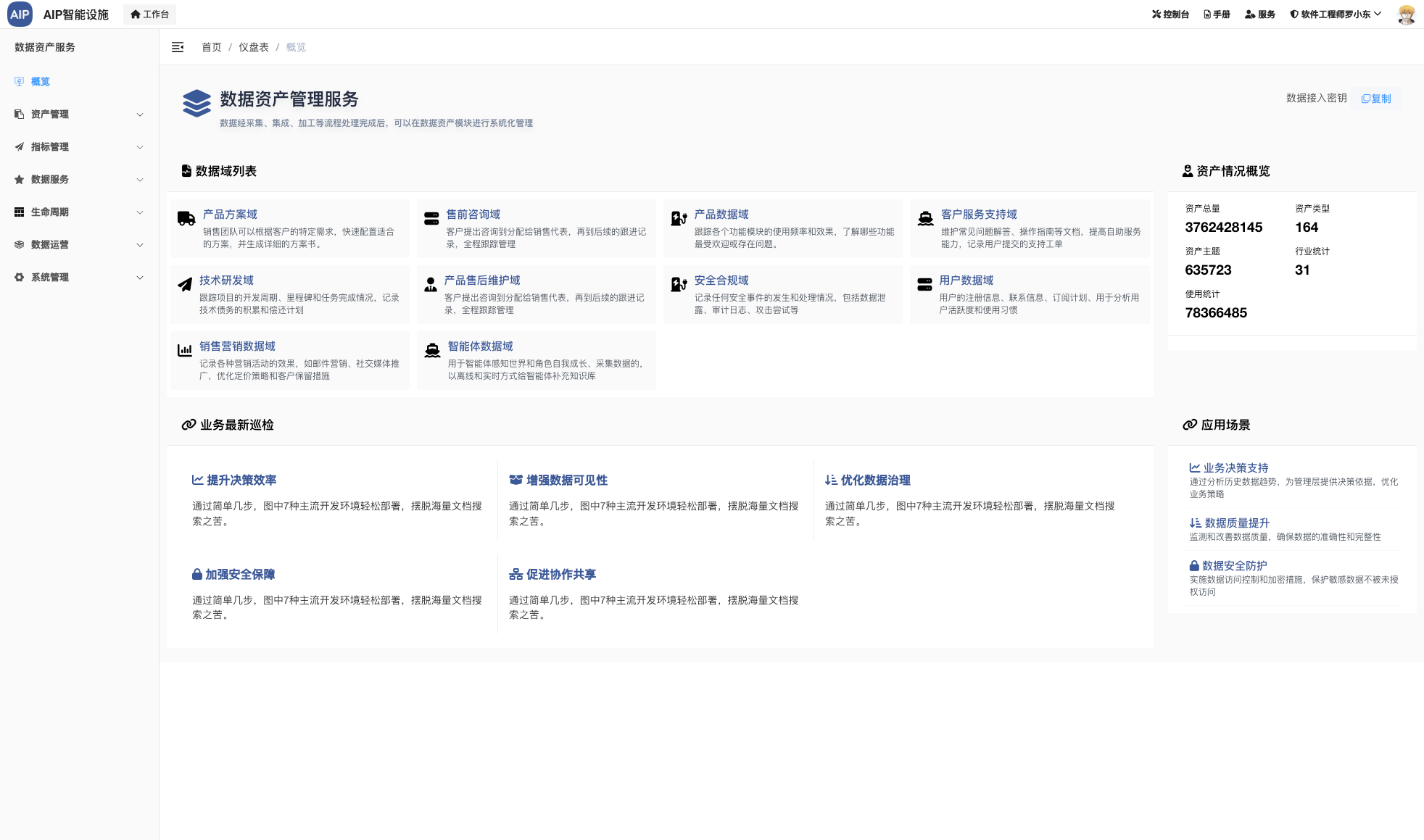
针对于AIP的输出整合情况,AIP是目前在维护的开源项目,主要是进行平台和新技术的结合上,同时对外的交流方式之一。

智能体输出场景有很多,这里主要针对的是工作场景还有多Agent交互的情况,目前AIP集成相对常用的业务场景。
抛砖引玉,一家设计,同时也期望有兴趣的同学可以了解和交流,我有我思。
集成场景
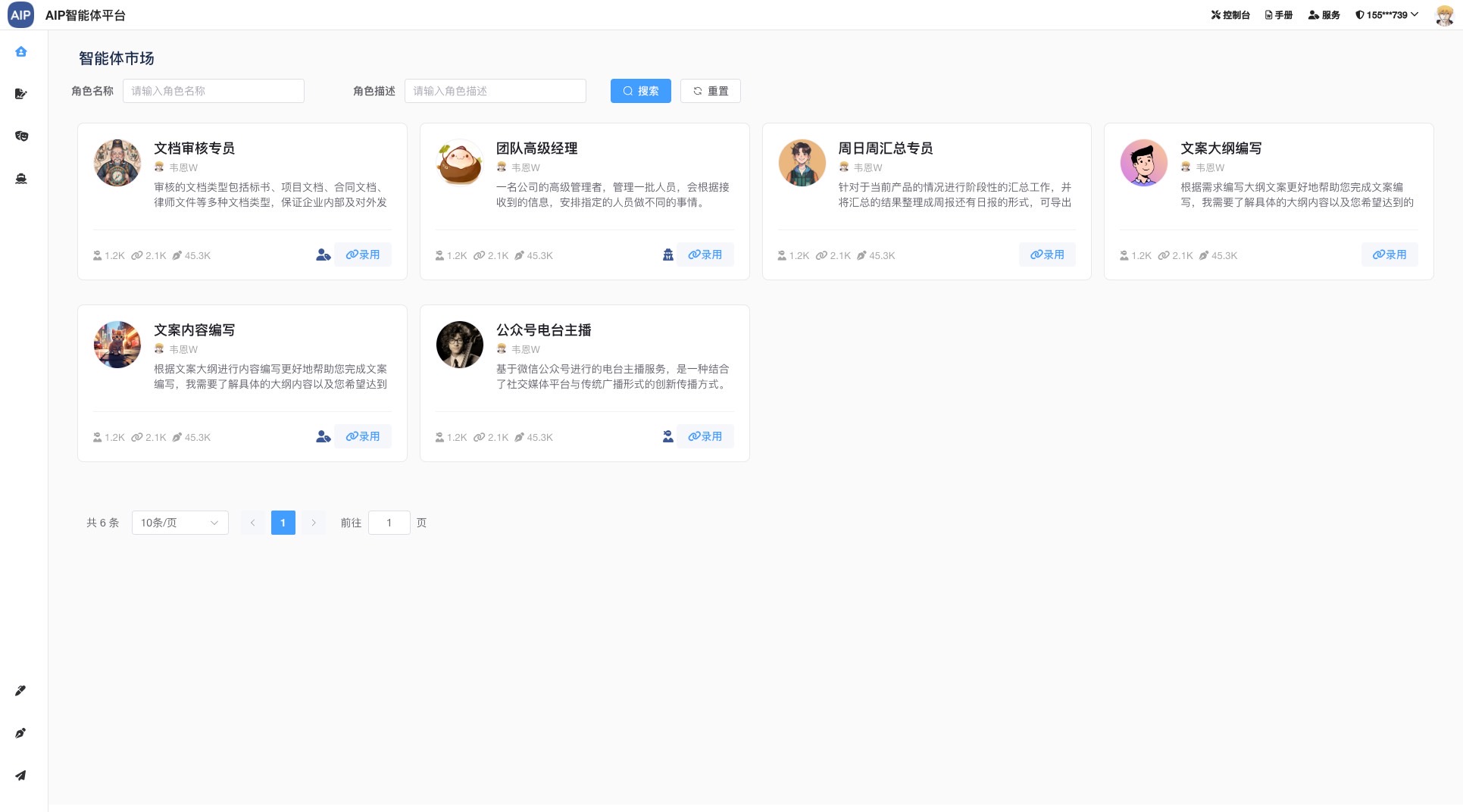
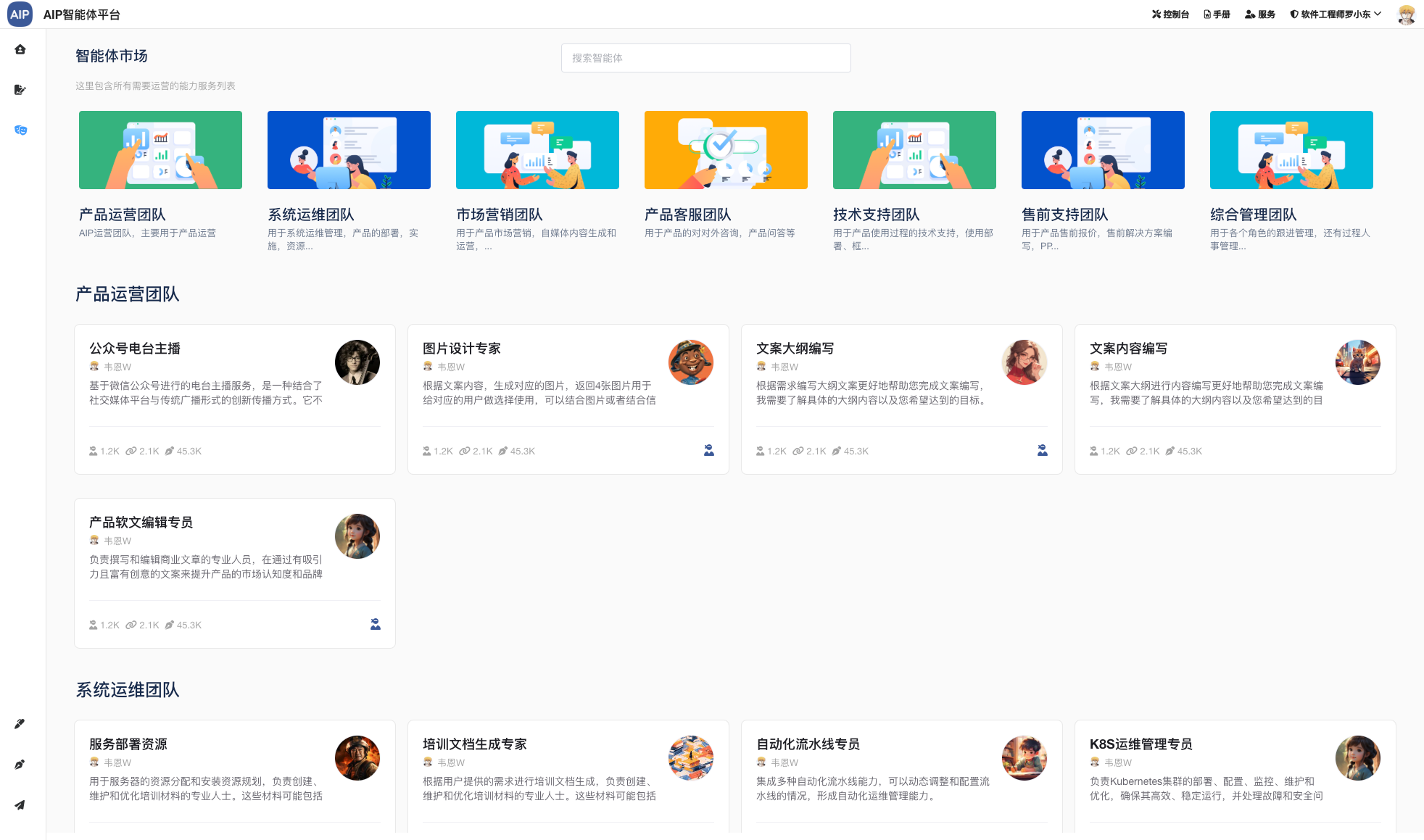
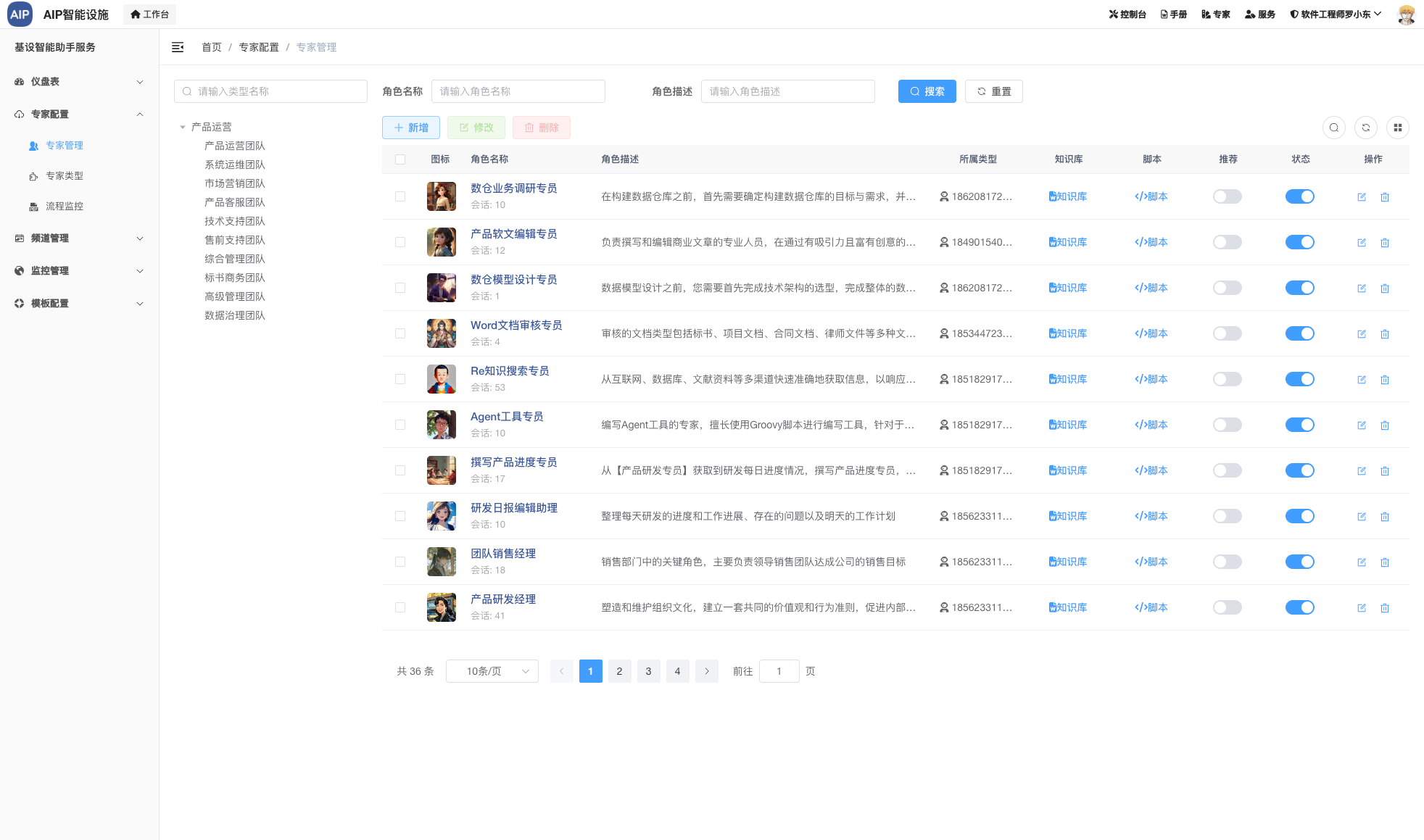
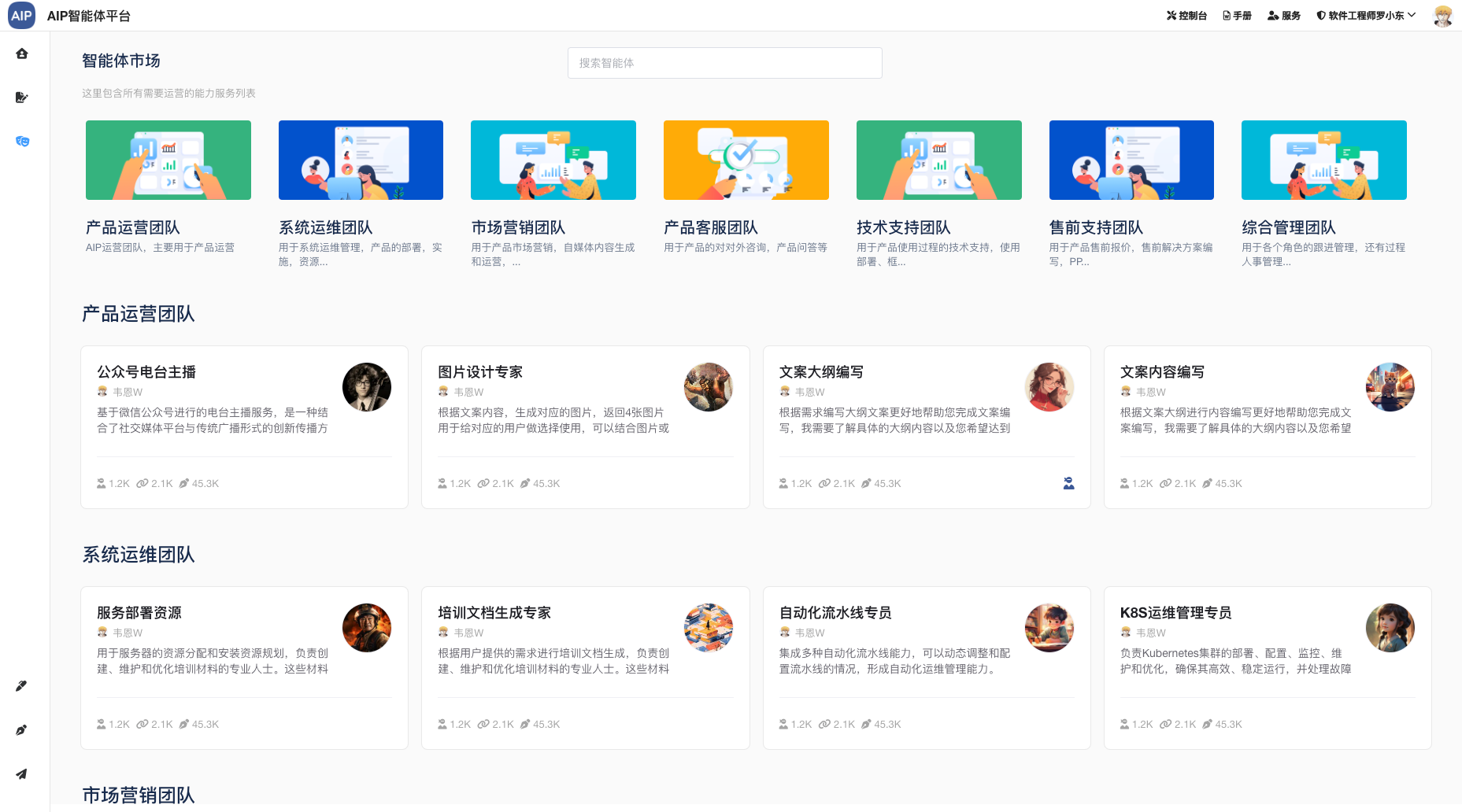
主要集成包括频道和场景两部分,单个Agent这里不做场景列出,单个Agent是组成Multi-Agent场景的元素,可以单聊,也可以做执行,也可以调用工具,但是多任务和要求集成在单Agent上会目前导致结果幻觉还有审核流程不太好结合处理,所以这里整理成Agent团队的概念。
注:当前部分引用图片为网络下载,用于研究学习使用
场景列出主要是为了作为demo例子使用,当然这也是平时在用的,结合实际验证。说明:完成指已经在使用当中,测试指在调试验证中。
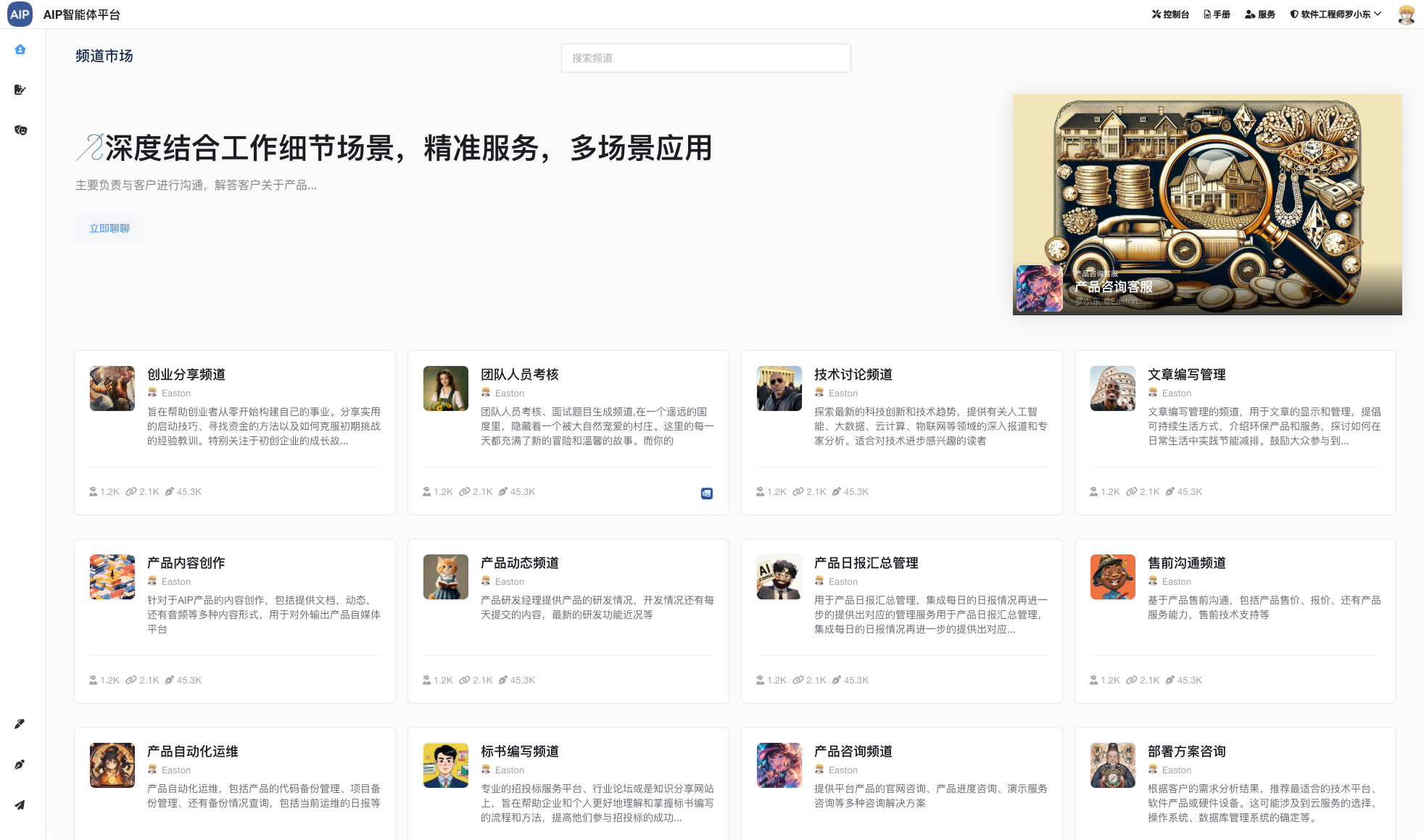
频道
多个Agent可以拉在一起调用,可以@指定的Agent角色,结果之间,知识库之间可以互相调用。
以下为目前集成的频道:
- (完成)写长文本文案,审核,导出word
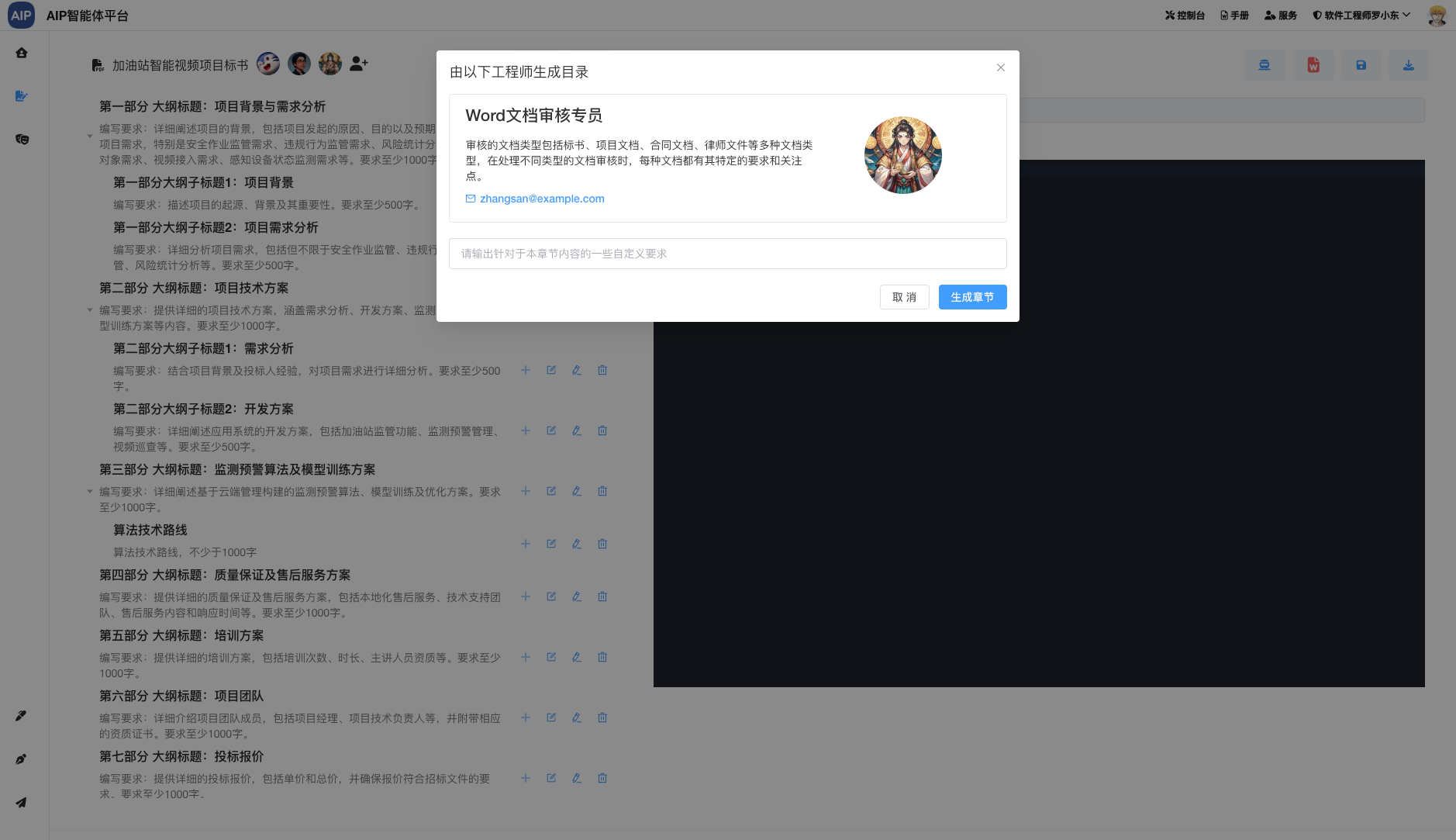
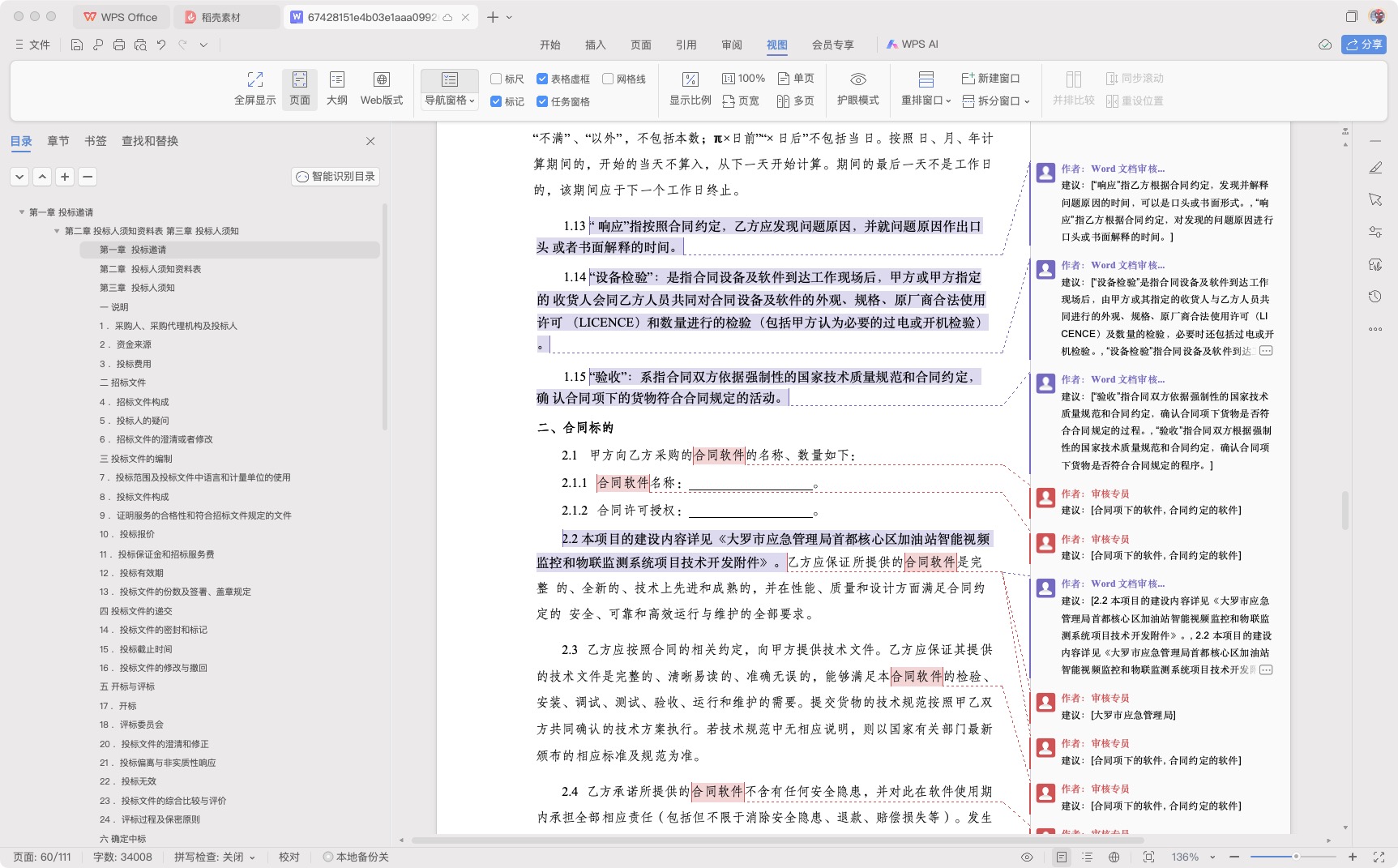
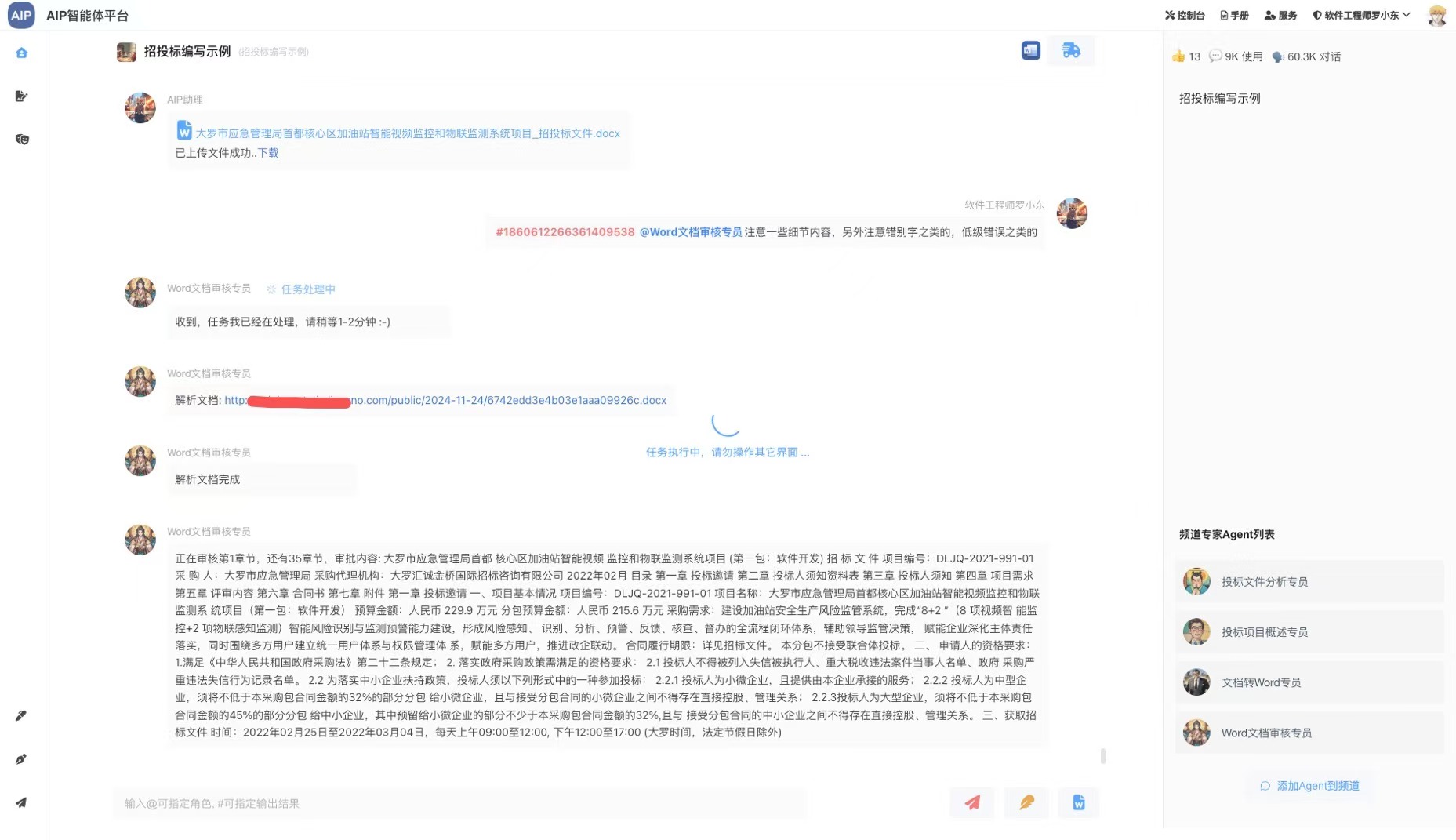
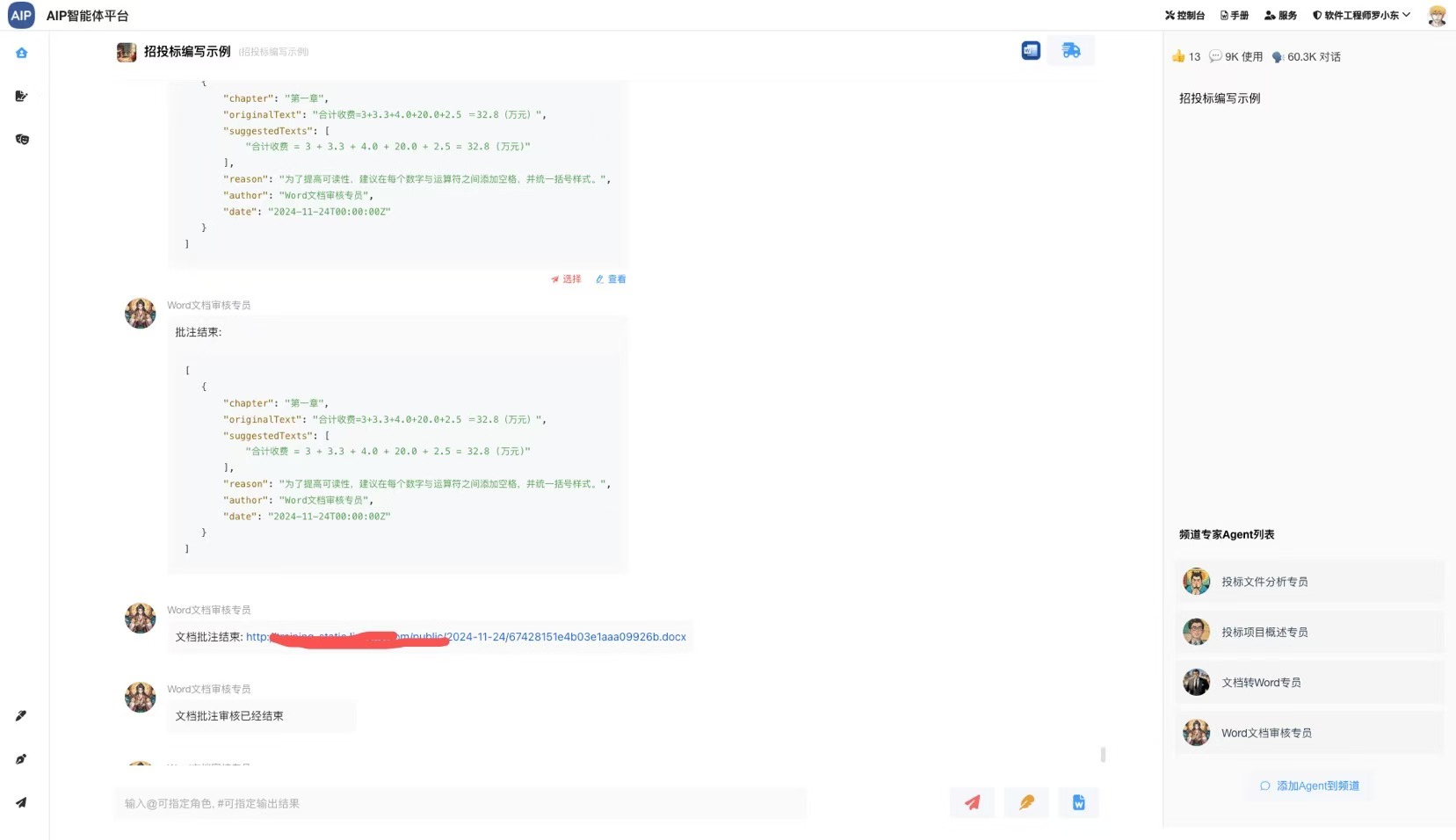
- (完成)分析标书,写标书,导出word
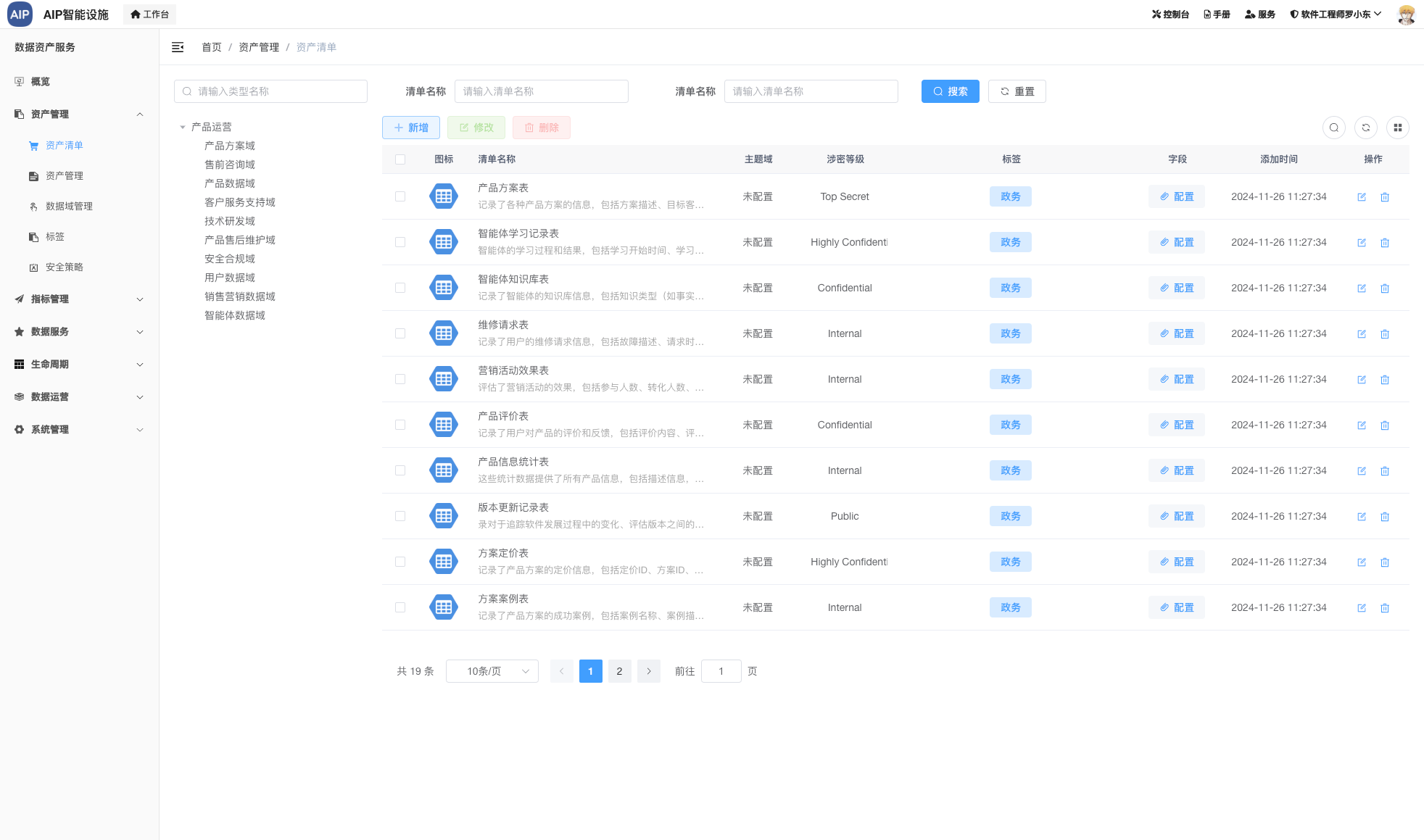
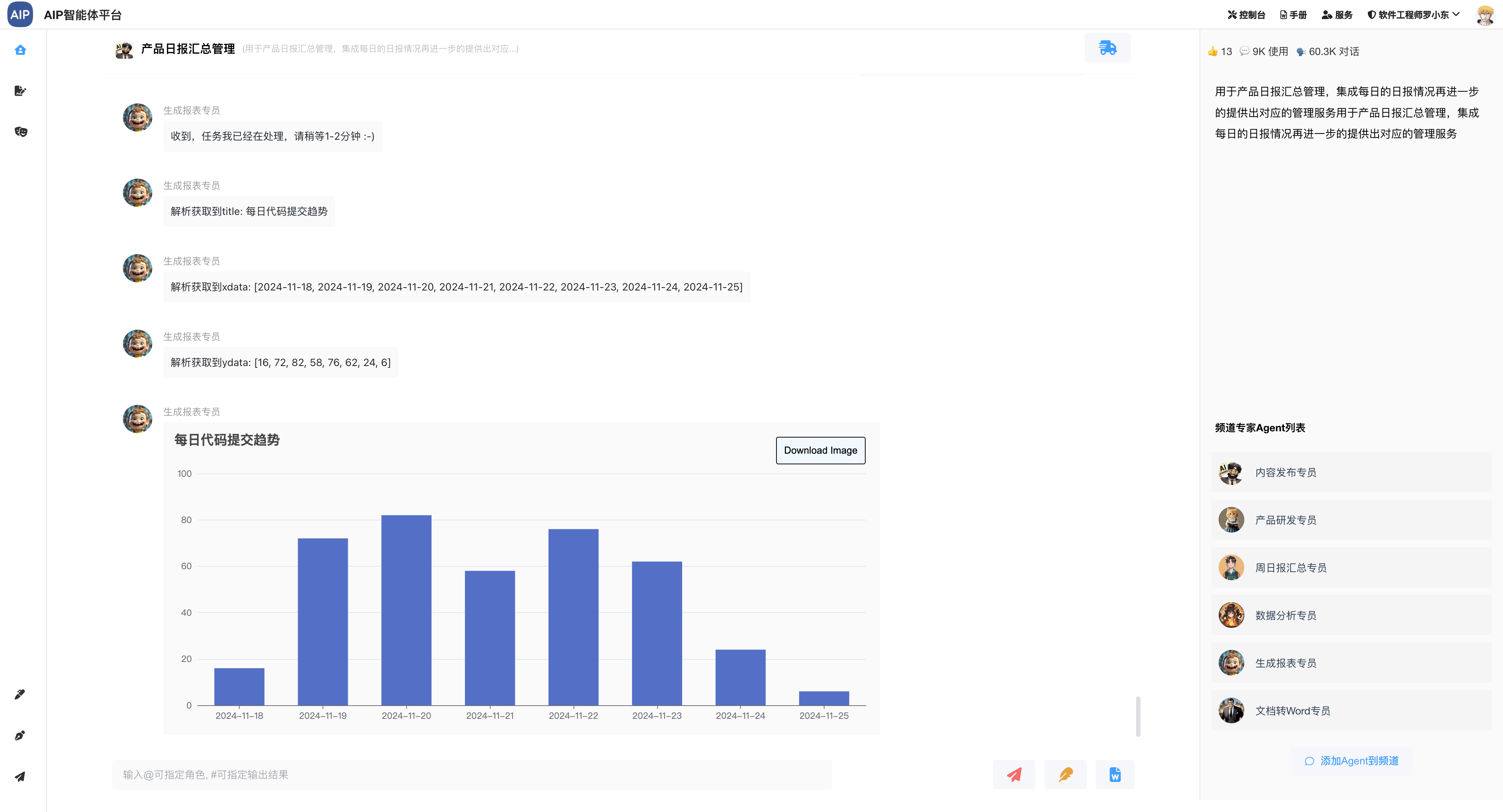
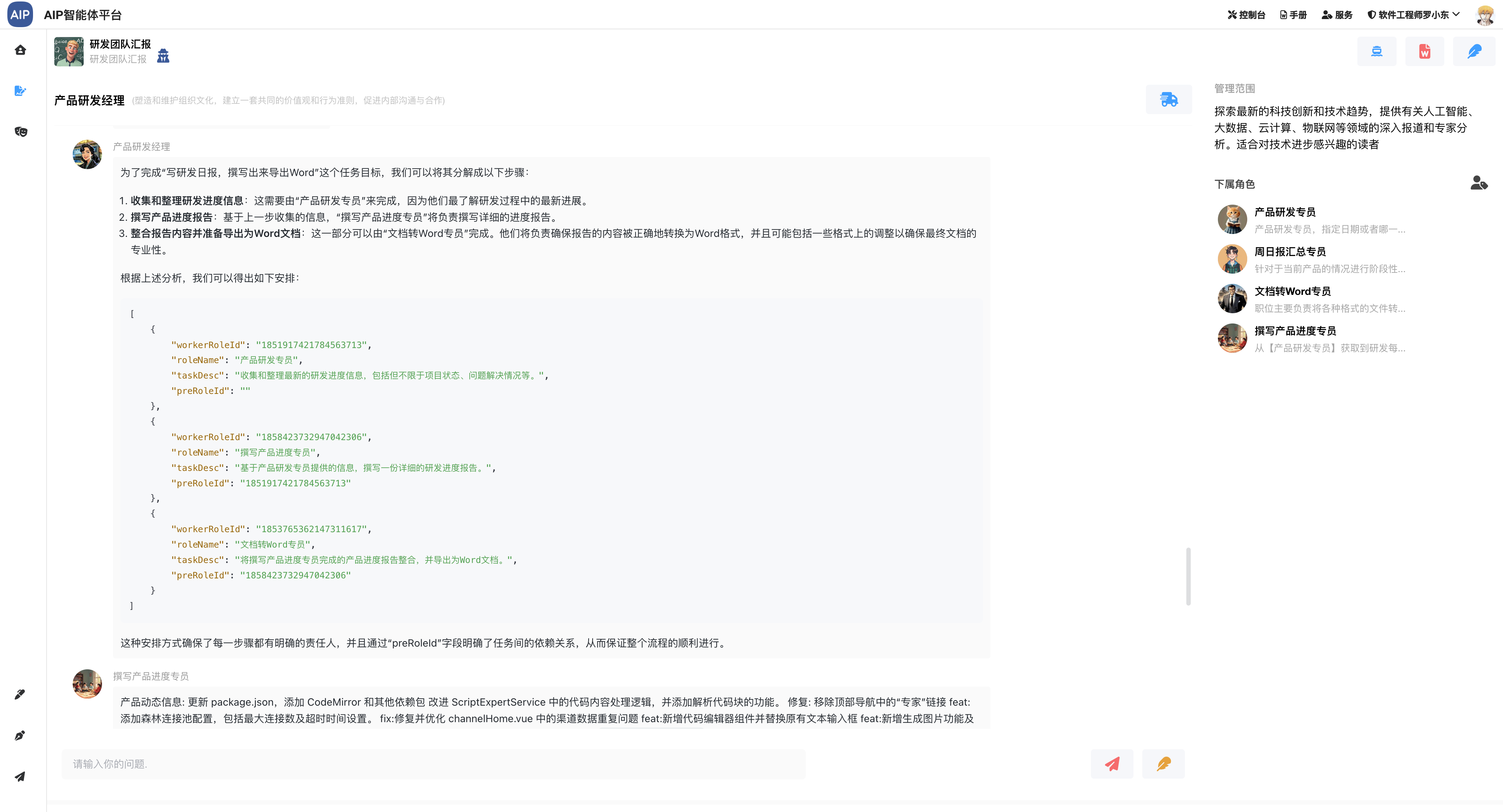
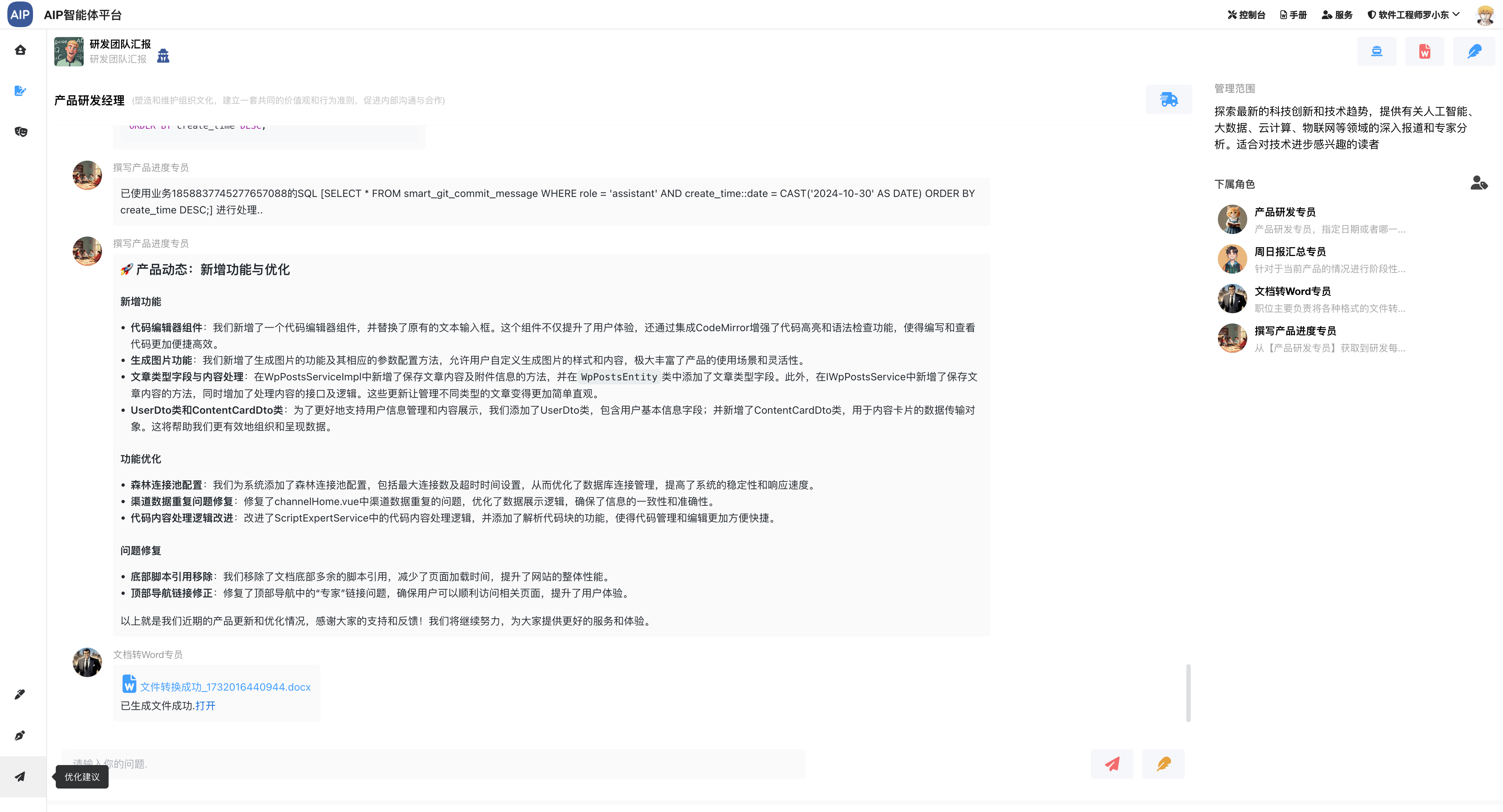
- (完成)每日或是根据时间段进度汇总,也可以导出word
- (完成)研发工作日报、周报编写,也可以导出word
- (完成)研发工作统计情况还有报表生成
- (完成)文字转成对话音频,导出mp3
- (完成)根据场景需求生成图片4张
- (完成)网站知识库自动导入客服咨询
- (完成)根据意图项目自动发布项目集成
- (完成)根据问题自动推理自动使用工具输出结果(ReAct模式)
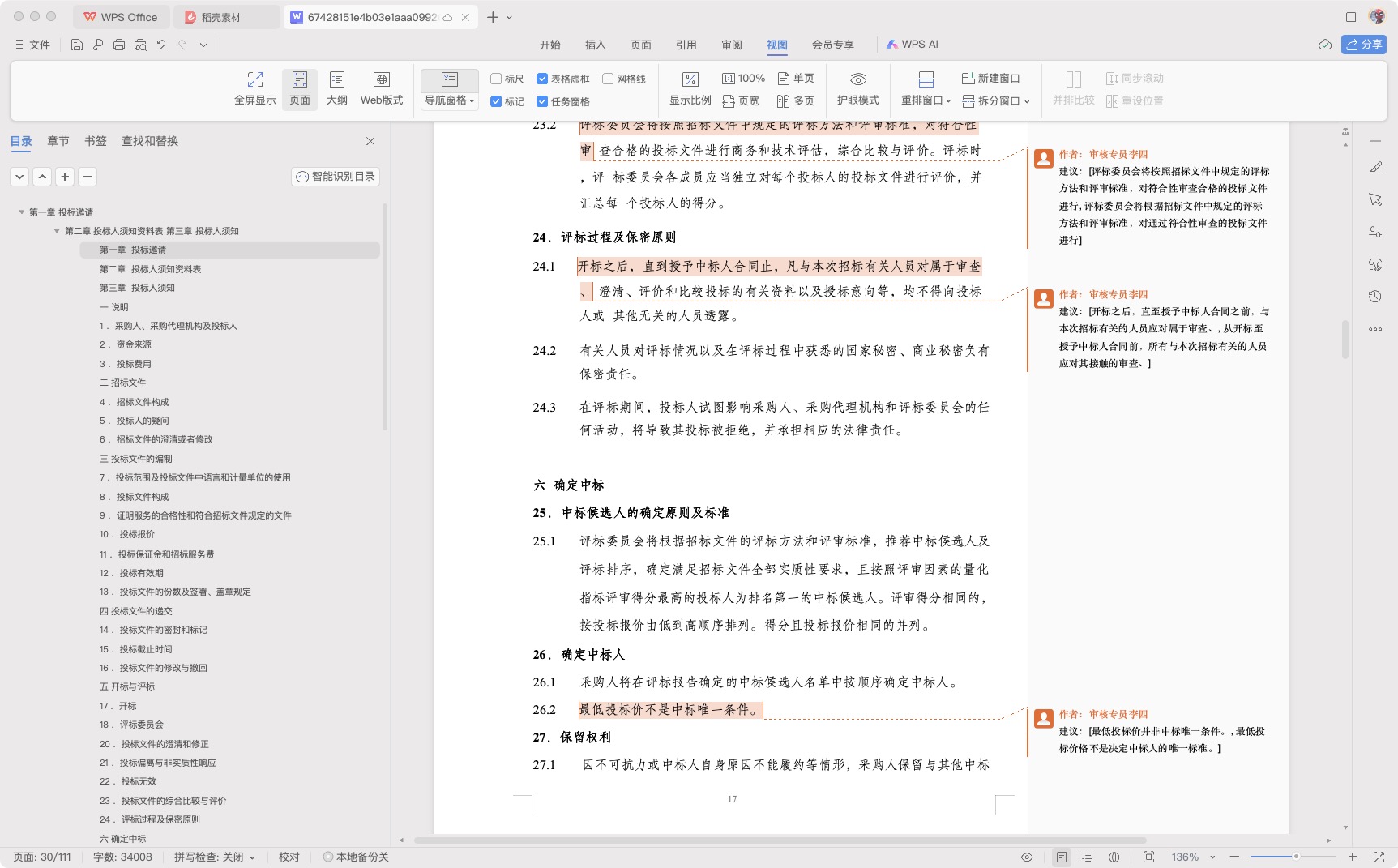
- (测试)word文档内容审核标注导出
- (测试)培训考核题目导出(包括答案),发送Email到指定邮箱
频道的使用角色之间有比较大的共用性,比如很多频道都需要发送email或者word,还有调用研发专员Agent等。
场景
不管是大模型的限制还是使用的便利,还有更加符合业务场景,统一抽取出来的特定编排形式。
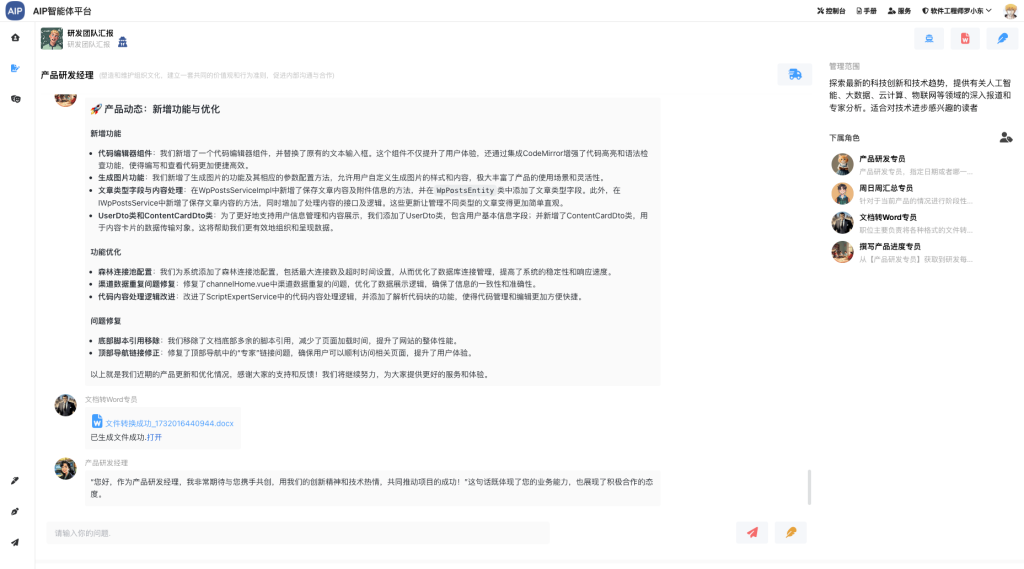
以下为目前集成的场景:
- (完成)多Agent配合超大文本标书编写
- (完成)多Agent配合每日自动生成日报
- (完成)多Agent配合编写长文本内容
- (完成)管理Agent调动分配工作Agent做事
- (测试)多Agent配合写论文同时配图和报表,公式
- (测试)自动采集线索自动整理销售方案和技术方案
- (测试)自动根据需求生成新的Agent
这里只是列出已经使用和调试好的Agent,场景之间可以互相通用,需要定义Agent还有知识库的处理,针对不同行业达到通用性,比如大文本也可以编写律师行业的合同类。
计划
后续分配行业场景结合,目前为上面的例子,目前对例子进行集中测试,输出需要的指标:
- 频道、Agent、场景的成功率
- Token消耗成本
- 每个Worker节点时常
还有常见问题输出,对应的例子进一步优化使用和说明文档在整理输出。
以下为编写的初稿:http://portal.infra.linesno.com/technical/brain/01_自定义智能体开发流程.html
附
AIP开源地址:https://gitee.com/alinesno-infrastructure
设计思路:http://alinesno-agent.linesno.com/book/
注:部分图片从网络下载做调试使用,目前为研发学习使用而非商用。