
软件工程师罗小东,多年架构和平台设计经验,目前在研究平台与新技术结合中。
概述
临时记录的笔记,表达中可能会略带有一些口语化,同时注意此版本平台还在研发调试中。
这里阐述以平台运营为主,这里假设说已经有一个平台,包括技术、数据、运维、管理、运营等基础设施的能力。
这个设计原来主要的问题是超自动化的提升,结合LLM为了更好的实现,在这个过程中,也包含了一些自主的感知和学习的能力,带有智能体的一定的特征。在前期的研究中也是不断的查看和摸索了很多的开源项目,包括一出来就热门的Github项目,但在使用遇到的情况更多的是还只是属于一些例子或者带有很多不稳定因素,并没有说见到能达到较稳定的层面。
在这个过程中也发现,GPT的交互过程中,涉及到的问题也很多,比如最直接的是内容生成的发散性太强,接口费用太高,返回内容不准确,还有数据提交过去产生的安全性问题,接口响应时间等问题,实际中见到运用得最多的是知识库,LLM+数据源(向量库/其它loader库),比如langchain。针对于平台层来说,内容的不稳定还有交互不明确,数据安全性等,这些基本上就完全无法接入平台服务,试想,使用过程中突然有一个不稳定的因素,上层业务运行容易一片雪崩。
针对于前期的整合过程,做了一定的处理,以尽量减少和达到可用的目的,下面交互的架构图:
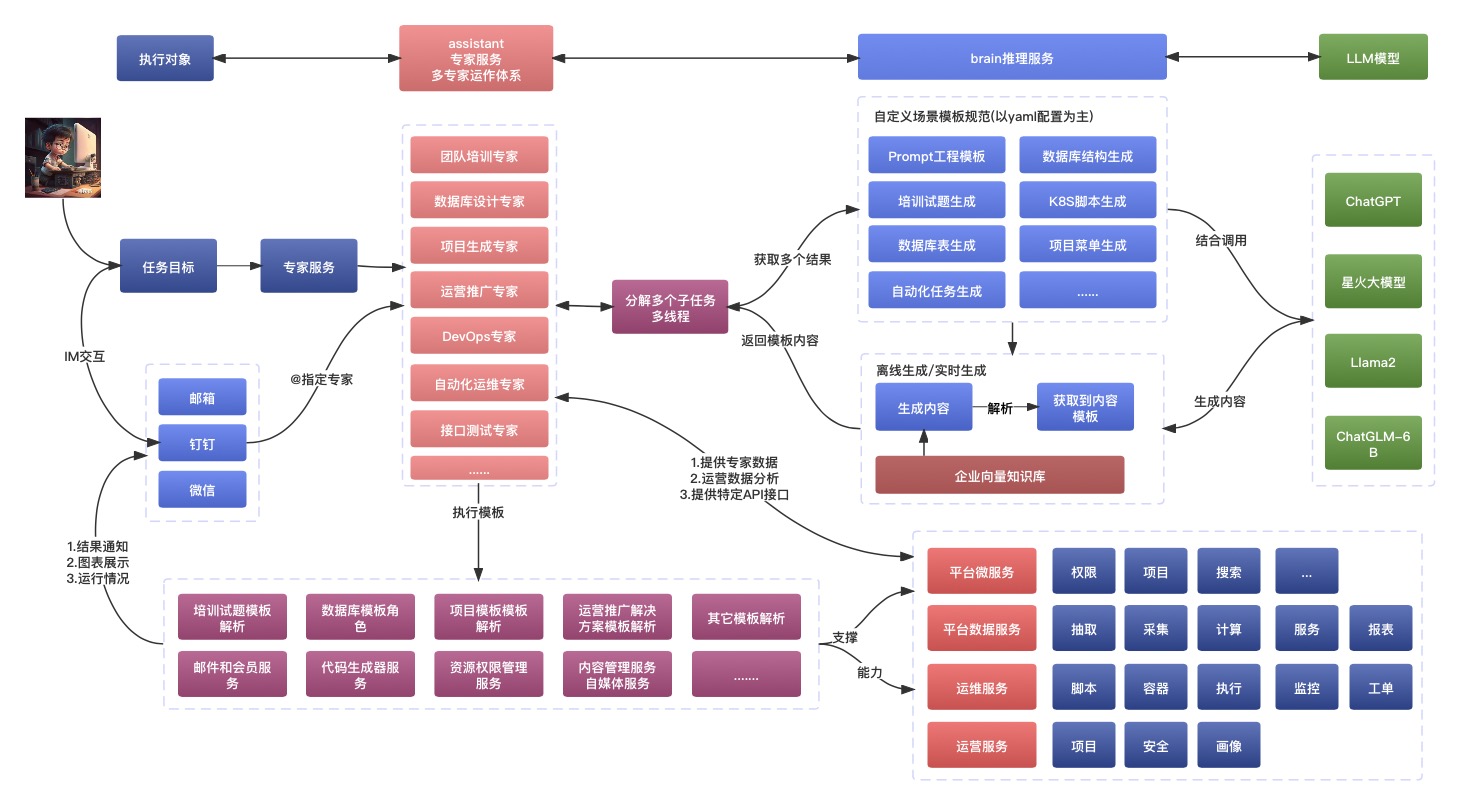
这里从几个点来进行阐述,前期研究中的一些交互设计思路和过程思路:
- 增加和调整平台的一些规范要求
- 结合AIGC进行的平台多场景Agent设计
- 支撑交互的服务组件建设设计
在此过程中的多方调试,为了更好的进行交互设计,针对于Prompt的编写上制定了一定的规范,还有平台的工程上面也做了一定的适配调整,我有我思。
处理方案
主要是针对于前期运营平台过程中的一部分自动化处理方案,当然场景还在挖掘,比如当前团队的培训就是使用上面的交互流程来培训,以提高团队能力而进一步提高平台在实际中的落地。
调整的一些规范要求
这里的规范性指的可能很多,这里主要是当前做的一些内容,可能还不全,也在调试和挖掘场景中。主要包括:
- 整体服务之间接口的规范,这个是遗留问题,涉及到的服务有的基本上要提供出可调用执行的api接口,比如k8s发布接口
- 服务之间交互需要增加一层adapter层,这个类似于DDD工程结构里面的基础设计层,作用类似
- 所有涉及到AIGC的交互,全部使用yaml格式来进行,同时要最小参数来生成结果,表达越简单越清晰越好。
以上服务调整的规范和提供能力,主要是为了更好的进行后期的交互,这里指的是所有的平台服务(包括技术、数据、运维),有一些自动化运维比如ansible或者k8s发布可能没有接口,可以结合第三方,比如jenkins来提供API以执行服务。
adapter层是针对于第三方交互的时候调用的,也是为了给AIGC服务调用的解析模板能力,这层目前还在适配,往往可能很多时候还是空的,做到的时候,统一通过这层进行交互对接处理。
使用yaml来交互的原因主要是上面提到的准确性的问题,在调试过程中发现,GPT结合yaml生成出来结果准确性基本上很高,没见到有哪些错误,甚至它还能帮你处理错误,这推理也是比较好.
比如下面的培训试题:
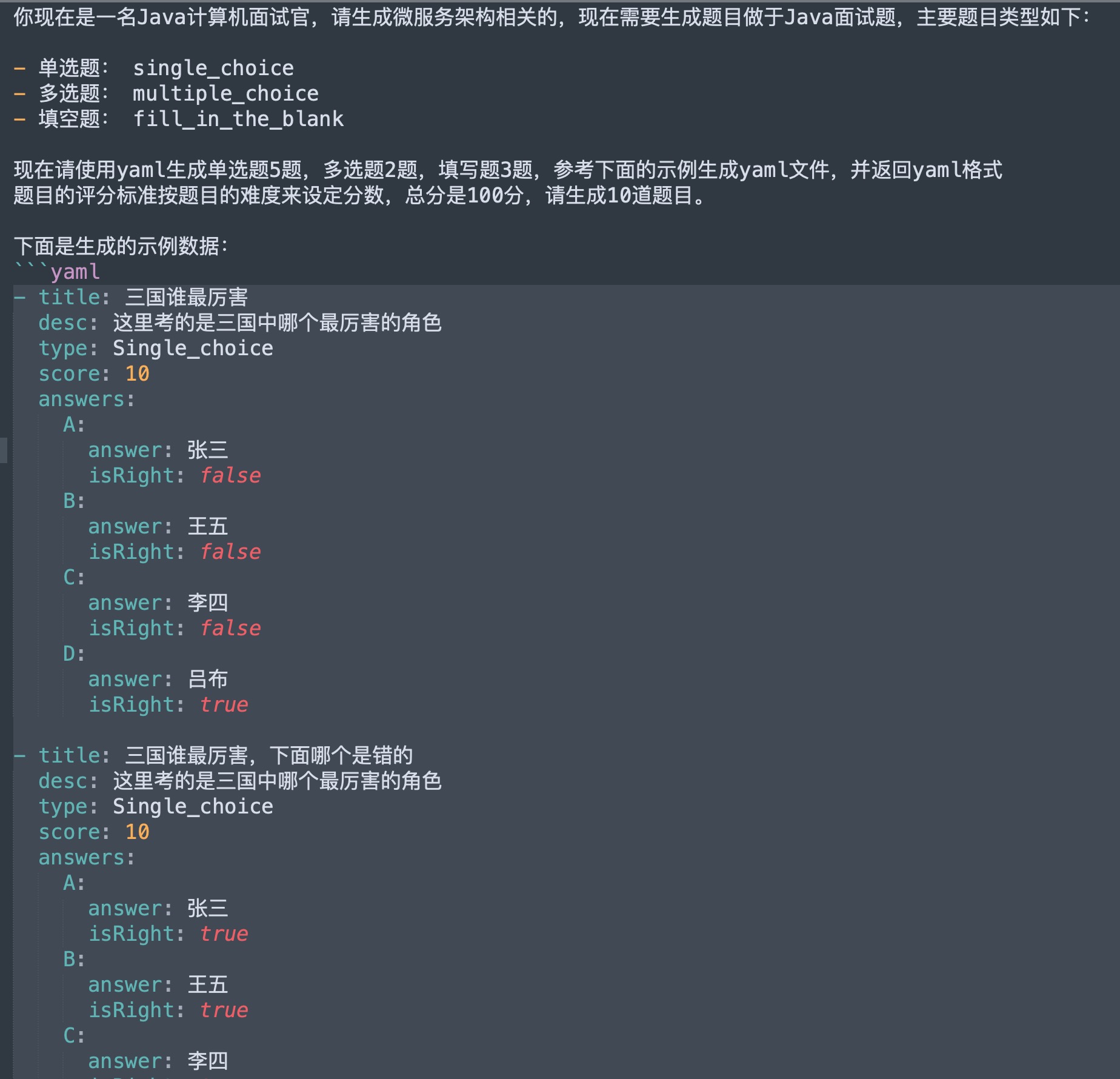
这个Prompt生成出来的试题准确程度还是比较高,除了见过一两次接口生成的时候不完整,基本上没见到错误,后续还继续观察,至少得到一定的准确比例。另一个原因是交互的数据提交问题,并不想提交太多数据以规避token的成本,只需要针对提交的参数,获取到清洗出来的数据即可,同时一些数据增加了脱敏的处理。
结合AIGC进行的平台多场景Agent设计
这里交互的方式主要是使用很多Agent,也可以理解成专家,这些专家的目的是完成每一项目过程中的任务,也就是将原来一些手工处理的或者需要人工处理的,交由Agent来处理,比如刚刚提到的知识库,这也是一种解答的专家。
不同的场景针有一不同的专家来调用Prompt的服务,来获取到结果,可能调用一个或者多个,通过多线程进行结果的整合,类似于MapReduce一样的,这个不是很难处理,之前也有考虑工作流,这样一个流程可能就是一个专家。我们并没有使用langchian,主要是在使用过程中发现,可能调用服务和管理数据,会更可控。
在处理完成之后,返回的结果会针对于每个专家设定的角色去调用相应的服务实现,每个服务实现针对于yaml结果进行解析,然后调用本服务能力,比如发送邮件之类的,或者说数据抽取。这里如果用过DataX的同学可能就会比较理解,DataX在做数据抽取的时候,使用的是一个json文件,我们的目标也就是生成类似的文件,用于更好的做交互,这个生成对LLM来说,难度并不高。
最后便是结果的通知和整合情况,这里IM工具比较多,专家也可以做成接口服务,放到IM工具里面,比如在钉钉里面设置多个机器人,这样组合起来的ChatOps能力就更强一些,我们目前正在调度这几步,目前还没有调试到对话的程度,目前也在考虑这块。
数据来源的问题,每个Agent针对于特定的场景,在交互中数据的来源也是比较明确的,一个是向量库,另一个是数据服务,这两个可以理解成GPT的记忆能力库,会在交互过程中,进行记录分析,然后再进一步的将结果反馈,从而下一步调用的时候,GPT返回更加专业或者达到经验积累的目标,原来的考虑是类似于自我演化的系统,这也是在调试,这步也包含上面说的对话调试,当然效果上还没有达到预期。
支撑交互的服务组件设计
交互组件是以服务的形式的提供,即微服务的形式进行管理,每个是单独的服务,便于后期的共用或者单独使用。下面是服务的截图:
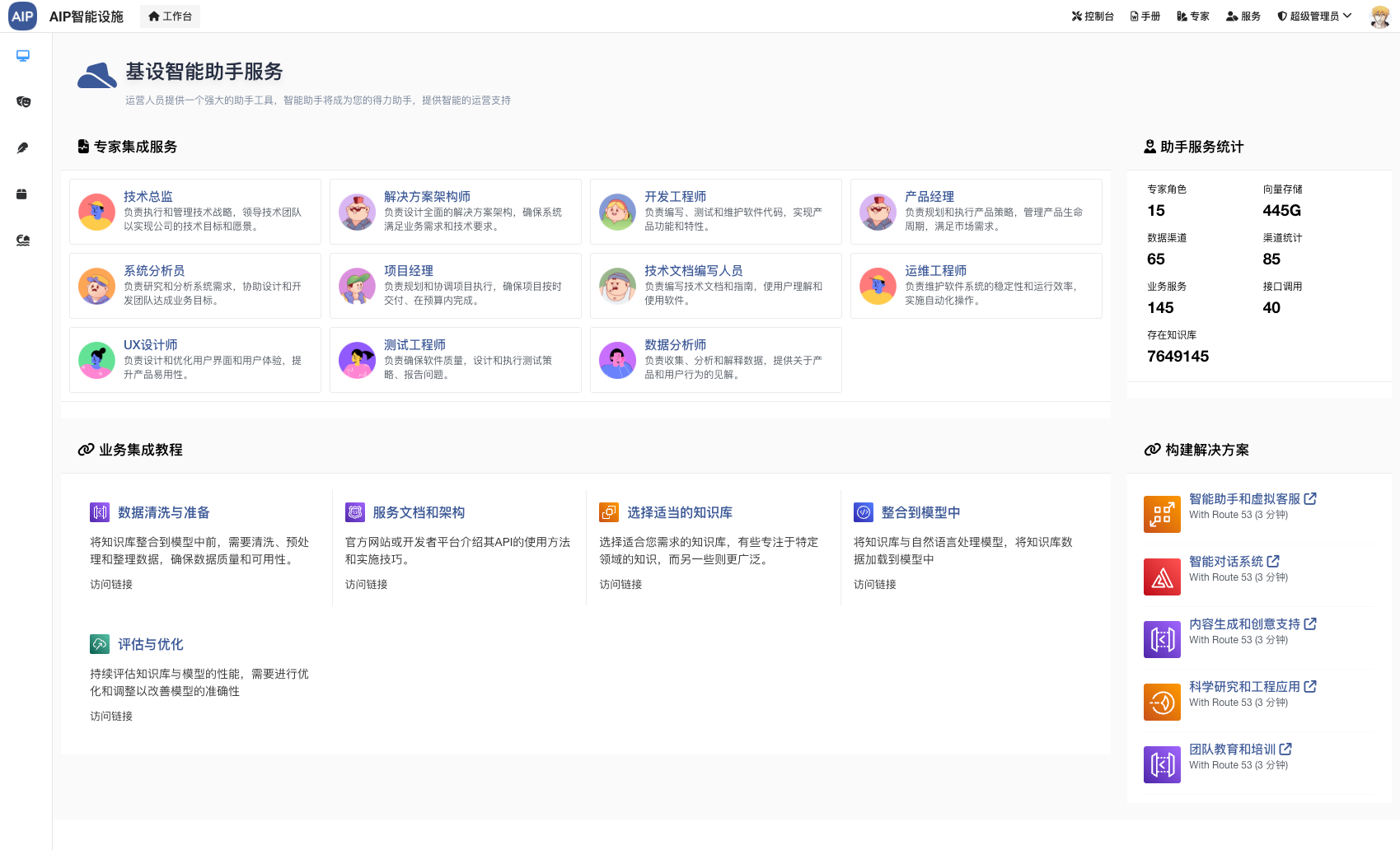
在这里为了更好的达到交互的目标,设计了几个服务组件,主要是:
- 推理服务:这个主要是对于基础层的Prompt工程管理,还有模板内容解析,还有一些向量库,总的目标来说就是管理Prompt工程
- 助理服务: 这个主要是对于Agent而言,也就是专家,每个场景的专家会调用推理服务的一个或者多个Prompt接口中获取到结果,并提供出yaml交互
- 脱敏服务:这个会比较好理解,主要是针对于一些敏感词和或者一些内部数据做的脱敏,回来之后在助理服务进行置换
服务化的另一个考虑是针对于LLM来说,是一个可拔插的东西,在不需要的时候,不部署或者这些服务即可,比如针对一些比较感触的团队。
总结
上面便是平台在前期AIGC交互中的一些探索和处理方式,在这个过程中想像空间还是比较大,能挖掘的场景也是比较多,目前发现的很多人工处理部分是可以使用自动化来替换的,比如刚刚提到的团队培训,后期便可形成梯队模式和定向培养,在这个过程中验证的效果大部分还是达到预期。这些也在之前的GDG活动中做过一些分享,这里表达得更加细化,也期望可以给做这方面的同学一些参考,也欢迎提供更好的思路和经验。