此为产品输出章节,中台是数字化的最佳实践,ACP是针对于中小型团队,全新一代企业级标准的数字化中台底座
此文档针对于白皮书场景的产品介绍方案参考

中台产品概述
企业级研发中台服务 ACP(Alinesno Cloud Platform)是业务应用生命周期管理和监控的新一代中台, 针对于大中小型团队合适的开发平台,支持微服务化、中台化、统一权限和基础能力管理,数据采集、计算、数据运营输出, 统一业务规范,集成 DevOps 自动化流程,为业务上层研发提供基础的 研发环境,规范化的开发,为后期业务的沉淀 形成基础,为数据治理形成基础,更好的沉淀企业业务资产和数据资产,业务架构师的规划, 进行核心业务的改造和各个业务线的整合,形成行业的业 务标准和 一套解决方案,形成自己的核心竞争力。
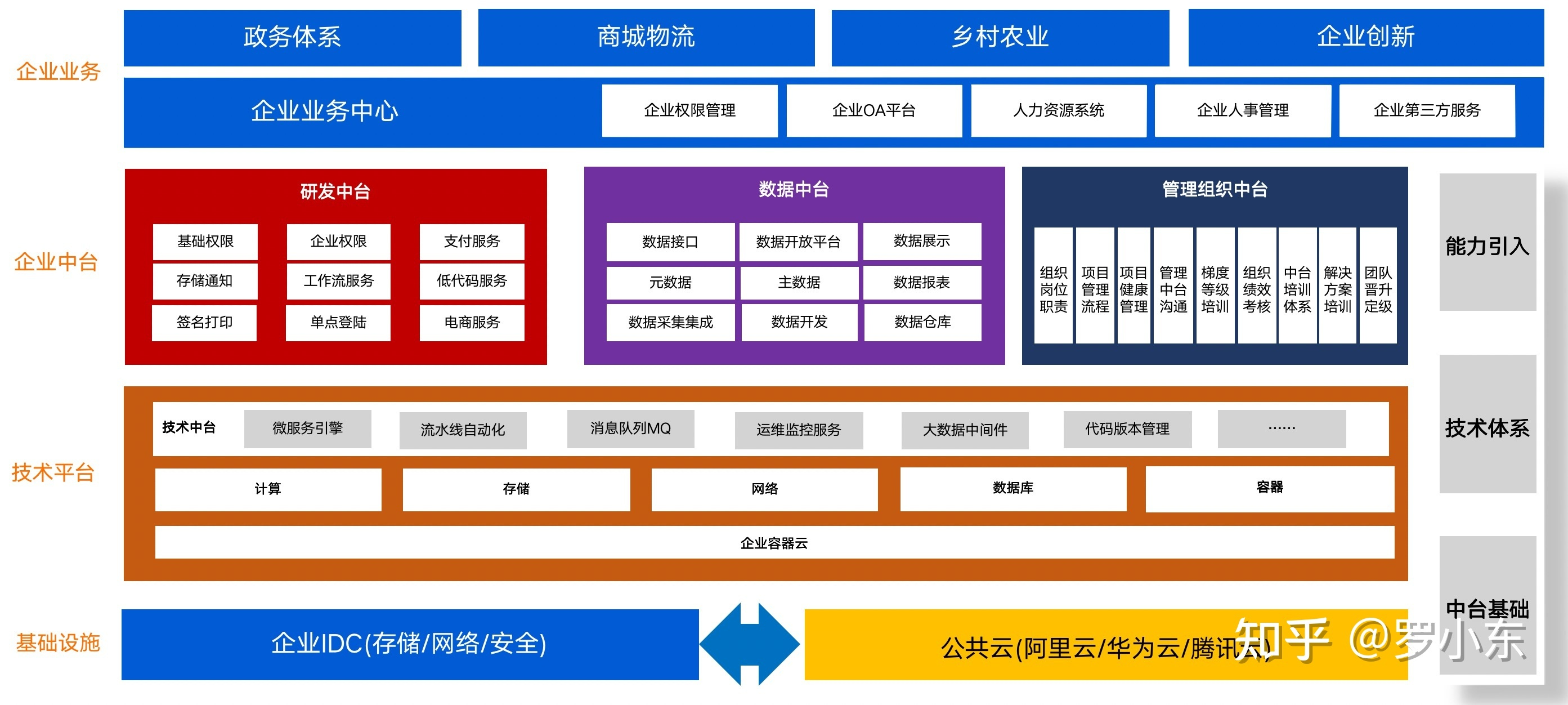
ACP主要针对的是中小型团队的场景,包括企业研发部门,外包,行业中小型软件公司,甚至是1-3个人的技术组。
整体ACP产品思路通过两个维度多个产品点介绍,大纲如下:
数字中台的基础能力
- 标准的数字中台产品基底,完善的中台管理体系
- 标准的中台体系,包括技术/框架/产品/中台/团队/交付/输出等,完善的应用周期管理
- 适配多行业的业务中台建设,支撑行业软件快速中台化,数字化,迅速升级
- 完善的SaaS应用周期管理,包括新应用的沉淀/行业输出管理等
- 基于容器化微服务/分布式/容器化等天然集成,标准的规范和可定制化
- 轻量级的中台化管理和最小资源配置,针对于中小团队的最快速中台化产品
数字中台的解决场景
- 消除基础平台中的不统一不规范,为业务中台数字化做基础
- 消除多团队多项目信息孤岛场景,解决数字化场景
- 兼容多云平台,PaaS+中台底座一体化集成,解决团队效能问题
- 消除中台化过程中的坑点,功能完善的微服务/容器化/业务集成化等可视化组件
- 快速解决团队中台化平台化的问题,快速统一标准
ACP中台能力
标准的数字中台产品基底,完善的中台管理体系
中台模型并不新,只是对中台的一个整体的模型更加明确的定义和思考,从另一个新的角度进行的思考整合,而不是以前的复用组件或是公共组件。中台架构是数字化行业的另一种体现,是一种新的标准,突破传统服务器的行业模式,在这个模式下,提升企业的发展战略,

这里中台的模型包括以下几点:
- 产品:企业团队沉淀能力体现
- 解决方案:客户业务价值体现
- 组织架构:价值落地的保障体现
- 技术:技术是落地的直接能力输出
- 合作体系:业务发展能力体现
- 沉淀:发展和突破点积累体现
结合上面的中台阐述落地体系,方向和发展走向形势参考,主要思考的几个点:
- 新解决方案:业务价值能力输出
- 新服务模式:客户交付业务价值输出
- 新发展模式:S2B 商业模式输出
从整体上表述中台的模型,也是数字化社区的目标和愿景,整体已不仅仅是数字化,更多的是以数字化为基础,进行更好的发展方向,是企业能力输出的的最佳唤醒和集中力体现,通过中台模型体现和输出。
标准的中台产品体系,包括技术/框架/产品/团队/交付/输出等,完善的应用周期管理
中台产品体系,从技术/构架/产品/团队/交付/输出流程,形成标准化的中台流程,基于中台的管理,集成业务中台的应用周期管理和集成,多解决方案的整合。
开箱即用的研发中台体系,快速实现研发中台和业务集成,覆盖了项目应用管理、代码仓库管理、有效提高企业的管理、研发、过程自动化流水,研发中台和团队组快速结合:
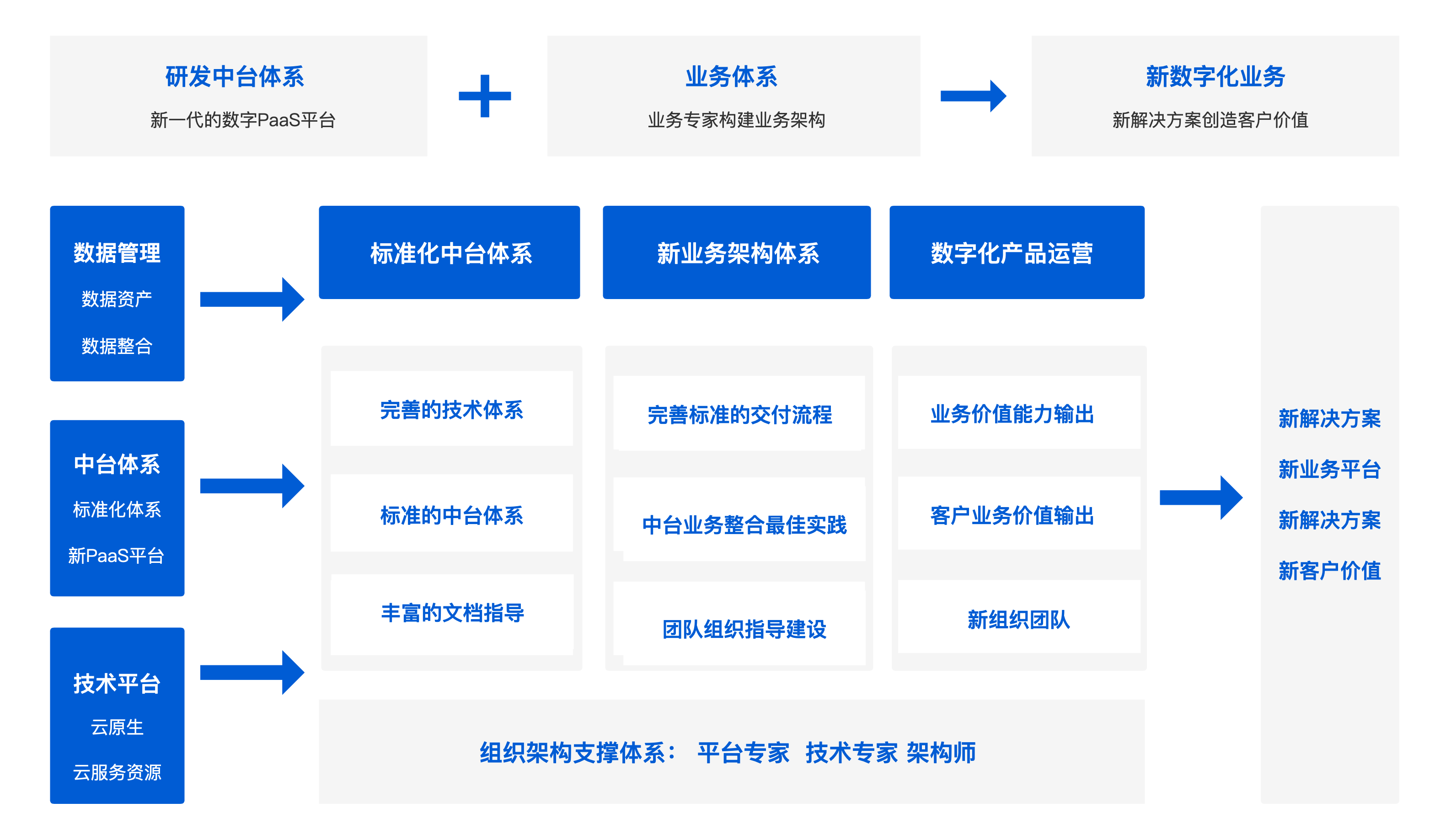
主要包括以下模块:
- 基础技术框架
- 数字中台产品
- 微服务技术
- 容器化管理
- 面向接口和领域研发
- 团队成长输出
- 应用周期管理
适配多行业的业务中台建设,支撑行业软件快速中台化,数字化,迅速升级
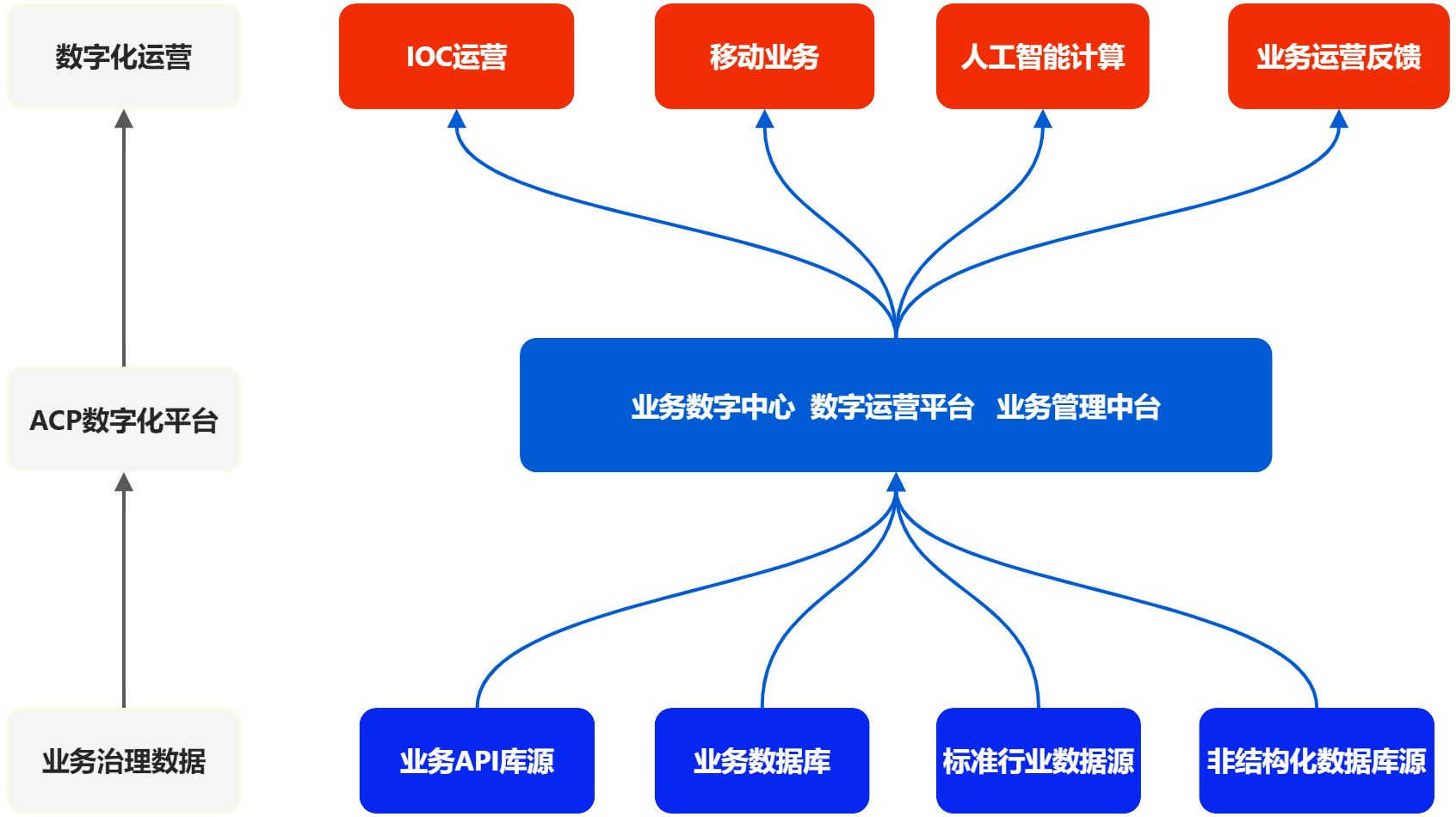
数字中台提取出公共的业务服务,封闭统一的业务接口,为业务上层的集成,提供基础能力,让业务中台建设和业务组件集成,不需要再考虑底层的技术偏差问题,同时提供出源码型的交付,业务针对于自身的情况,提供出基础的中台服务。
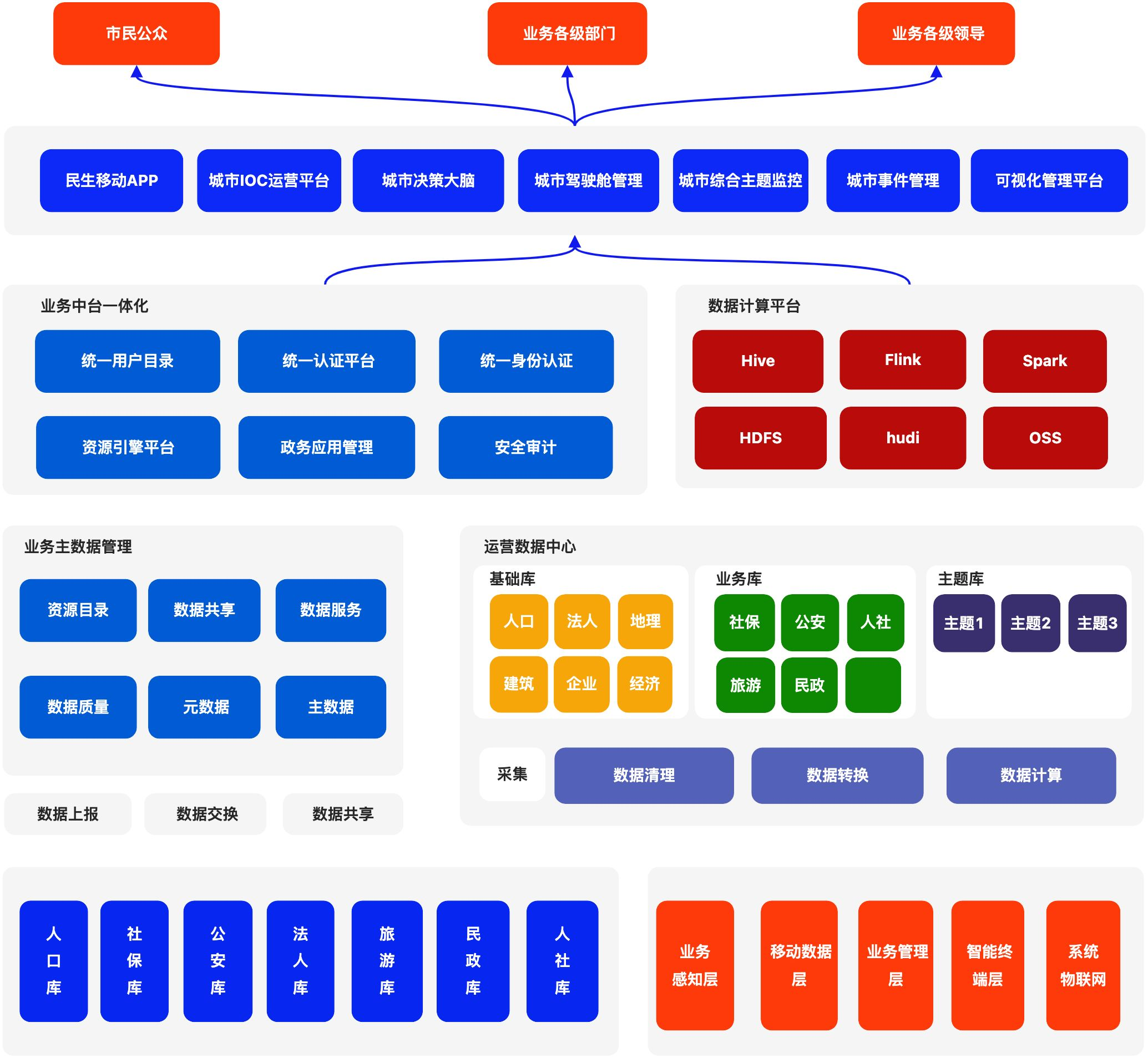
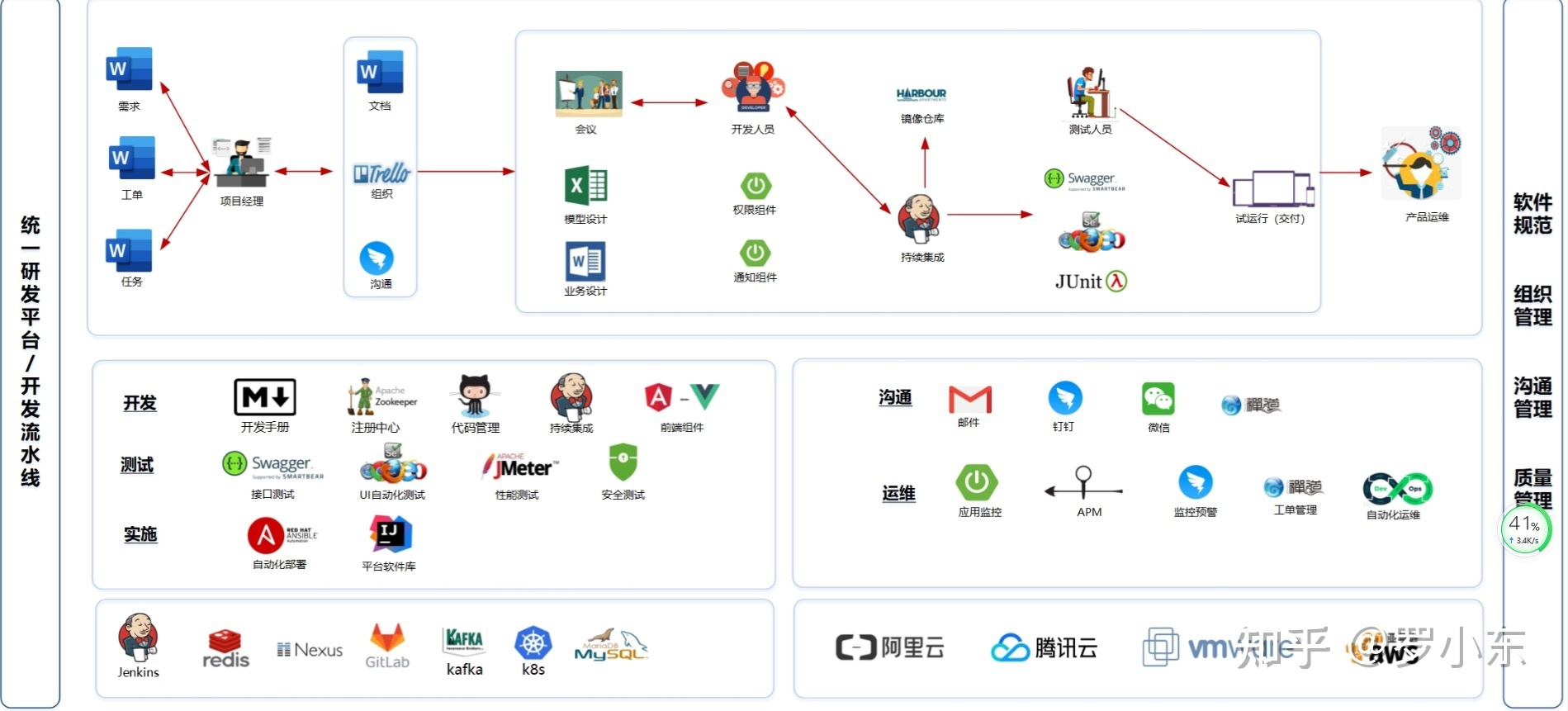
研发中台产品架构图,结合团队/组织架构/数据/应用/运营整体体系的产品规划,整体产品架构图如下
主要包括以下模块:
技术中台
- 技术研发体系:中台底层服务,解决管理流程和PaaS平台,多云平台管理;
- 微服务研发引擎:中台底层服务,公共的核心包,规避技术难点,统一技术版本和规范;
- 代码生成器服务:中台底层服务,规避技术问题,统一技术的可视化管理工具
研发中台
- 权限资源引擎服务:基础中台服务,解决多应用,多部门权限资源管理问题;
- 云门户管理服务:中台管理服务,解决中台应用生命周期和管理;
- 通知管理服务:基础中台组件,处理多通知渠道服务,规避多通知平台;
- 分布式事务消息服务:基础中台服务,处理消息管理和分布式事务问题;
- 支付管理服务:基础中台服务,解决聚合支付问题,规避多支付平台;
- 存储管理服务:基础中台服务,解决分布式存储问题,规避多存储平台;
- 工作流管理服务:基础中台服务,解决工作流在线管理和流程配置;
- 网关管理服务:基础中台服务,解决在线网关配置和接口权限管理;
- 开放平台服务:中台输出服务,解决第三方,外包,中台能力输出出口;
- 单点登陆管理服务:中台基础服务,解决多应用整合和各个接口权限认证;
基础业务中台
- 内容管理服务:基础业务中台服务,处理多媒体和内容管理服务;
- 会员管理服务:基础业务中台服务,处理业务会员管理和会员相关服务(电商);
- 电商基础服务:基础业务中台服务,处理电商平台的基础功能管理;
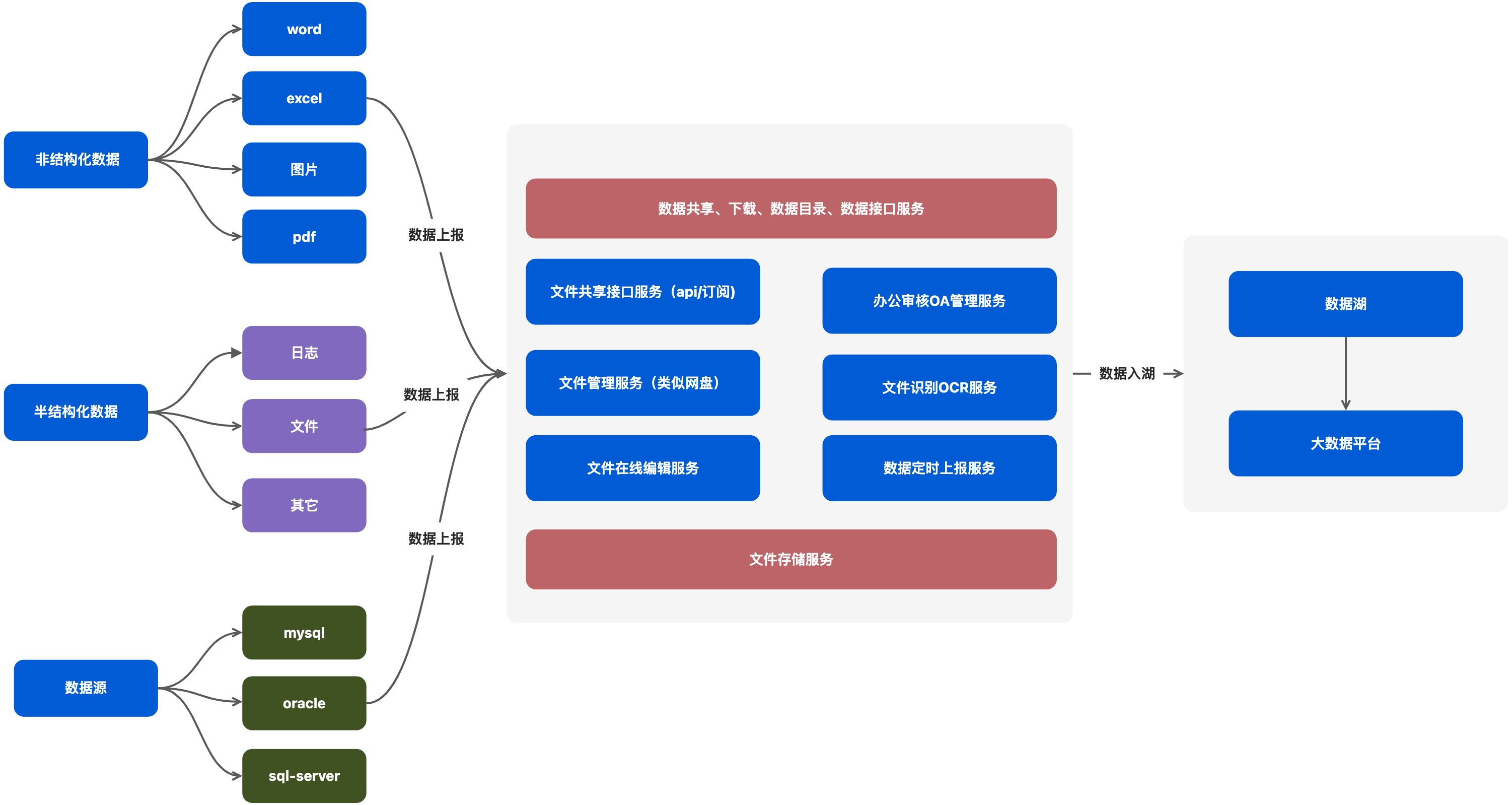
数据中台
- 数据中台管理体系:数据管理体系,解决数据中台输出能力的问题
- 数据上报服务:数据管理服务,解决数据集成和数据采集流程问题
- 主数据管理服务:数据管理服务,解决数据标准统一和业务元素管理
- 数据集成服务:数据管理服务,针对复杂场景下数据抽取问题
运维中台
- 自动化运维体系:中台管理服务,解决过程问题产生和运维体系架构
- 应用监控预警服务:中台管理服务,解决过程中问题发现和通知到人
- Ansible自动化操作服务:中台管理服务,自动化操作,解决运维解放人力
- 审计日志监控服务:中台管理服务,跟进日志追踪和异常问题发现
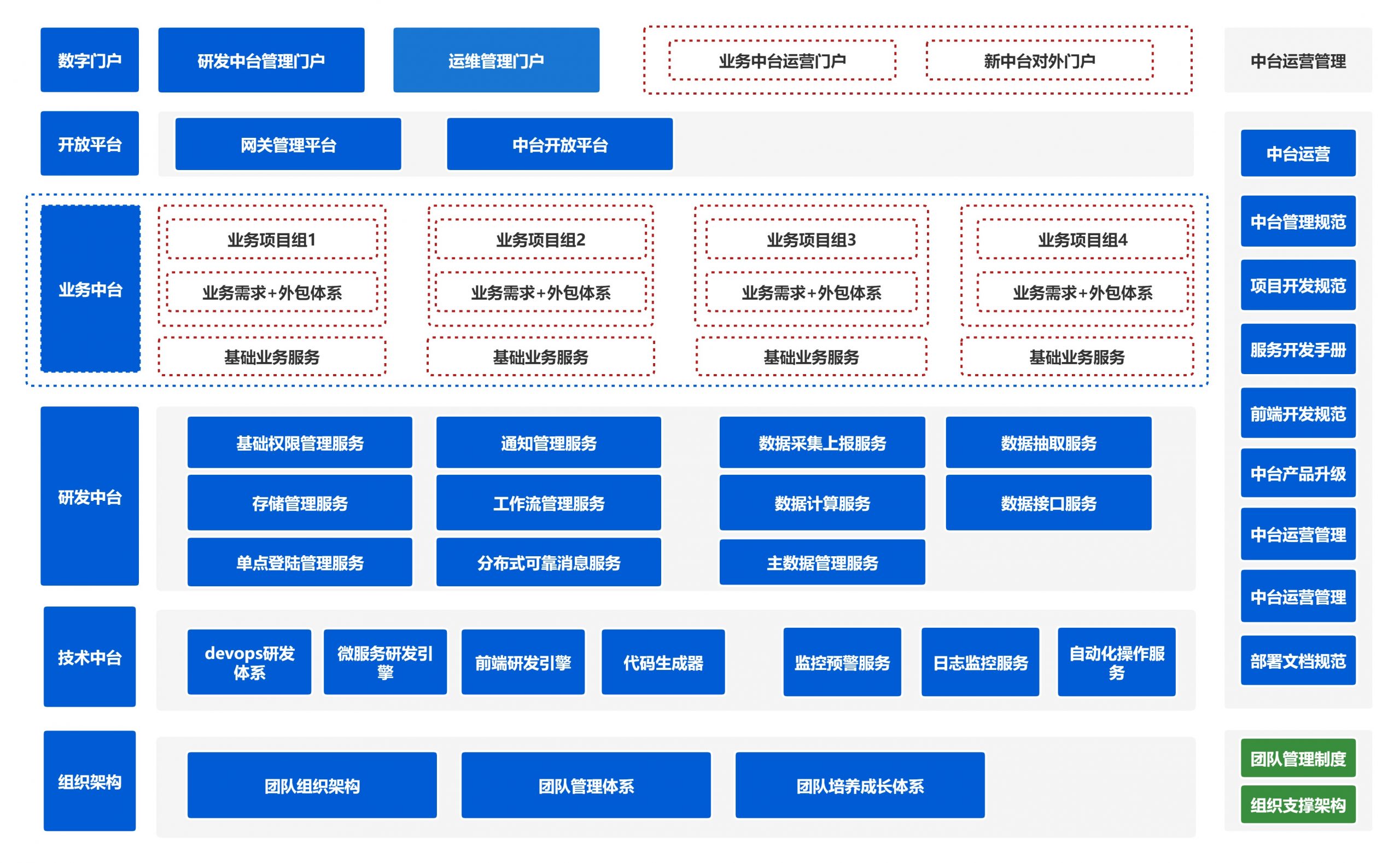
完善的SaaS应用周期管理,包括新应用的沉淀/行业输出管理等
统一的中台管理门户,集成中台解决方案管理,业务产品管理,通过单点登陆集成,集成统一的管理门户,便于多种业务的管理集成,提供内部研发人员成长的入口,形成团队统一的管理平台,同时提供门户管理平台,便于集成中台对外门户,建立团队自己的能力门面,业务产品门户等,整体架构如下:
通过统一集成管理界面,更好的进行平台化的配置管理和内部团队产品沉淀管理,同时形成统一的解决方案和业务能力输出,类似的产品形态如钉钉。
基于容器化微服务/分布式/容器化等天然集成,标准的规范和可定制化
完善的微服务体系,集成Dubbo和Cloud等多种微服务能力,结合K8S容器化管理,集成CICD平台,应用一键容器化管理,天然集成分布式管理能力。提供完善的微服务能力集成,包括nacos/zookeeper等,基于基础平台的管理和技术屏蔽,对于新来无感知,更好的切入到容器化中。
工程依赖于六边型思想,整合当前的项目工程结构特点,进行的规划和划分,以下为整体工程的规划架构:
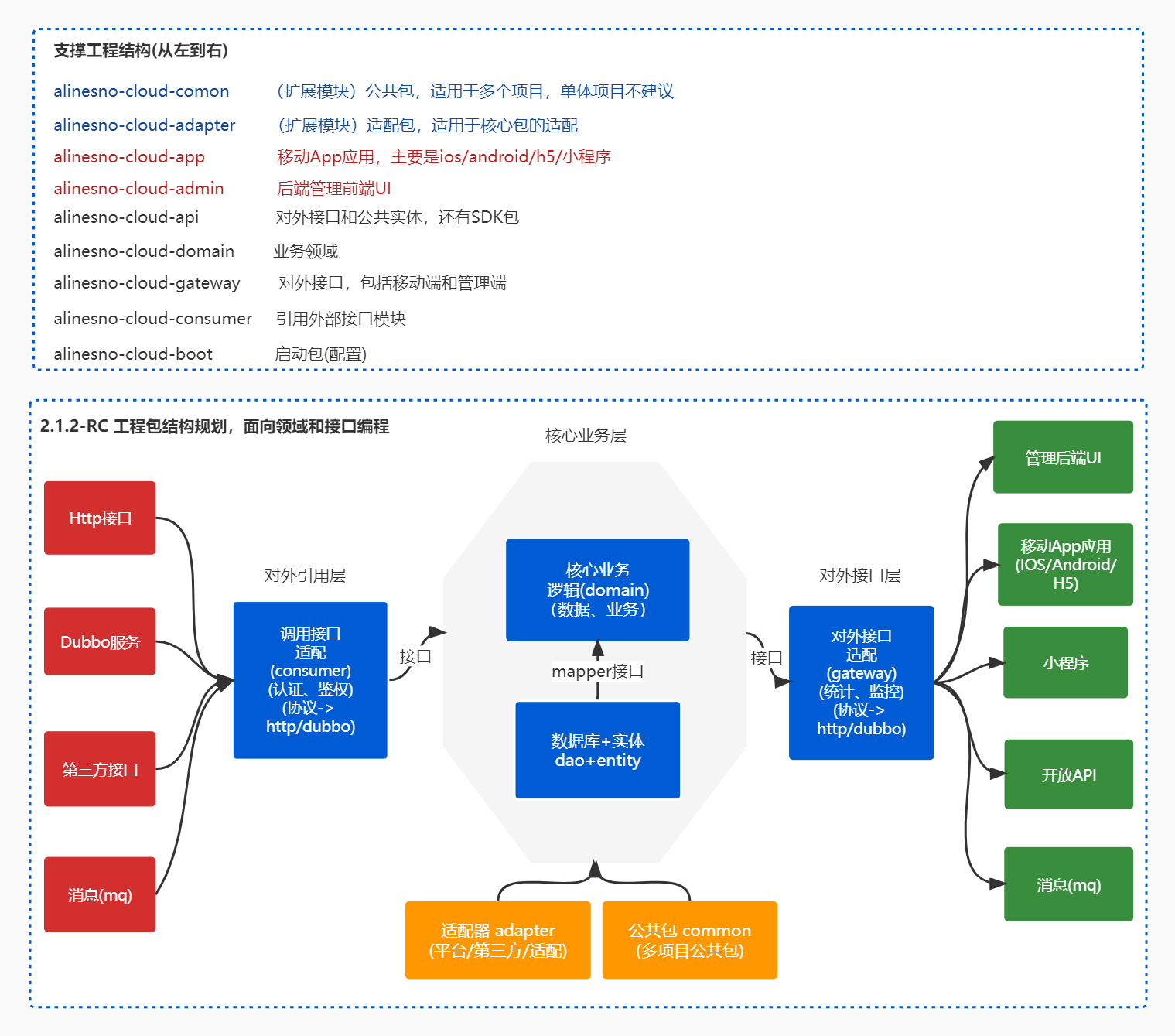
提供基于DDD架构和领域模型编程,更好的统一规范,结合代码生成器,自动生成基于前后端的服务,自动结合gitlab/gitee/gitea等,合适中小团队的版本管理平台,一键集成。
团队基于 spring boot 孵化了一套 alinesno-init 脚手架,可以快速完成新服务代码框架的搭建。目的是让项目平台所有创建的服务都是基于同一套框架和代码结构,统一风格和技术路线,避免后期升级等困难,代码生成器提供如下能力:
- 通过 alinesno-init 脚手架生成的项目代码,能帮开发者准备好开发的前期工作;
- 让开发更加迅速,不用在前期配置上花费时间,降低框架学习成本;
- 默认生成的代码配置,在线代码生成管理,让开发者更加专注于业务逻辑开发;
- 通过集成基础平台组件以及数据支撑类组件,为应用的开发提供底座能力赋能;
- 低代码生成器通过使用自动化生成的平台,集成多种环境配置,简化研发过程;
- 构建针对于微服务平台框架,进行整体的说明,自动生成集成容器配置;
- 自动生成容器化配置,避免繁琐的容器配置,形成统一的规范;
标准的工程结构和代码生成结构,为后期升级管理提升更好的规范,提供无感知的技术服务管理,低成本的技术切换和跟进。
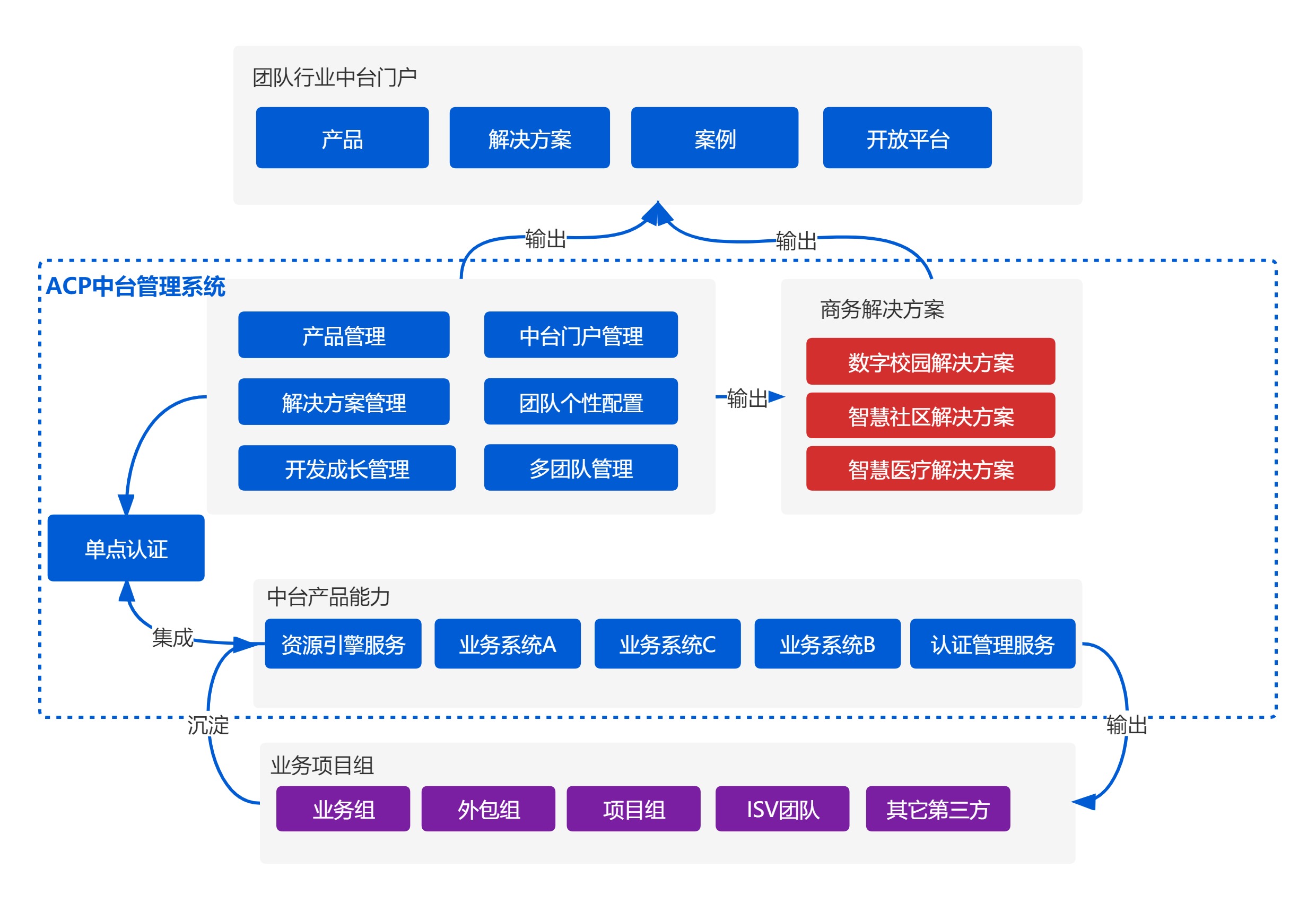
轻量级的中台化管理最小成本整合,针对于中小团队的最快速中台化产品
相对于大中台,大平台来说,ACP基于多组件化,统一门户管理的配置,按需配置中台,针对于较小的团队来说,并不需要一上来就一整套服务化,一整套的配置,而是按需求获取,整体不同的能力,根据不同的团队配置,搭配不同的业务场景,甚至包括1个人项目的场景,整体输出能力如下:
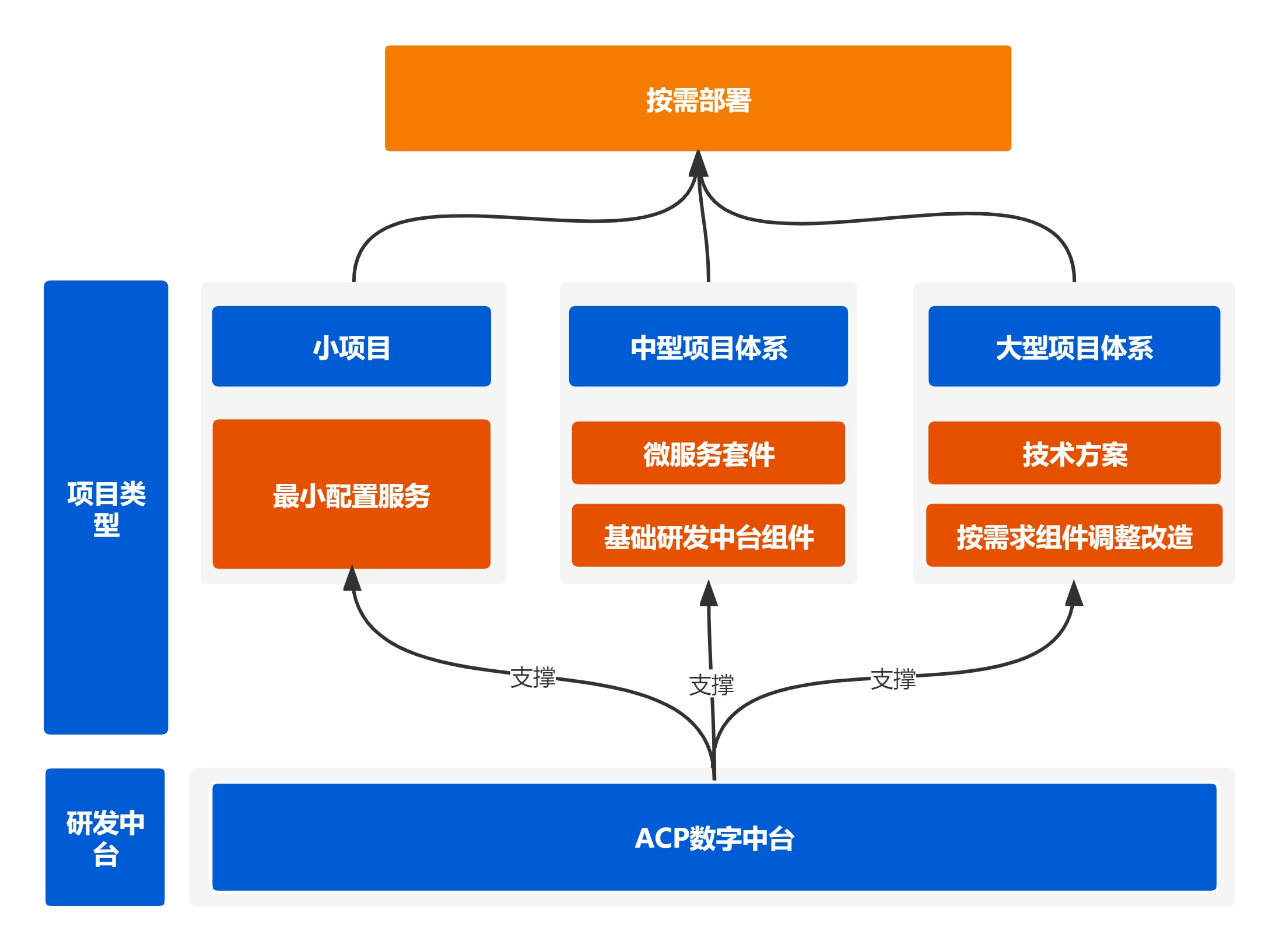
整体架构设计说明:
- 针对于不同的场景,按需求配置不同的服务;
- 通过可配置的网关和开放平台,对业务提供公共的API接口,体现中台的能力之一;
- 结合新旧系统的优势,最小的调整的集成旧业务能力进行平台,形成统一业务中台;
- 在线多团队,SaaS化的管理,为多团队管理形成服务,形成团队统一的规范;
解决能力
消除基础平台中的不统一不规范,为业务中台数字化做基础
技术不统一,不规范,接口各异等问题,为中小团队长久形成无底洞的弊端,系统维护成本增加,基础技术建设意义难合,内部沟通困难,无法形成统一意见,难以开展各个组之间的工作,面临的问题冲突:
- 新老项目的升级问题,业务线技术规范不统一,系统维护成本和人员维护成本高;
- 基础技术建设无法整合开展,业务和技术组件无法复用,一个技术方案多版本实现;
- 团队管理难,各自为政,新人切入和培训成本高,团队学习成本大;
- 业务培训和切入业务难度大,团队效率在无形中内耗,研发难以抽出上层安排困难;
ACP中台解决技术架构如下:
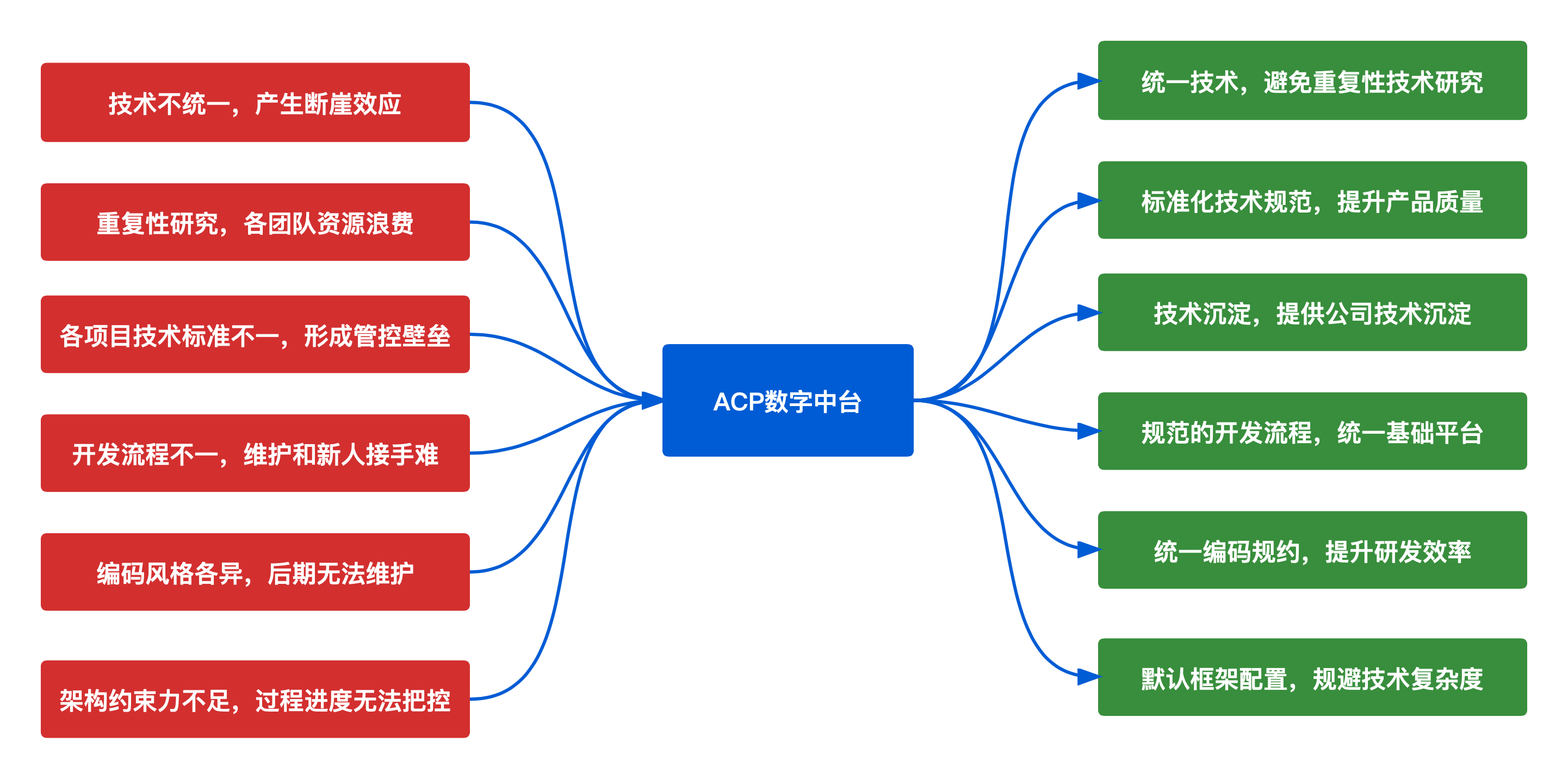
ACP中台是从大的方向上进行了统一,但是在细的技术把控上,会给团队及项目组一定的空间,避免架构过度封装的问题。
解决过程中技术不统一的问题,统一规范和统一团队,统一技术选型,降低学习成本和完善内部技术生态,达到技术方案和组件的复用,专注于业务本身需求,提升业务团队的效率。
消除多团队多项目信息孤岛场景,解决数字化场景
传统的研发平台基于一套代码一个平台,形成多套系统多套基础平台,形成各自孤立的数据孤岛,针对不同的业务,单独维护一套,浪费开发资源而且维护困难,不利于数据的收集与分析,信息孤岛很明显,各个数据难对接抽取,无法或者较难抽取元数据。
针对于上,形成各个部门或者应用形成孤立的一面,更加上外包团队的加入,更加难以统一管理。ACP数字中台,天生的中台架构能力,提取出基础的组件元数据和数据元数据,抽取成中台服务,为业务提供标准的数据接口能力。
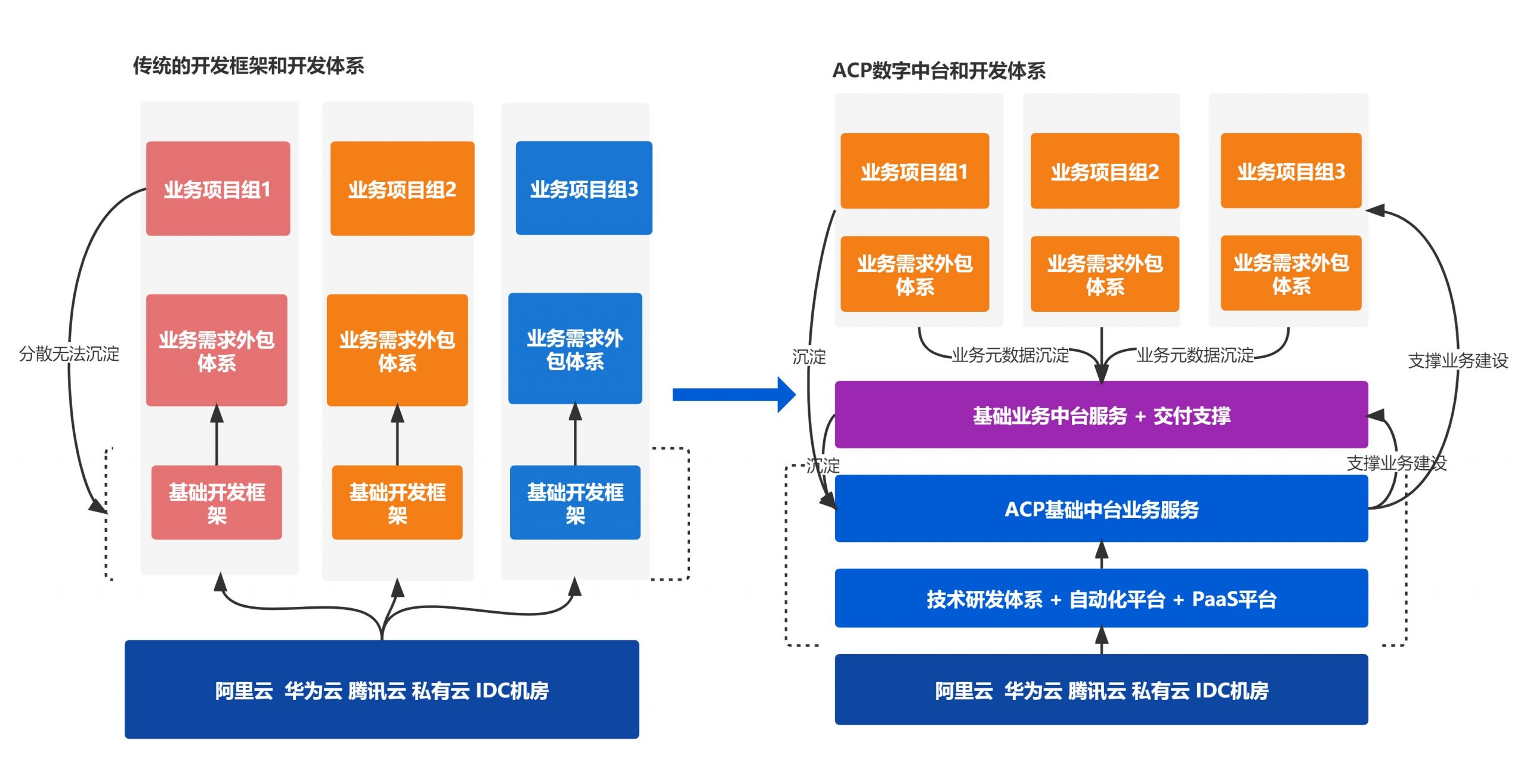
整体架构图说明:
- 传统的开发框架体系不管是技术沉淀和管理模式上,无法避免信息各异的产生。
- ACP数据中台的研发模式基于沉淀的方式,形成信息和数据职责分层 ;
- 中台本身架构,抽取出元数据和主数据元素,沉淀到中台服务,形成数据层;
不管是在物理上,还有逻辑上进行数据拆分 ,统一部门和团队的数据规范和方法,对不同的数据整合,形成统一的规范,利用中台架构,从根本上解决系统建设和业务建设上数据孤岛的问题。
兼容多云平台,PaaS+中台底座一体化集成,解决团队效能问题
对于不同的PaaS平台,多云平台,提供兼容性,包括阿里云、华为云、腾讯云等,提供私有部署的兼容方案,解决云平台配置的问题,基于K8S服务的配置,搭建属于团队自己的容器云管理平台。针对于以上,技术研发体系,针对于中小团队,低成本,快速的整合PaaS平台,如下图:
在统一的流程上,结合中台一体化,形成团队特色的中台服务,解决技术统一问题的同时,更加解决团队效能问题,管理发布升级等问题,多环境(开发/测试/生产/客户)的整合问题,让团队更专注于业务需求的建设,规避技术的坑点。
消除中台化过程中的坑点,功能完善的微服务/容器化/业务集成化等可视化组件
自从微服务和中台化的落地以来,基本上都是基于培训和各个初级的入门培训,由于技术框架的快速迭代,市场教育和培养的周期较难沉淀一套完整的解决方案,形成的是零散的场景解决方案,但是真正在落地中,遇到的问题远不止看到,这里列出部分最常见的:
- 微服务框架的整合是否必须是一整套(是否一定要上微服务);
- 服务之间怎么划分,划分的颗粒度怎么确定,是否有一定的标准;
- 事务消息中,消息的丢失还有消息的管理怎么整合,业务场景怎么消费;
- 多系统接入过程中,是否一定需要配置中心(难道一定需要的么?)
- 多城市场景下,不能满足怎么改造,架构的限制在哪里;
- …..
基于以下种种场景下,ACP数字中台整合建设过程中的问题点,规避过程的复杂性,经历从0到1,大中小项目的整合,多城市多团队,跨部门等经验结合,为团队提供相对的技术方案
通过容器化,可视化的组件管理配置,屏蔽中台建设落地的复杂性和产品化,在开发、服务、数据、运行、运维等多个层面进行了能力聚合,真正让分布式应用的开发做到架构分布、体验聚合。
快速解决团队中台化平台化的问题,低成本快速统一团队标准落地
团队中台化建设和平台化建设,需要投入成本巨大,消耗周期长,团队切入成本高,在这样的高投入情况下,甚至还有可能会失败,形成不了了之的收尾场景,常见的建设面临的困难点:
- 人才招聘难,需要有一定经验的架构师和强有力的落地执行能力;
- 需要解决团队人心的问题,在没有见到结果的情况下,信心很难建立;
- 建设周期长,不同的团队或者大一点的团队,需要解决团队人员培养的问题;
- 不同的地区,不同的背景,在培养完成周期之后,同步要考虑人才流失的问题;
- 在完成一版本之后,问题多无法在团队内部真正用起来,最后形成鸡肋;
- 在没有充分的场景验证下,开发、商务信心和公司信心,各自担忧的问题;
针对于以上种种,ACP平台建设在架构初期,针对于不同的团队,场景进行梳理,形成统一的中台底座,让团队专注于本身的业务需求场景规划和建设上,更专业于本身团队的发展:
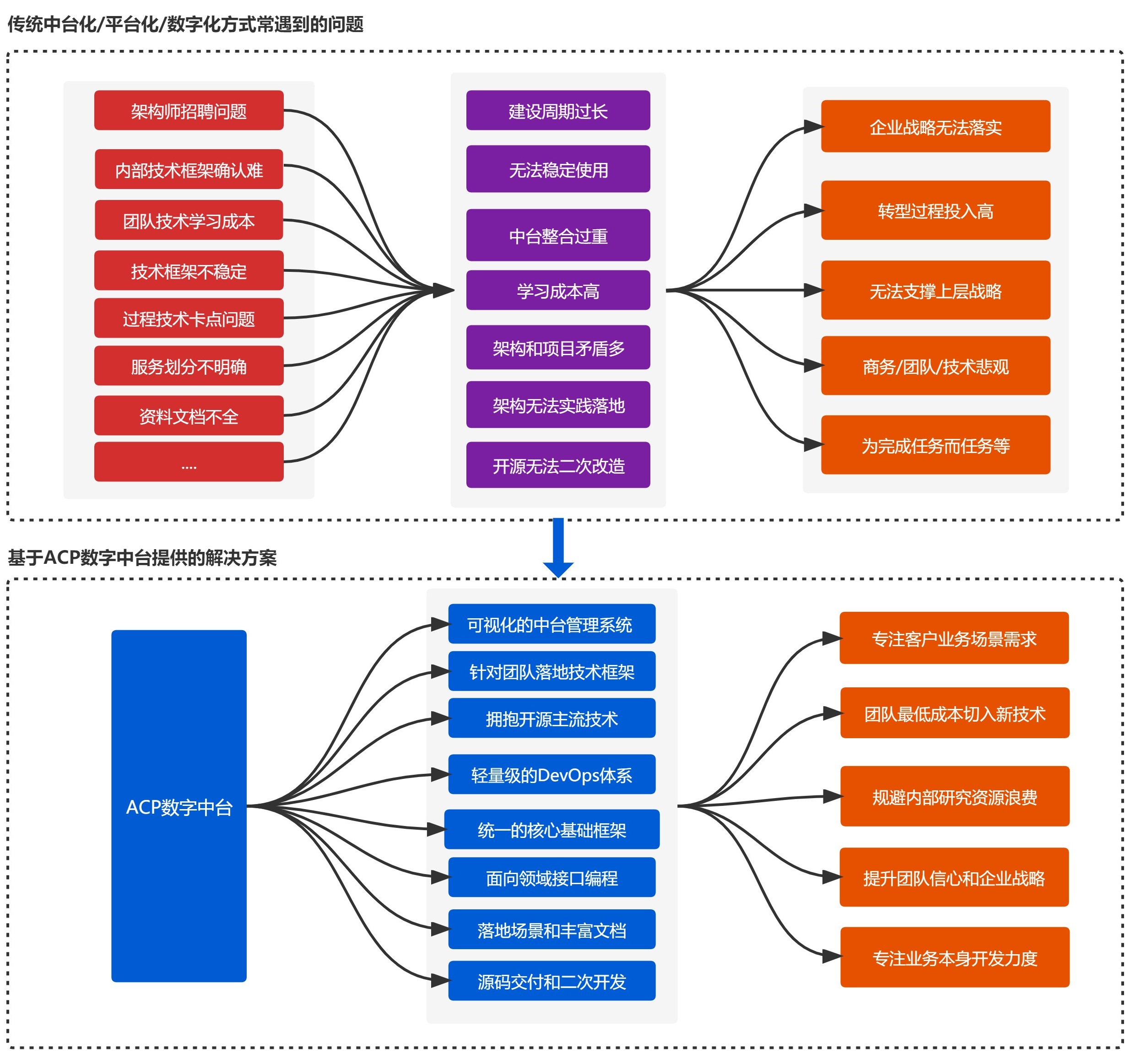
形成丰富的文档和开发示例,输出新人入门文档,解决团队人员成长和切入的过程,梳理出团队成长的体系做为参考,为团队的培养做基础。可以在现有团队的情况下,针对高工(非一定架构师)进行业务二次的调整改造指导和承接,提供专业的技术专家进行过程指导,提供建设咨询和经验分享,解决落地的问题;
中台产品
我们针对的是中小型团队,快速实现中台化和平台化场景,达到团队可控,可管理,为后期业务的沉淀 形成基础,更好的沉淀团队资产,形成团队行业的业务标准和一套解决方案,形成自己的核心竞争力
ACP数字化中台官网:http://alinesno-platform.linesno.com
其它