软件架构师罗小东,多年架构和平台产品设计经验,目前在Agent场景落地结合中。
概述
此为针对于AIP在垂直领域场景,结合开发组、专家组能力进行的场景设计。
这个是一个AIP比较典型的行业垂直领域场景。
工业场景领域很多块,这里主要是针对于工作能源上AI场景的应用探索,与广西斯蓝科技在工业领域上的AI智能体探索与落地,考虑各方,这里做具体场景的规避脱敏,只做技术讨论,不涉及具体厂家及数据。
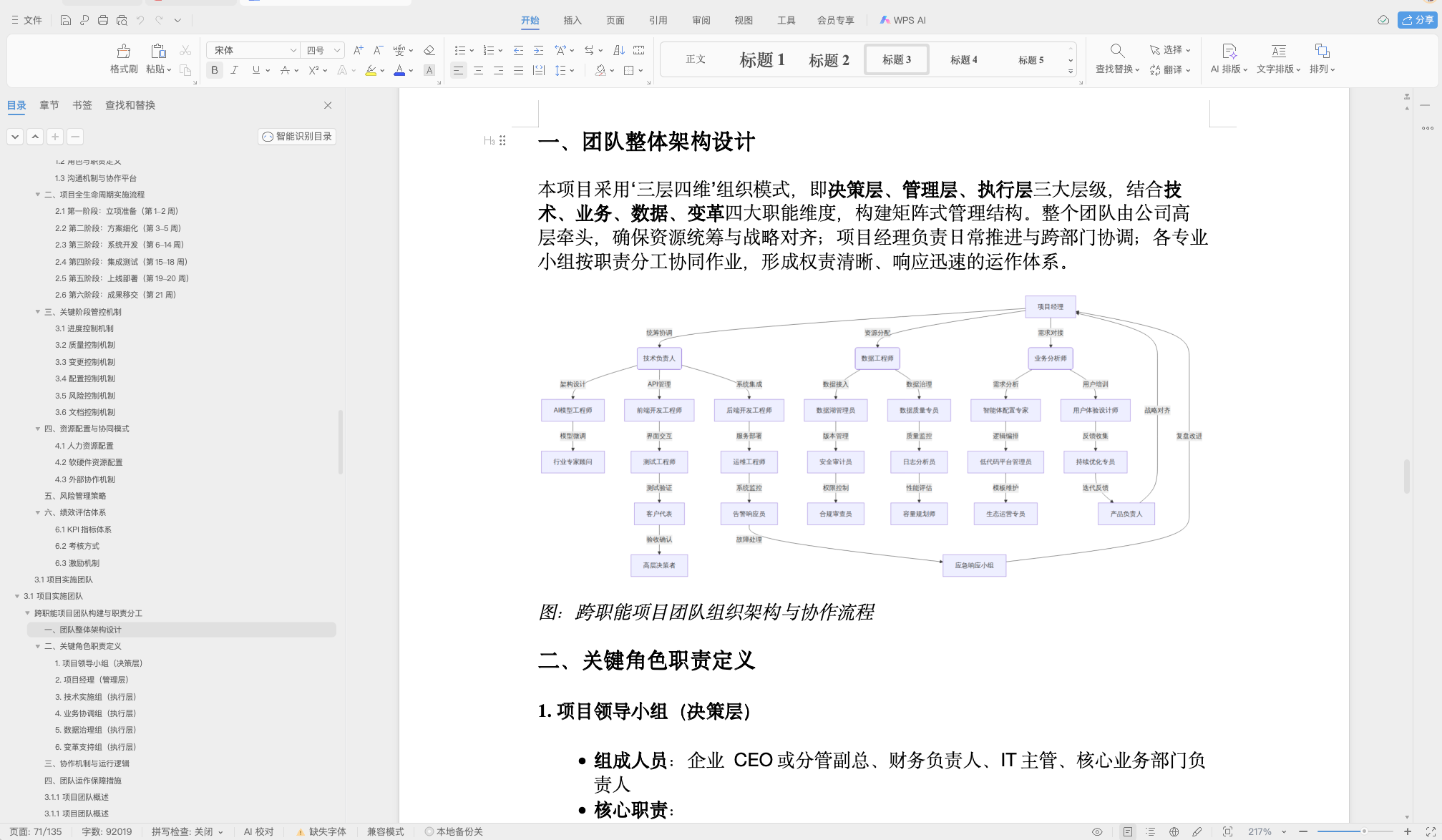
整个从合同鉴定到当前差不多半年左右,属于一期,中间涉及几方,主要包括专家侧、客户侧、开发侧、平台侧,这里属于平台侧,针对于场景提供技术解决方案和针对性做的开发和调整。前期主要遇到比较明显的问题和需求,这里主要列出以下几点:
- 数据问题:能源型的数据量大,数据复杂,而且各方来源数据格式不一;
- 政策问题:行业领域要求政策或者相关标准会变动,各方面数据需要及时更新;
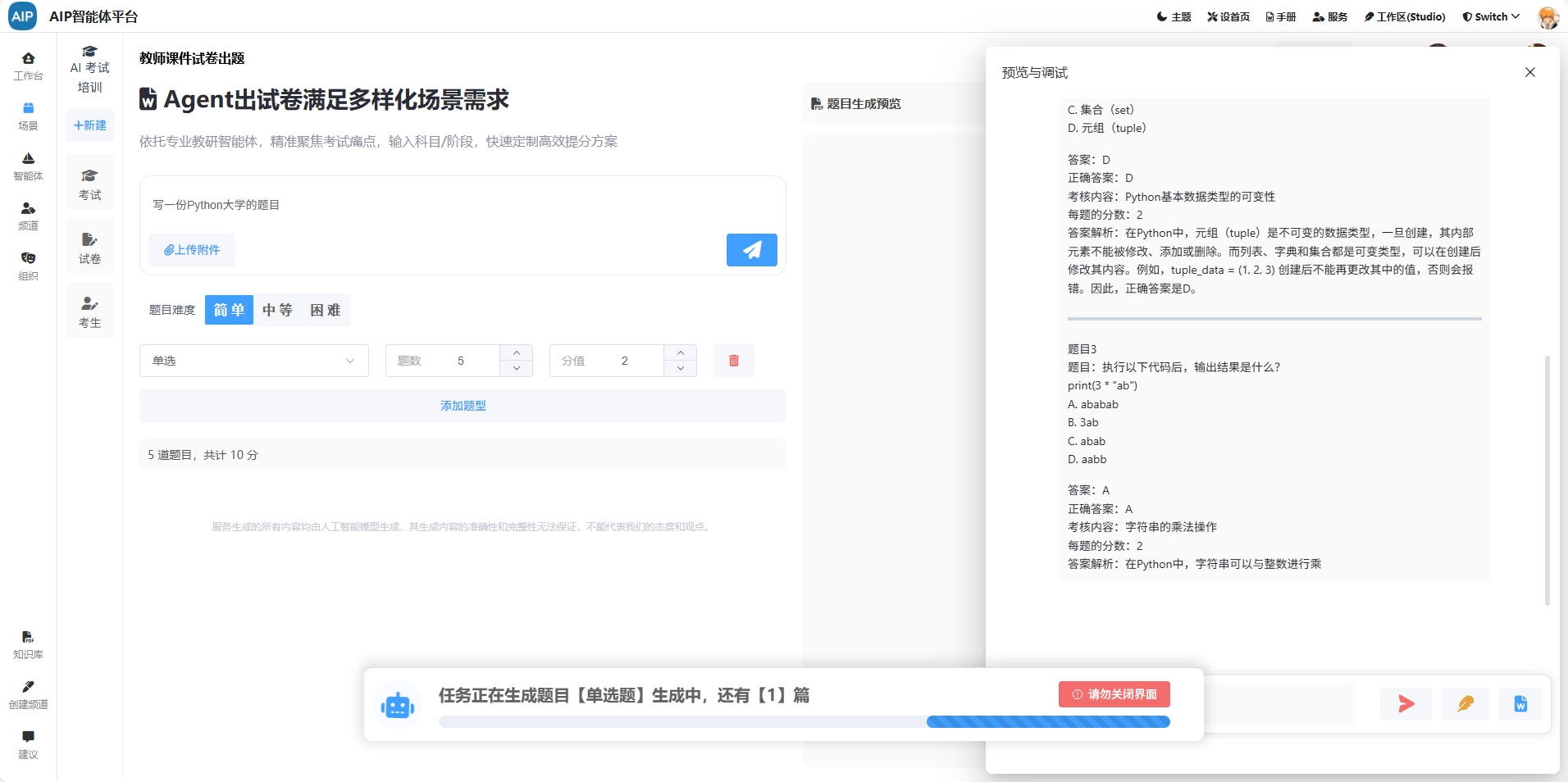
- 开发问题:特定行业的展示需要比较清细的数据,过程计算需要准确,而且计算过程结果要准确;
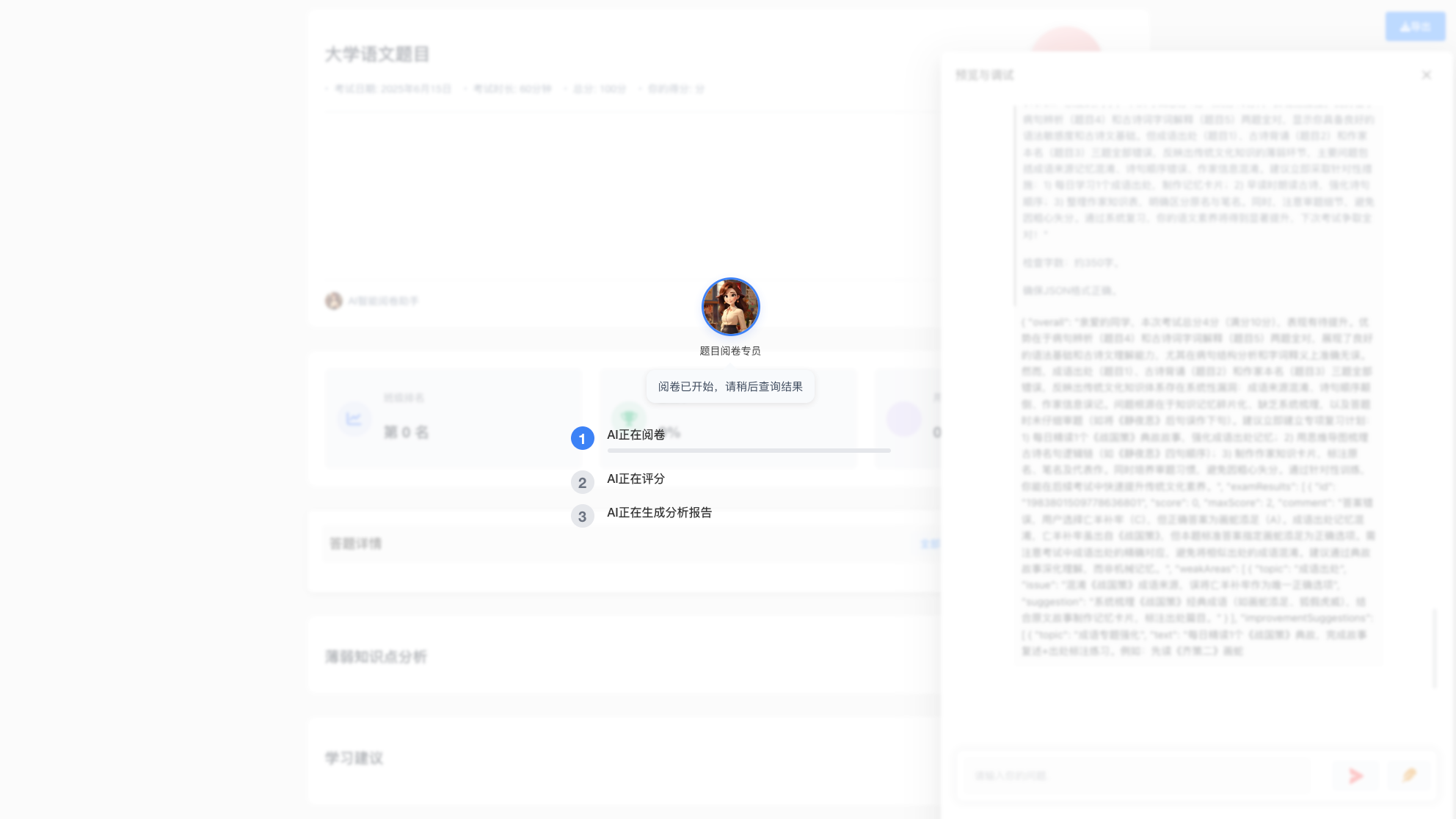
- 模型问题:幻觉始终会存在,计算报告产出需要可以了解到整个上下文计算过程;
….
这里解决的方式有两个方面针对的是智能体上下文处理、知识库处理、数据的清洗处理、还有推理工具集成,另一个是行业算法模型、AI场景自定义等,主要的目的是尽量和接近于专家场景和能力,达到一定的实用价值。这里处理过程涉及,我们从下往上阐述:
- 行业领域政策和相关标准数据采集清洗,结合行业领域数据清理和更新的处理
- 能源数据的数据治理和清洗、还有数据的转换处理,同时提供出给上层AI智能体使用
- AI与算法计算过程的显示记录和最终结果展示处理,反馈给专家侧
这里有一定很重要的考虑是”轻”还有快,以进一步的中小型企业的AI落地和场景结合,以上为当前与工业场景能源域的一些处理过程 ,同时过程也与行业专家进行交流,每个设计师有自己的解决方案,我有我思。
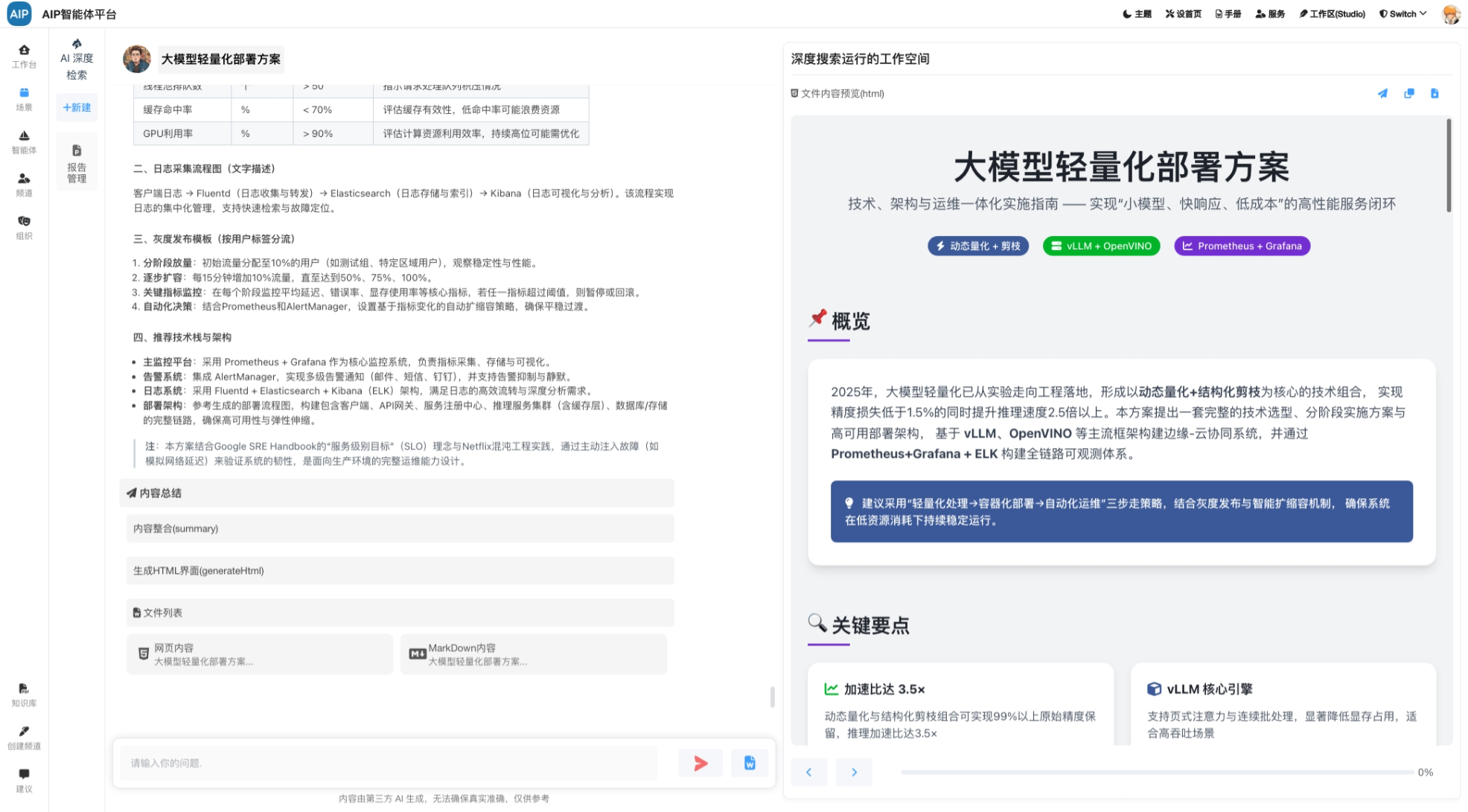
建设内容
以下涉及图片不涉及真实场景数据
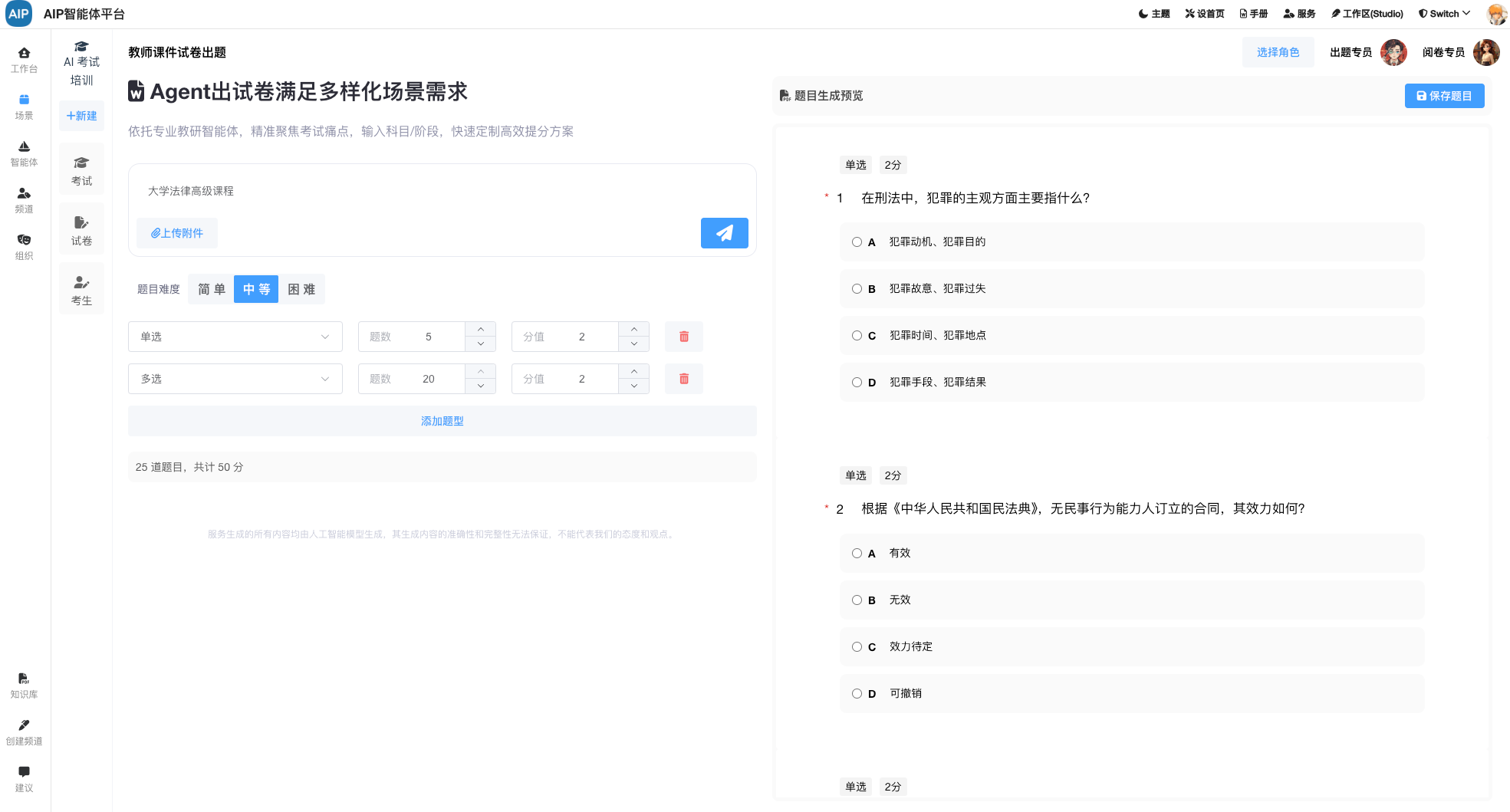
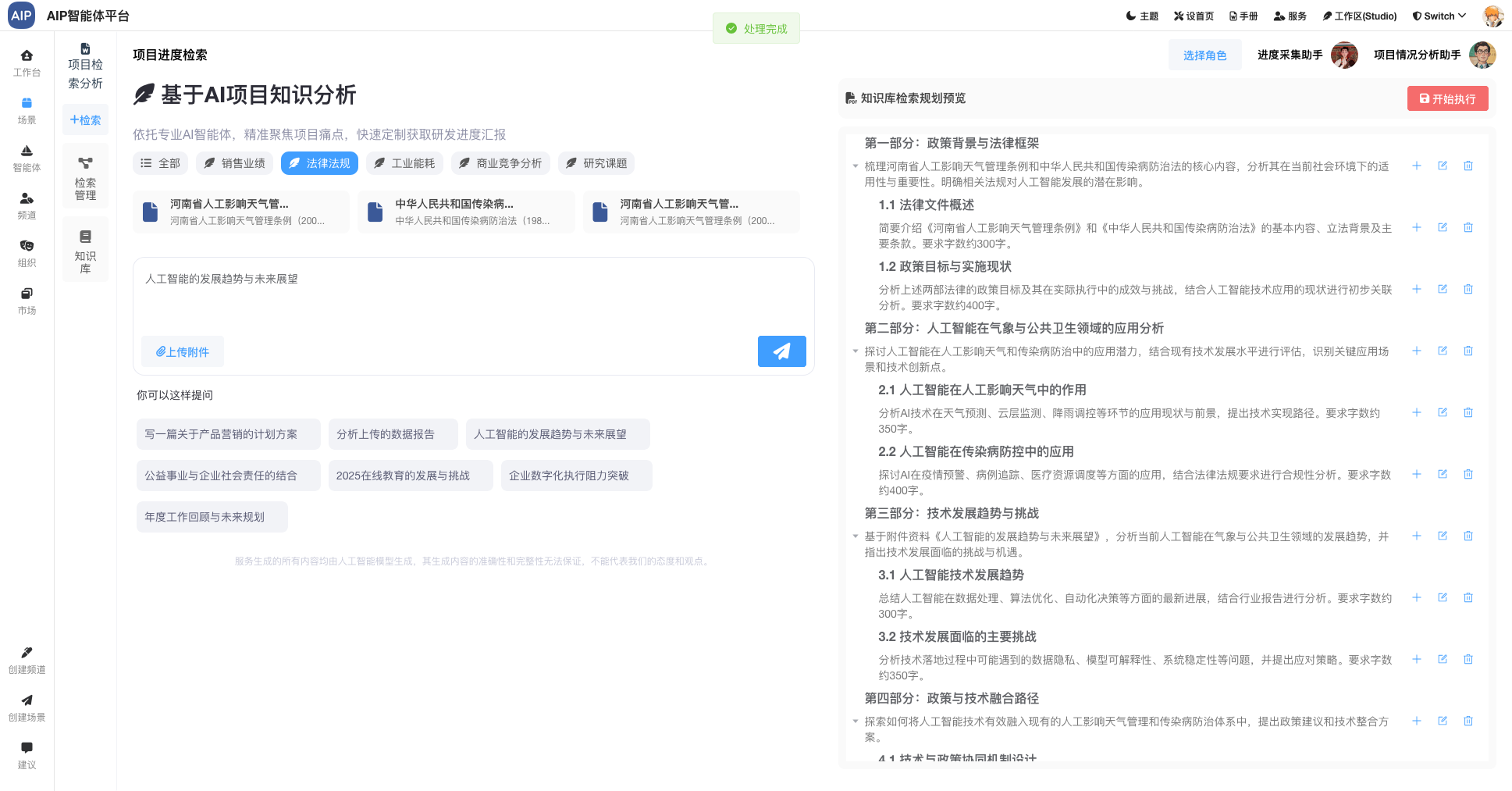
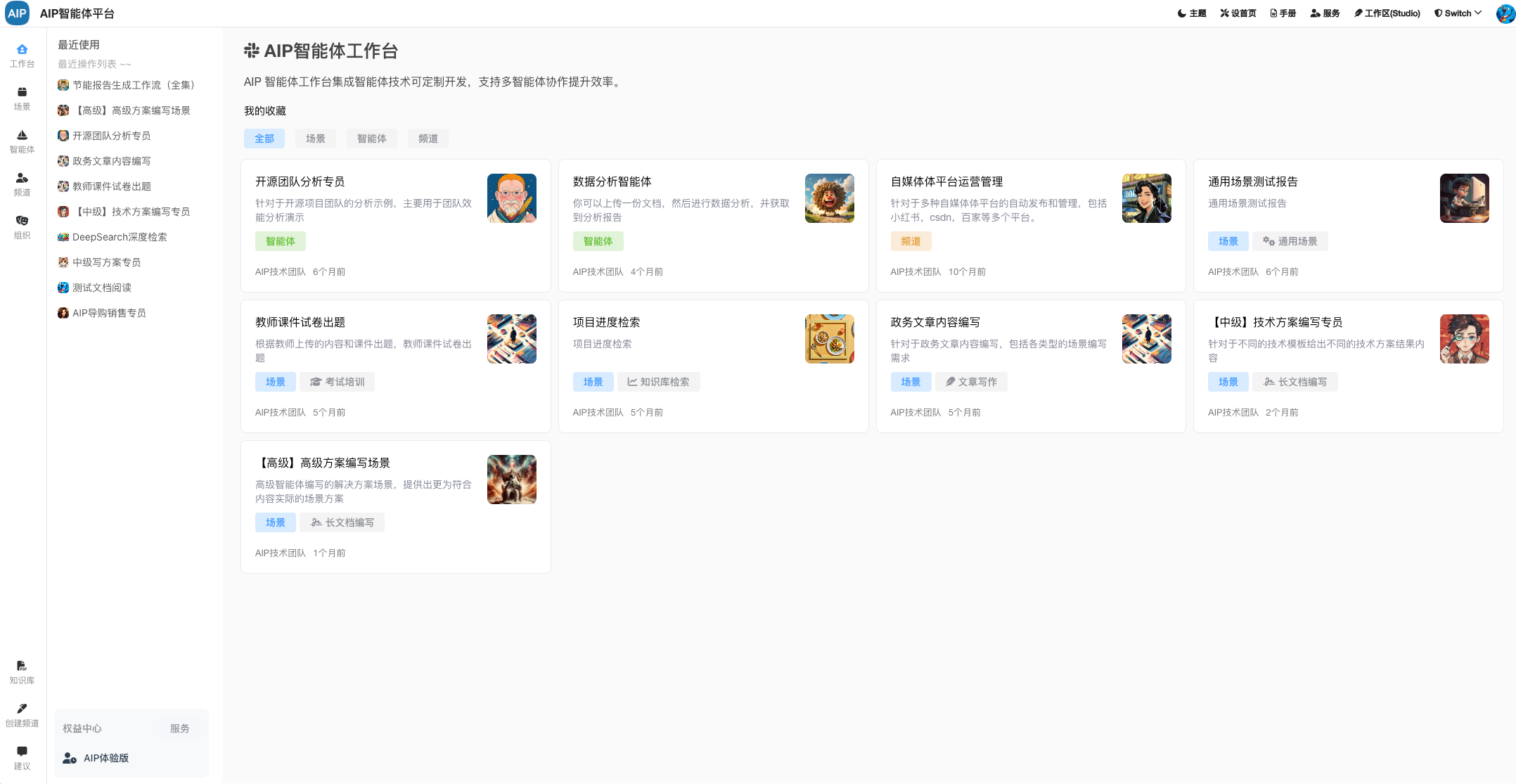
基本的建设过程,主要针对于工业能源领域多源数据,包括能源消耗、政策执行、产品排放等数据结合,同时与AI结合,整理出对应的动态监测、监查报告、场景知识库等AI能力。
数据处理
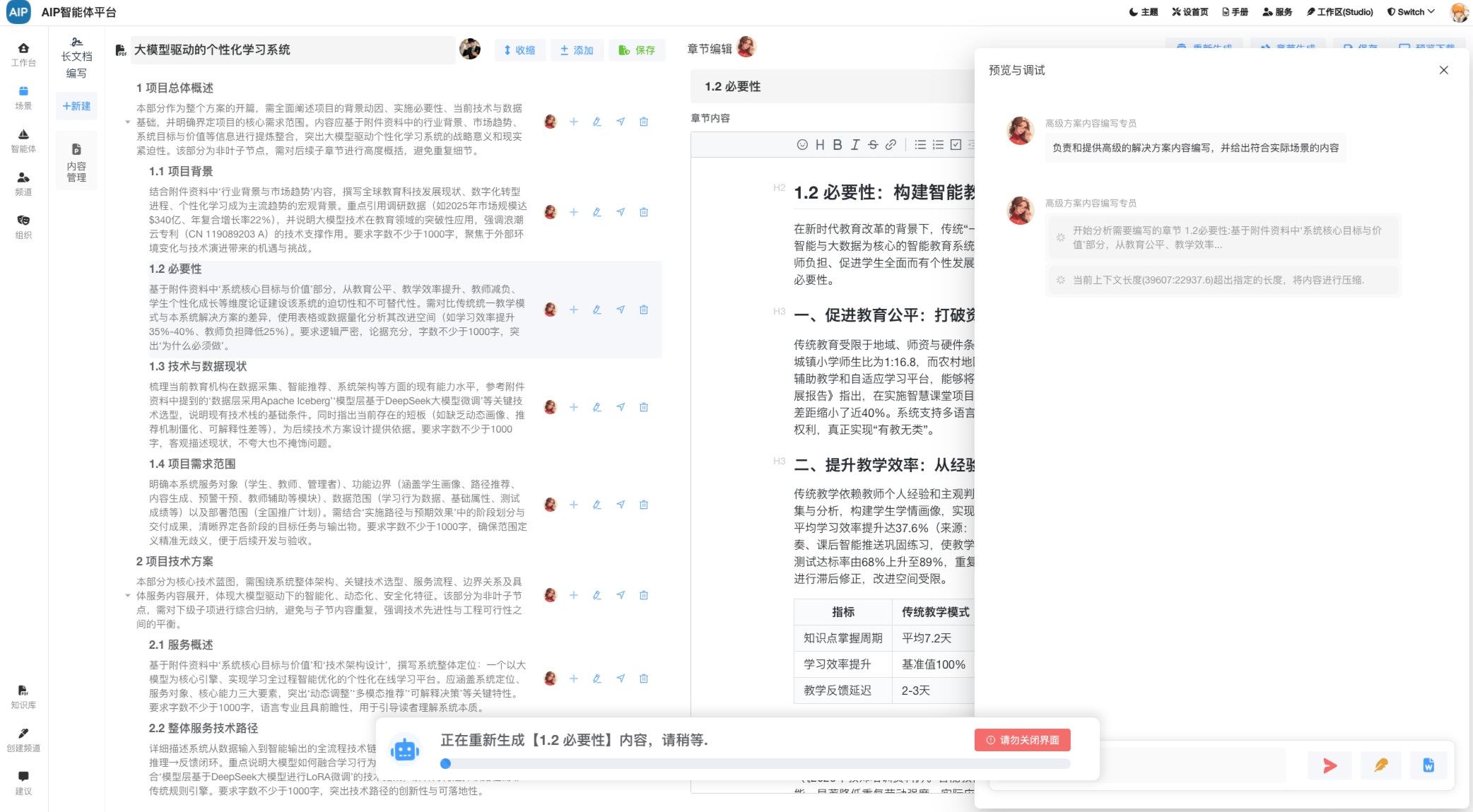
针对于AI的数据处理,这里并不单纯是以RAG为基础,在这里的设计主要包括文档材料、网络材料、行业数据、政策数据、还有各类型的算法公式,来源数据场景分析。
多源数据处理更偏向于数据治理层面,但是数据中台偏重,成本过高,技术及维护难度大,并不适合中小型项目及AI的轻量化,在这里处理的方案是:元数据管理+数据仓库+数据资产 的设计方向,技术为湖仓一体化 iceberg + spark + minio的轻量型技术,针对于解决TB级数据,做到成本可控、中小规模、低成本、快速落地的湖仓一体化。大致的划分如下:
- 元数据管理:这里主要是做所有过程的元数据、分类、空间、还有表等进行的统一管理
- 数据仓库:使用分层计算流程,基于pyspark能力,最终输出使用层数据
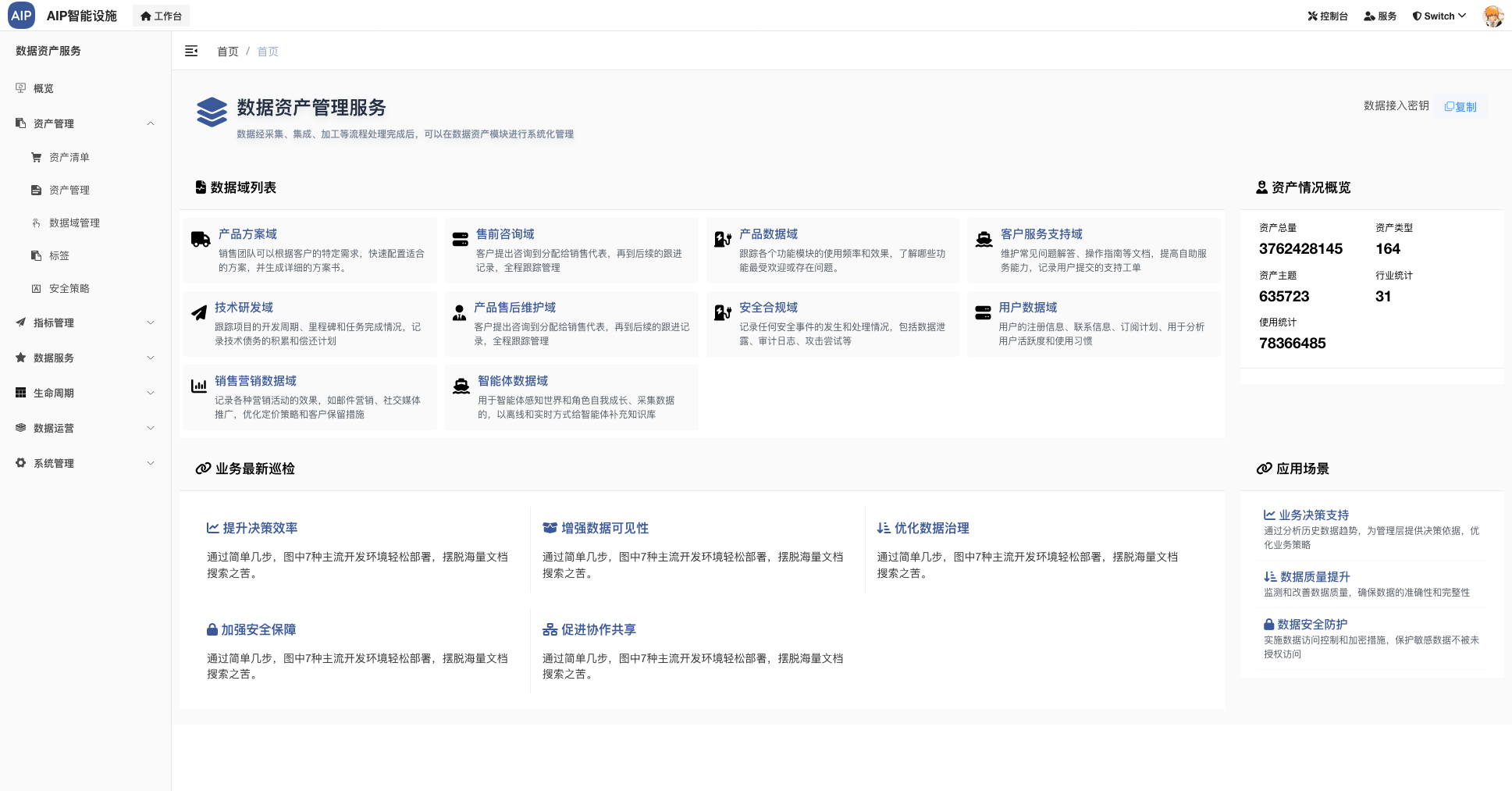
- 数据资产:针对于数据的使用与管理,包括分类分级、安全接口、提供API或者接口能力等
除了上面的,还有抽数据、采集等控件,周边功能这里不做阐述,最终AI会与资产层数据进行交互,形成AI能力的动态知识库。
以下为元数据的非结构化管理及分类:
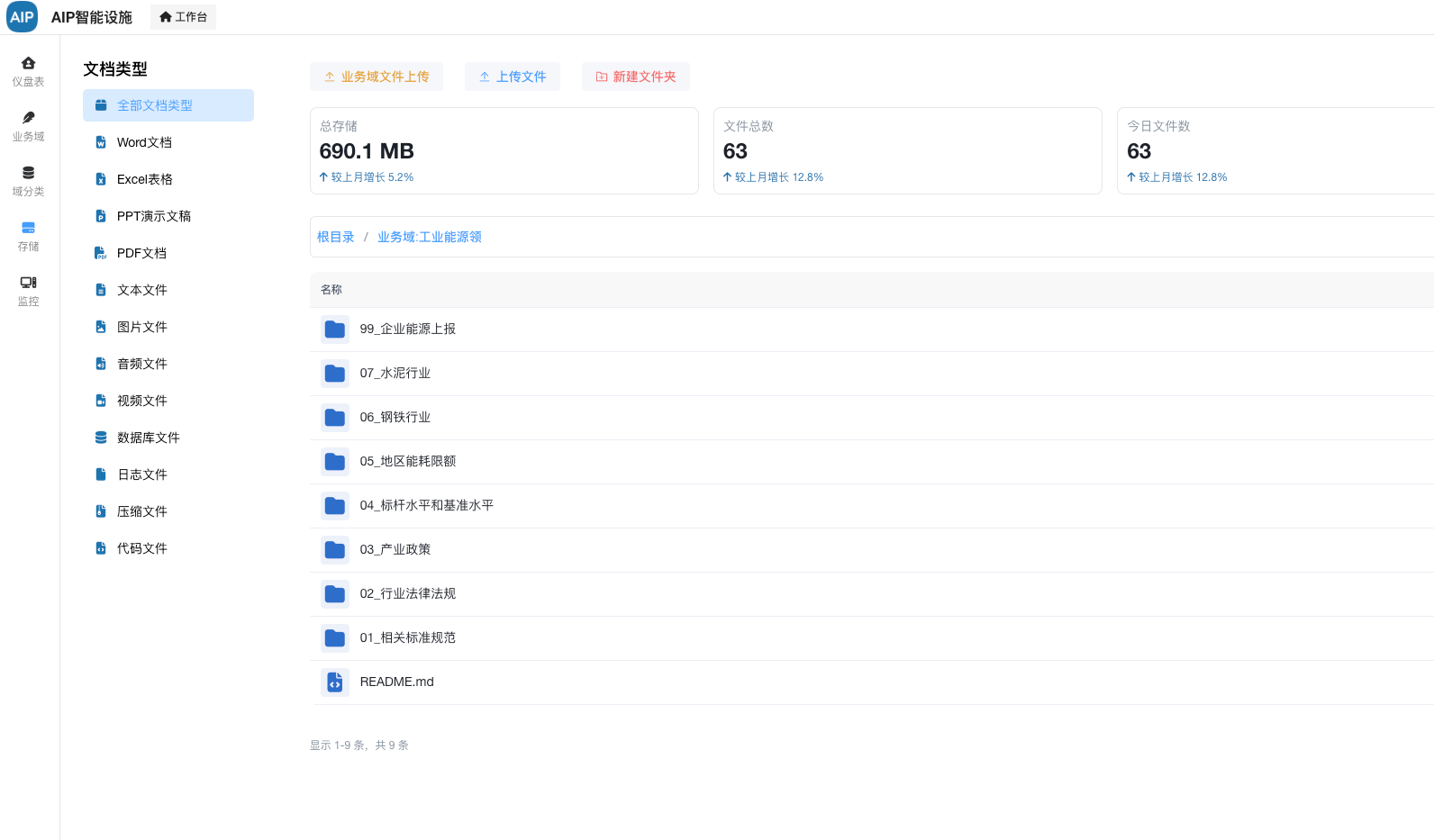
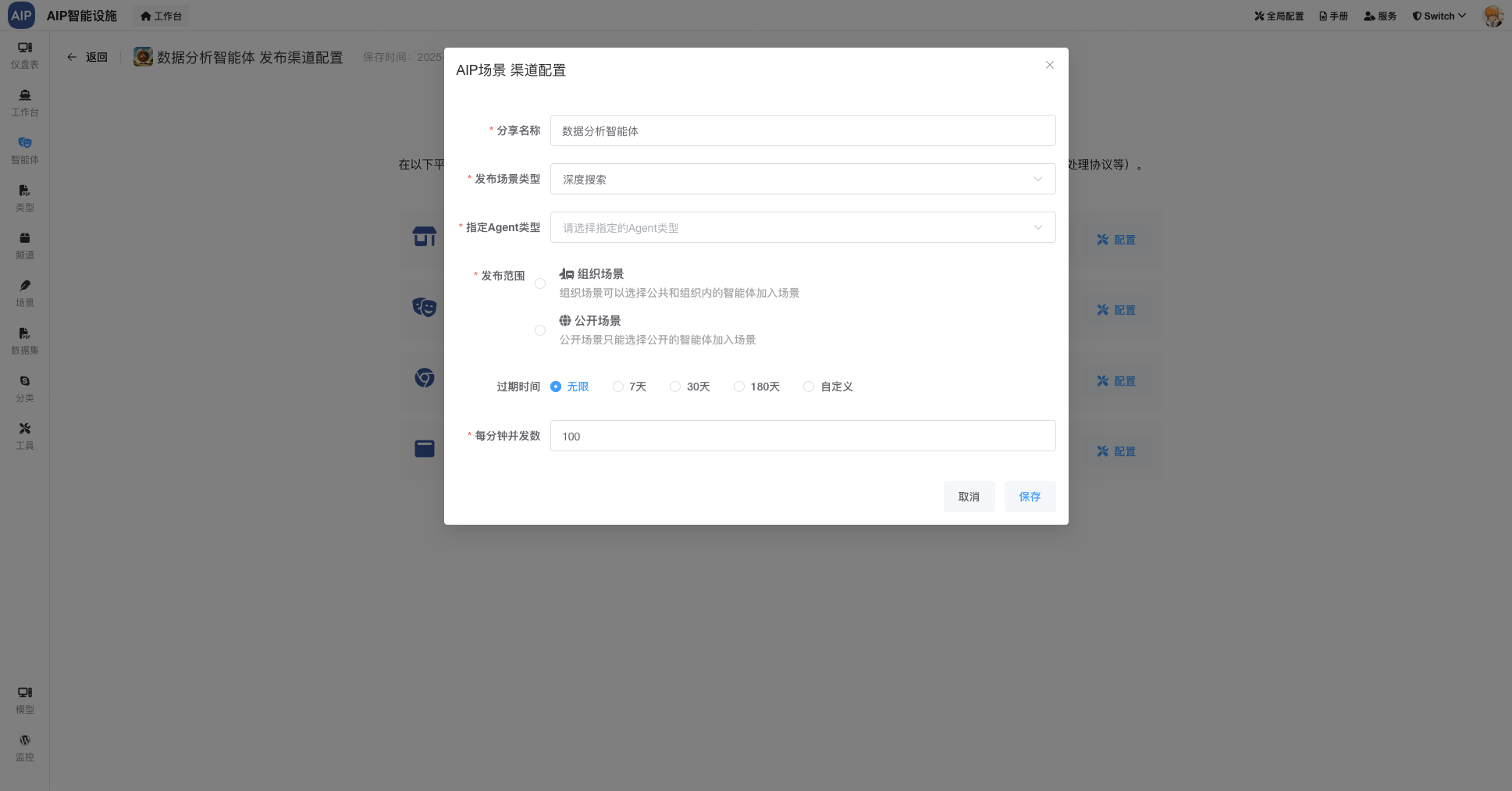
用于管理非结构化数据,在AI场景下会有大量文档类材料,为了更好的管理与维护。
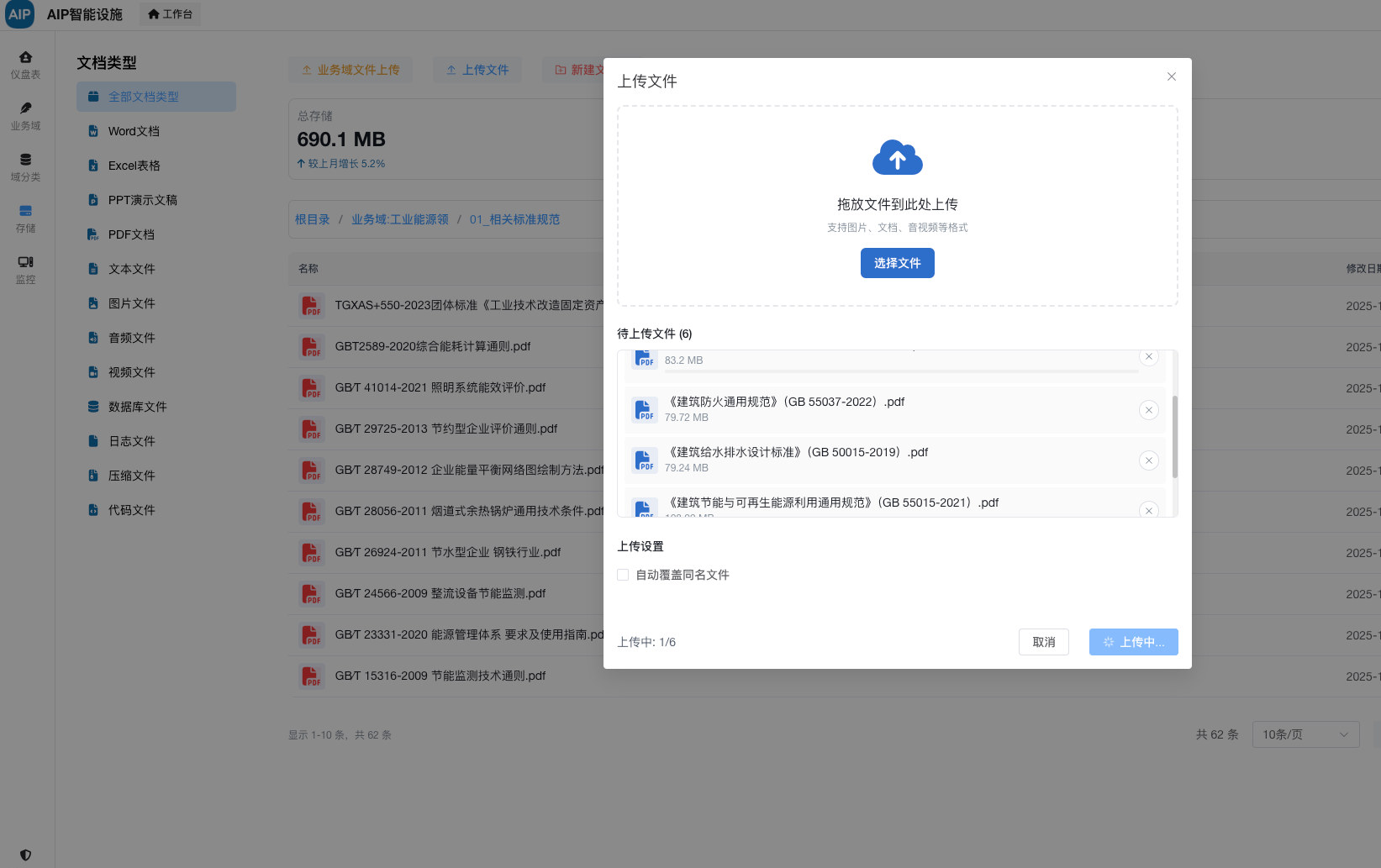
非结构和半结构化的管理主要是针对于一些业务数据上传或者文件类上传,这里做了分类规划。在这个基本上,进行AI结合数据计算,并使用数据仓库分层治理,下面是分层仓库及对应的层级关系:
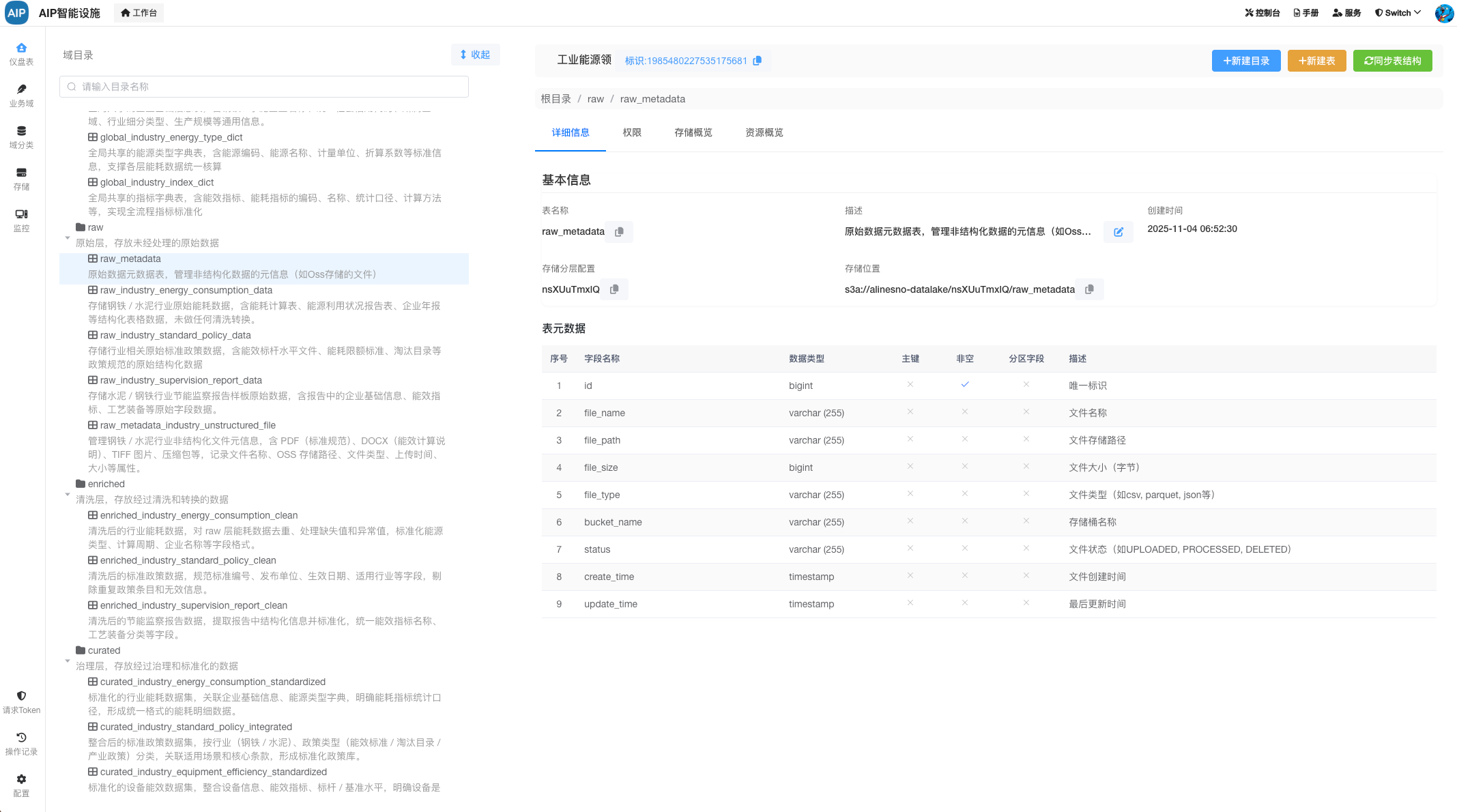
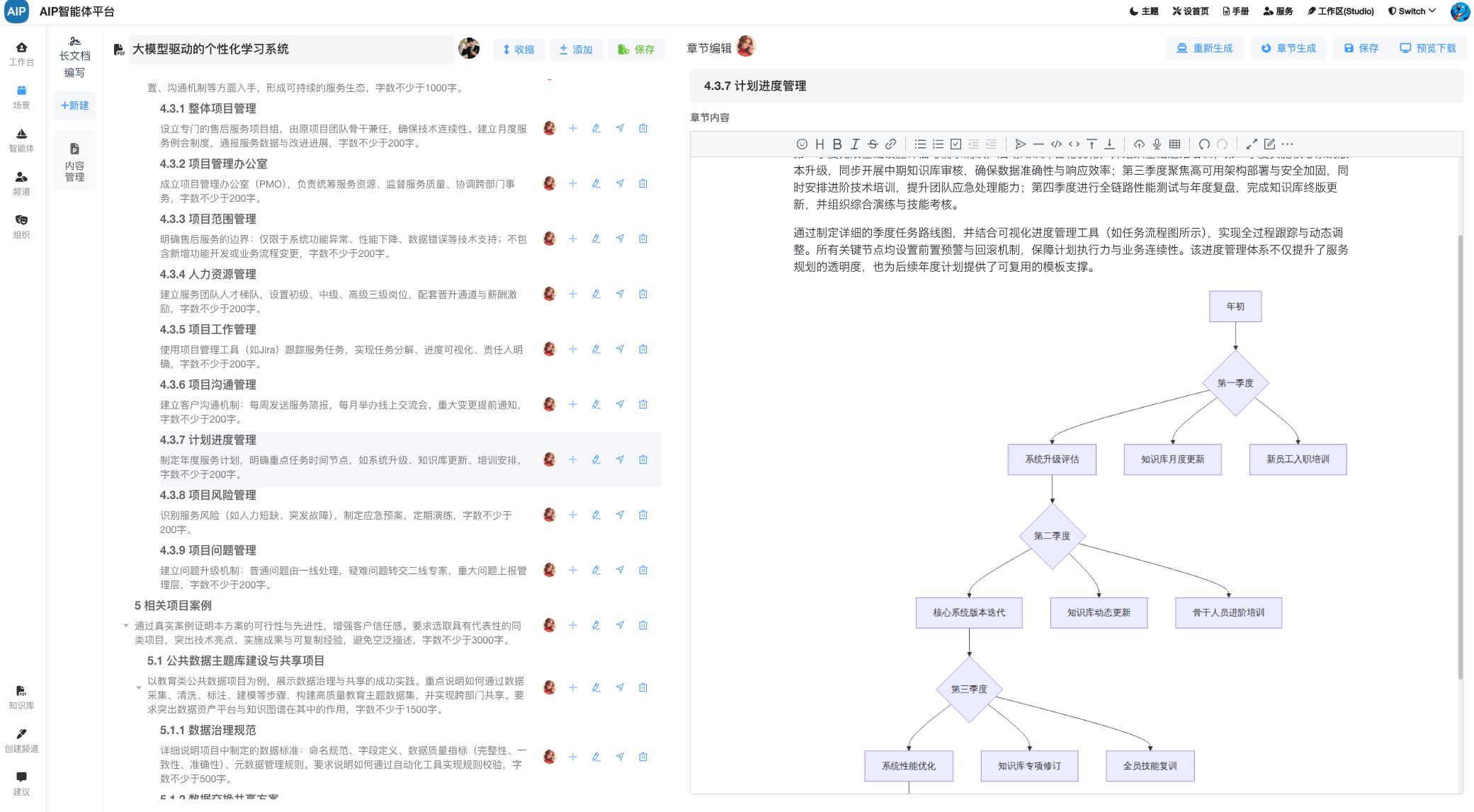
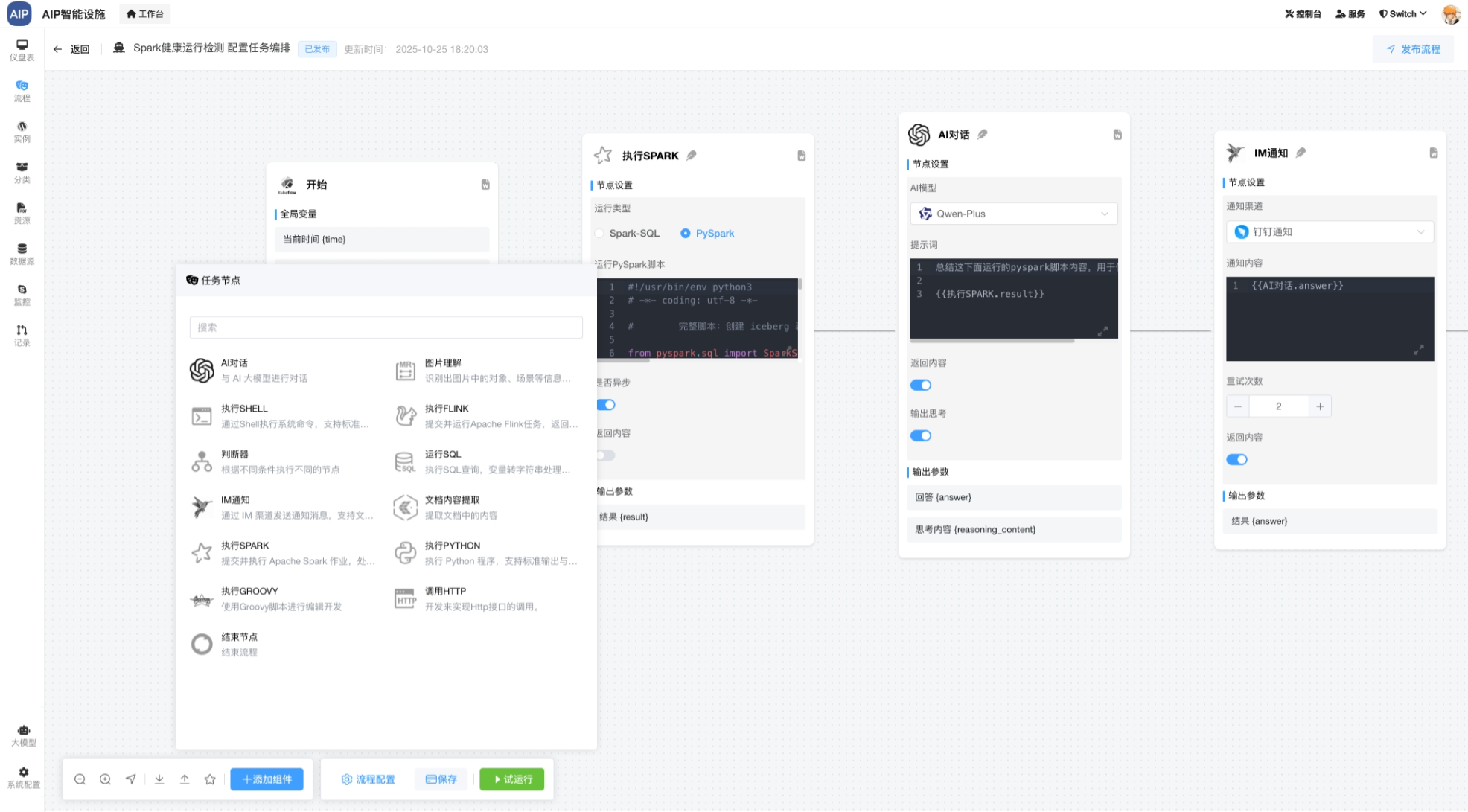
下面是整个计算过程,这里是开发最新的AI任务编排平台(主要考虑到中小型场景及轻量化)进行任务的管理与编排,类似于DolphinScheduler,但是这里集成了AI的能力和排队的能力,就是数据在处理过程中,同样可以结合AI一起,而不再是单纯的SQL处理。
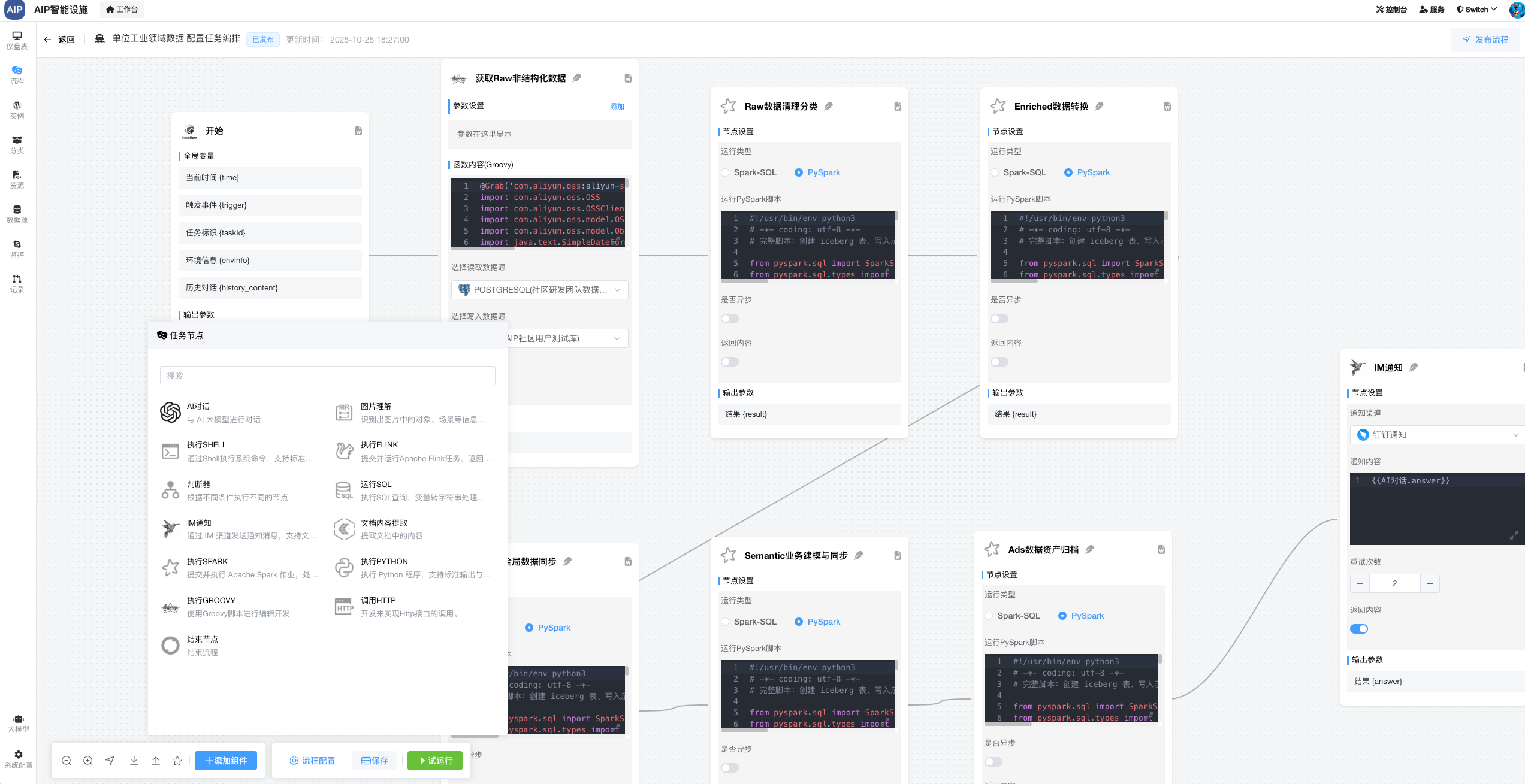
这里就是基本上的湖仓结合的处理,最终数据的流向会写入数据库中,数据资产平台进行标签化、在处理后的数据资源列表上进行分类分级、并提供出服务接口。
补充数据资产图
通过上面的方式,主要解决掉的是非结构化、结构化、大数据量问题、行业领域政策和相关标准数据更新问题,主要为AI能力建设做准备,同时也是AIP下一步可信数据飞轮做好基础。
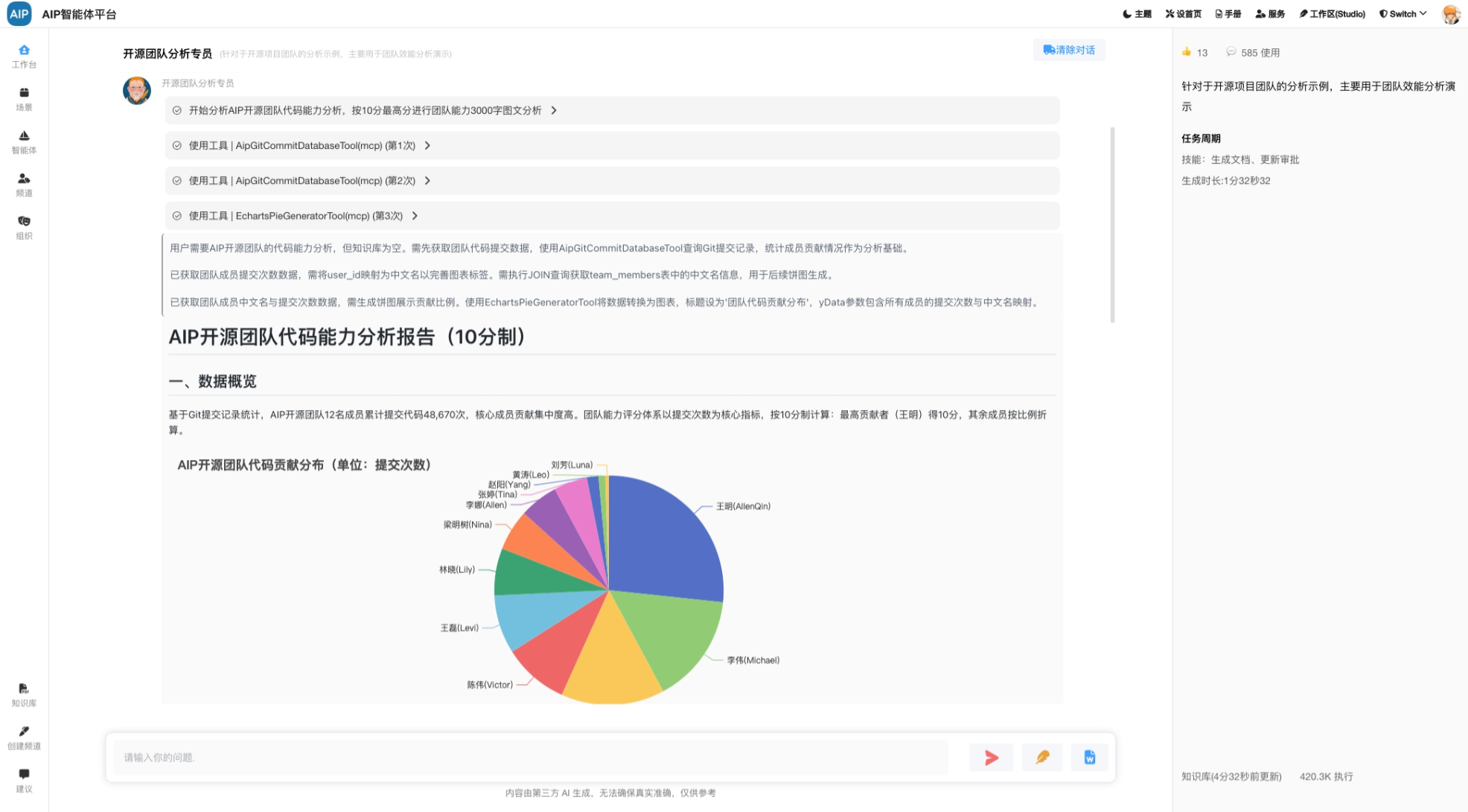
业务场景与AI结合
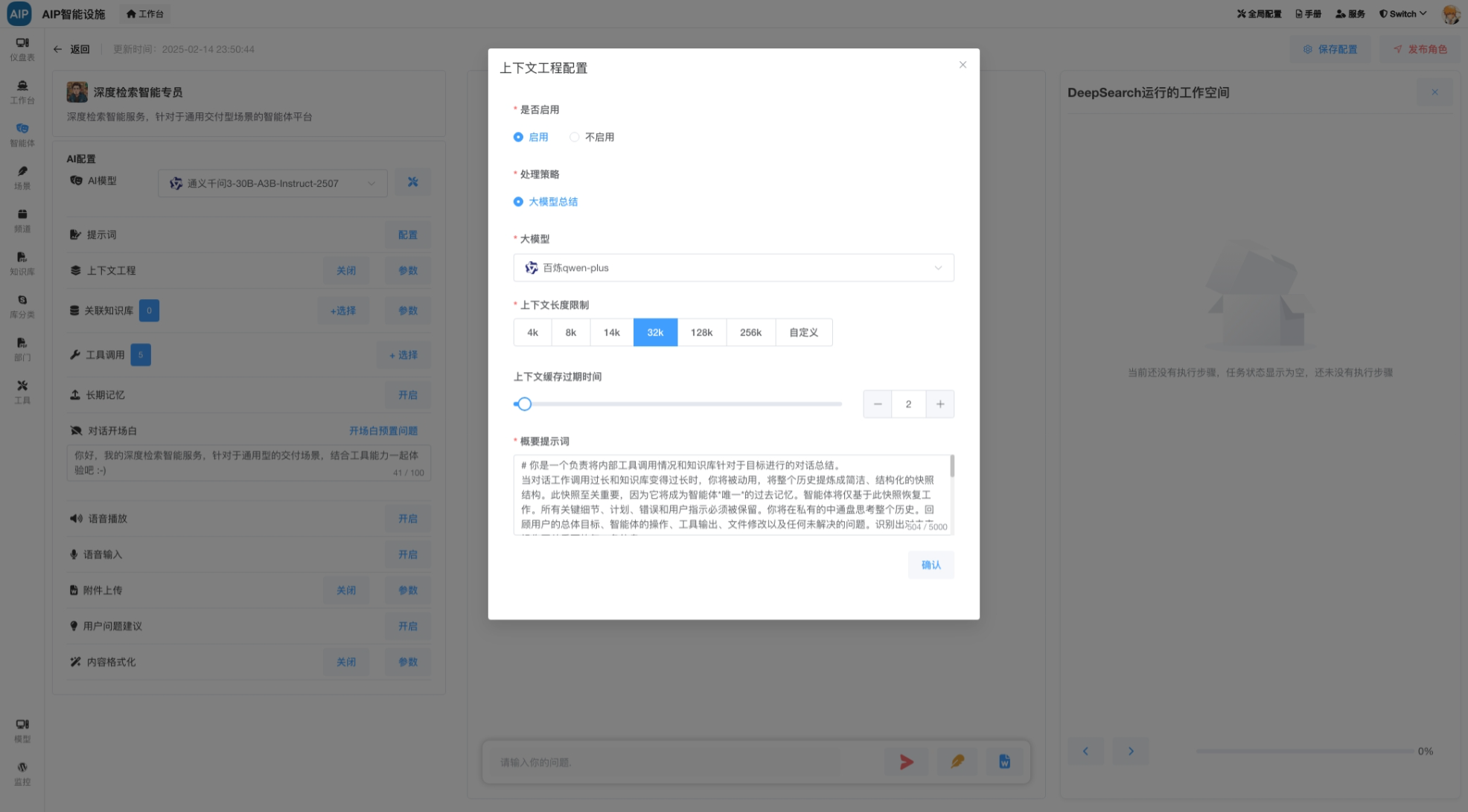
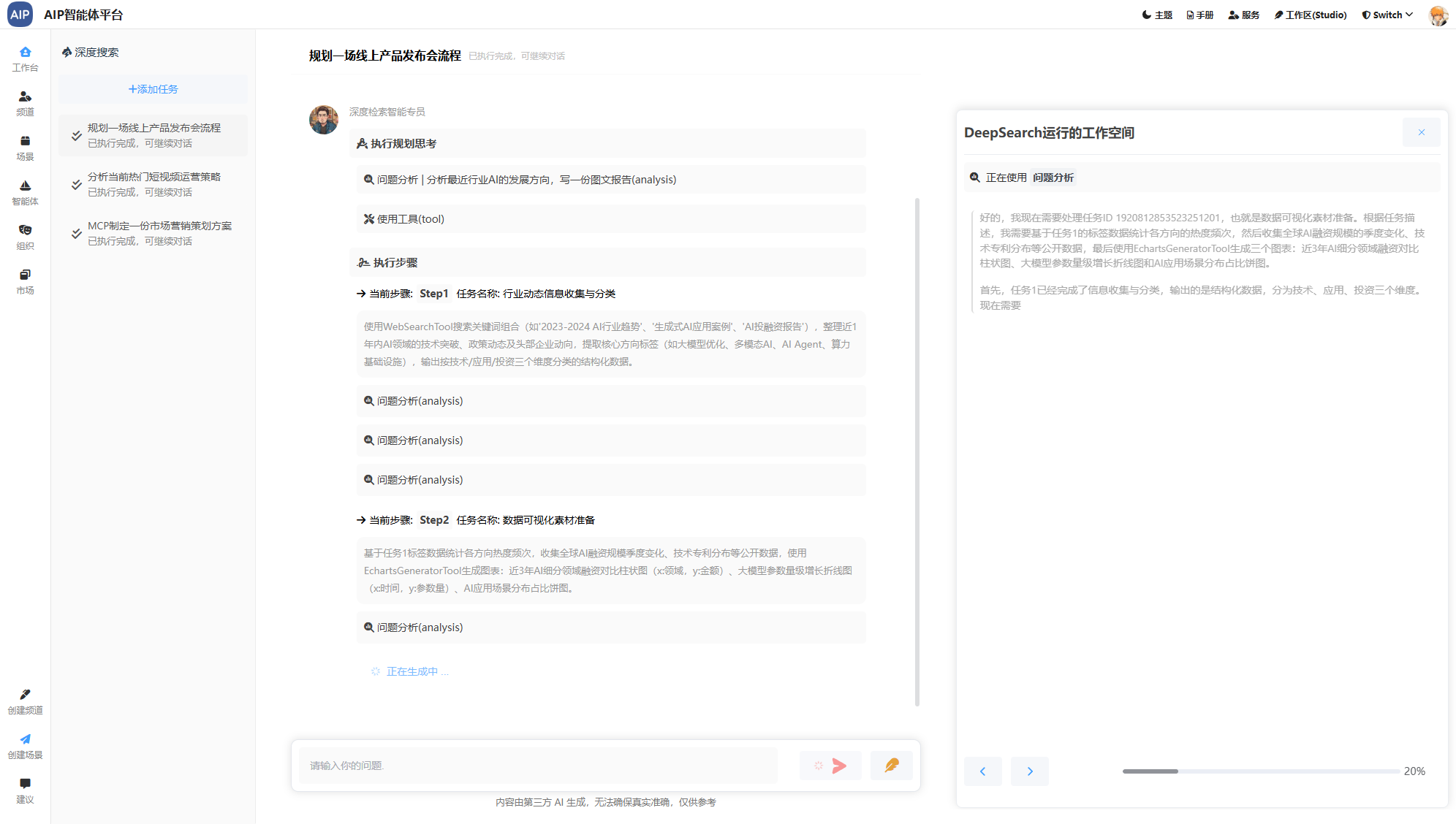
数据与AI结合的方式及表现形式会有多种,AI场景化比较丰富,除了基本的知识库、工作流、AgenticAI以外,还有搜索场景(类似于DeepSearch),结合的方式有MCP方式、向量化、全文检索、上下文工程、还有数据库方式。
上面的处理方式只是偏向于一种AI智能体的技巧,最终的目的是为了得到符合要求的输出结果。
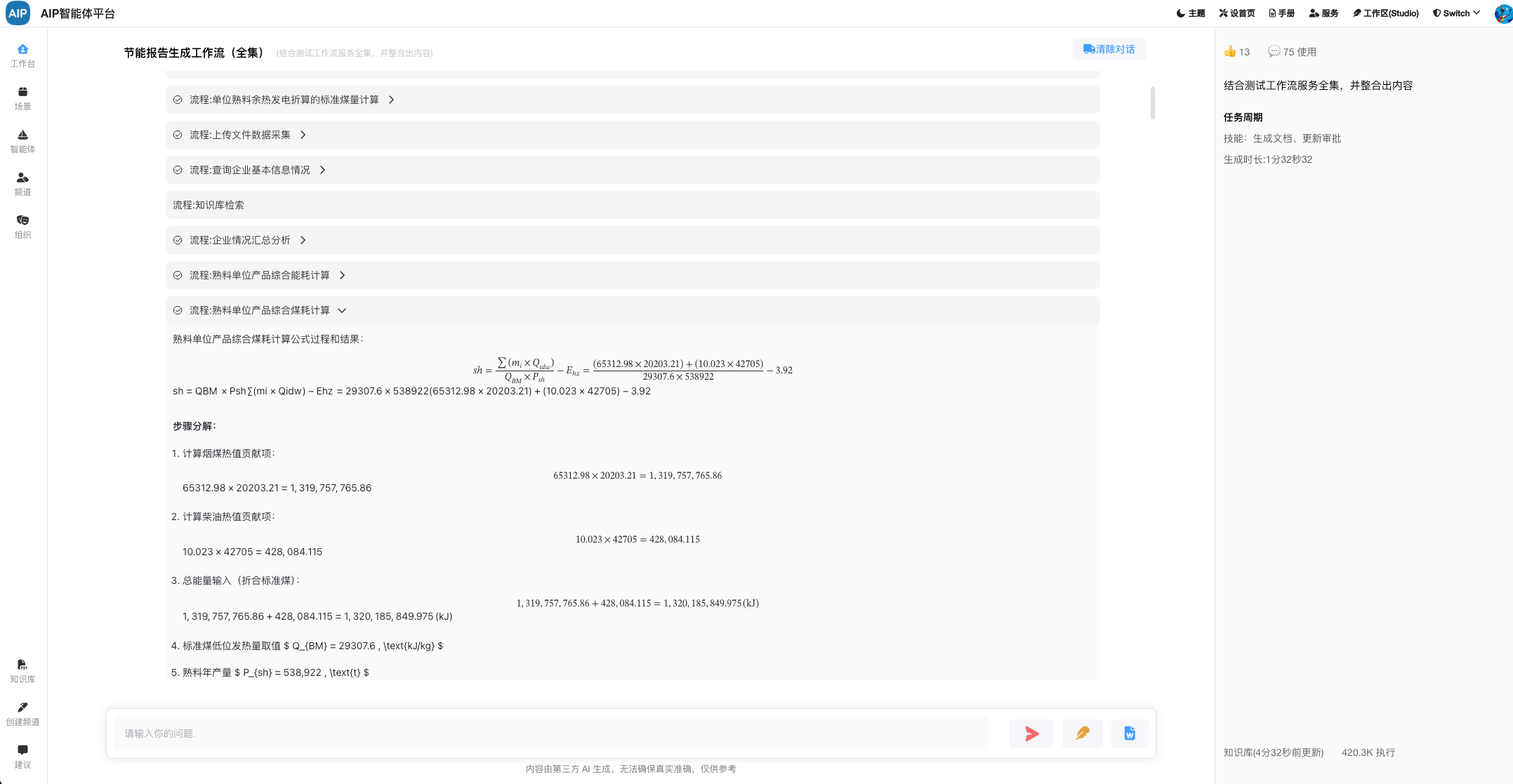
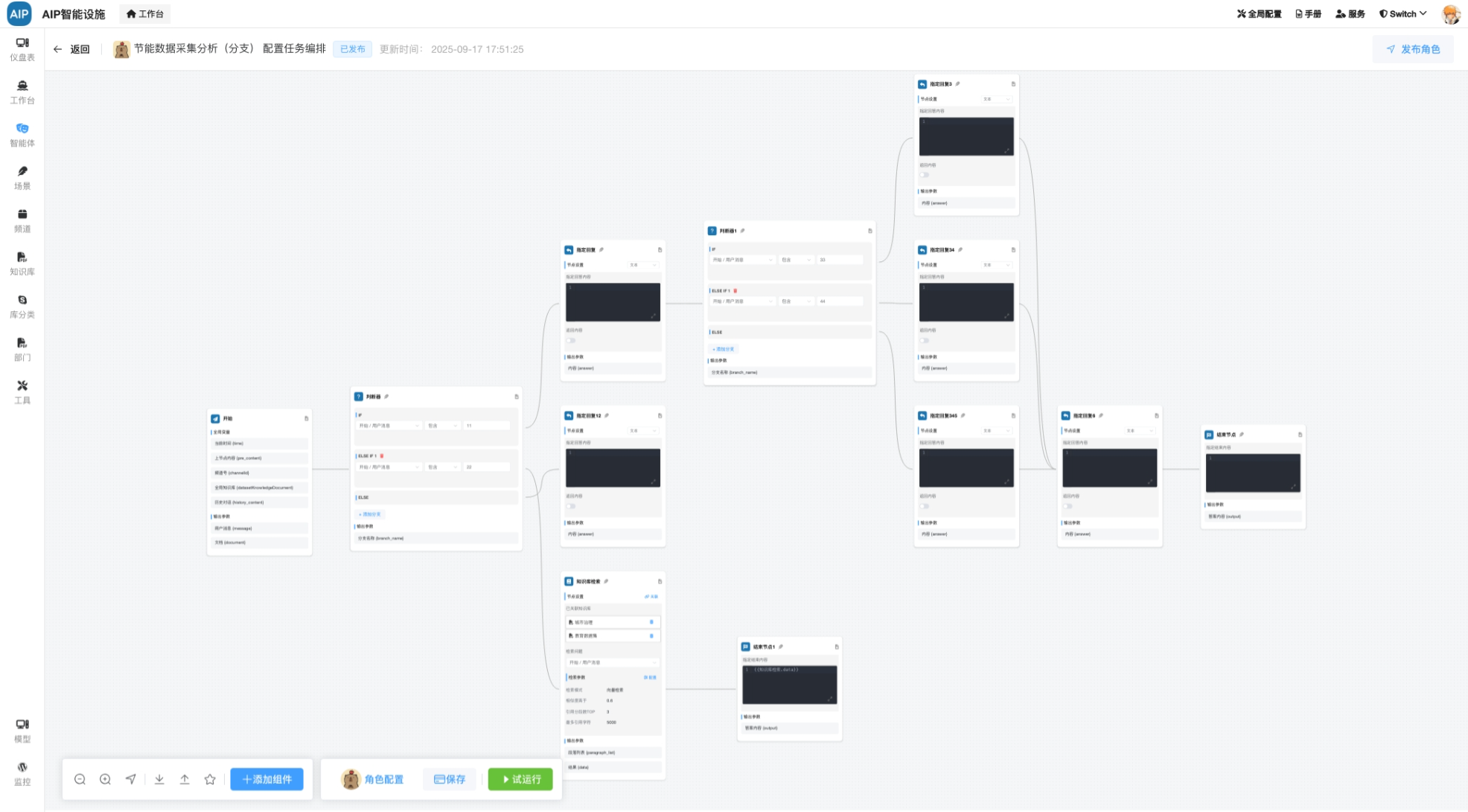
这个在有了初步数据能力情况下,AI智能体流程自然而然走下来。
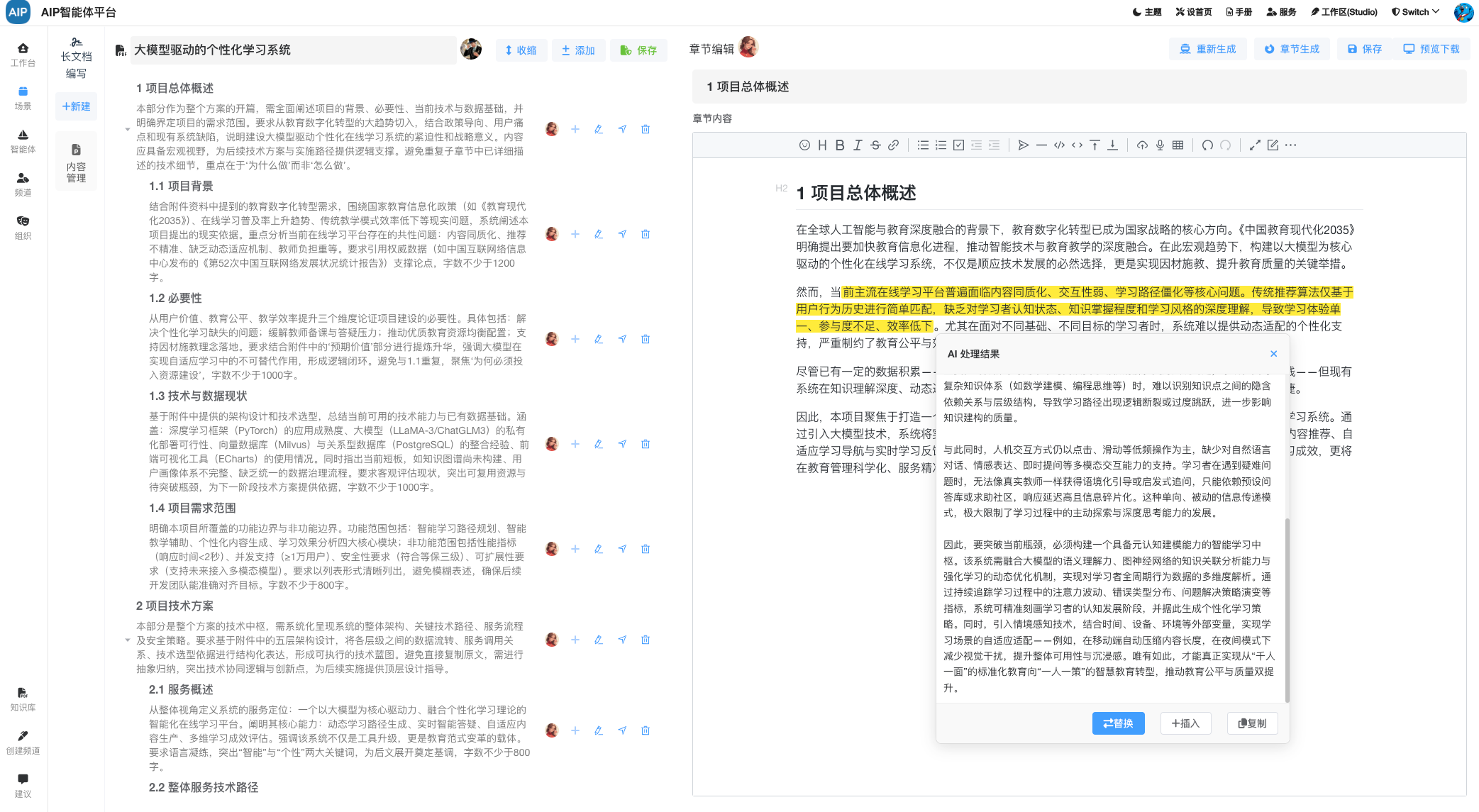
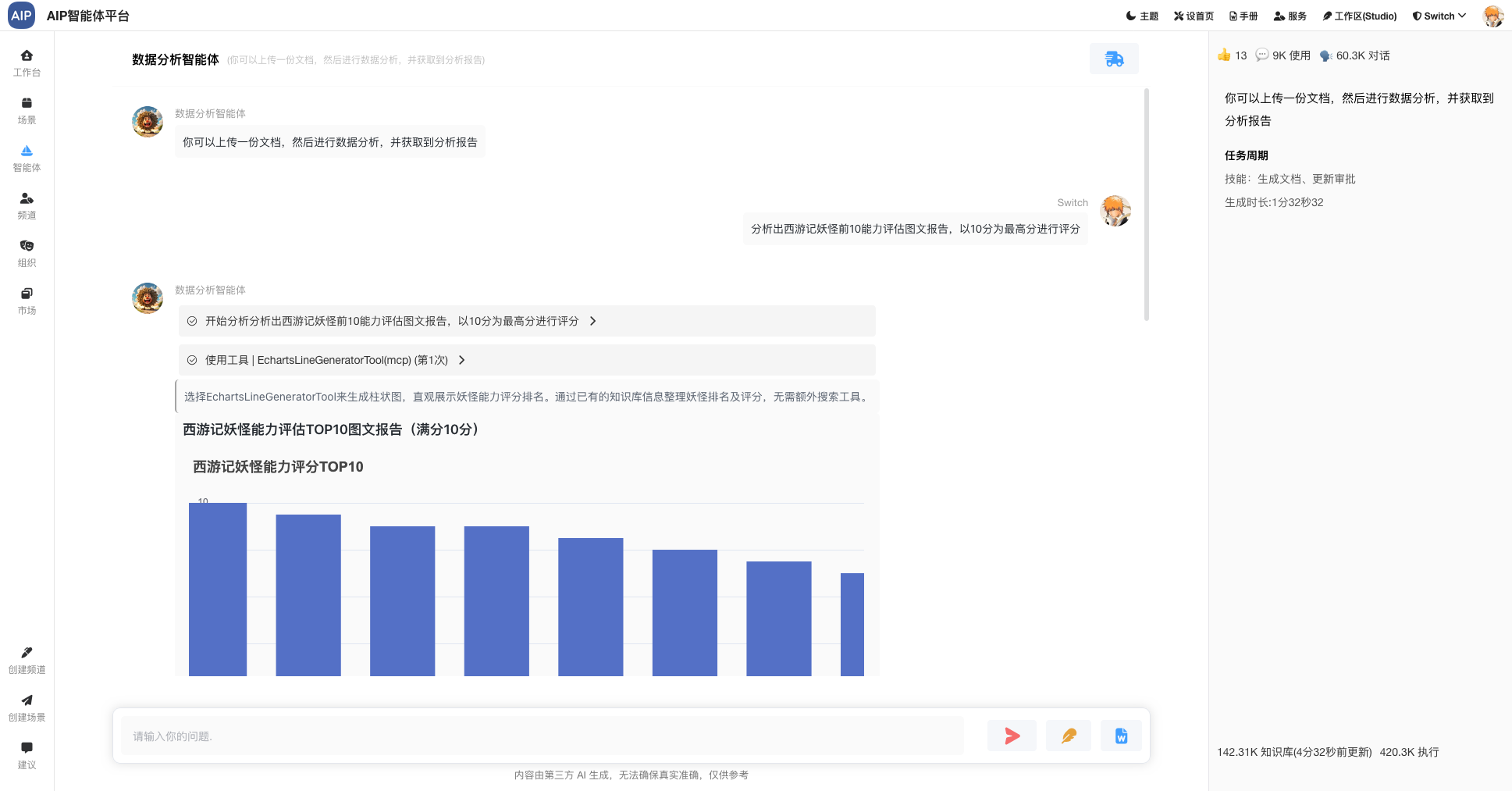
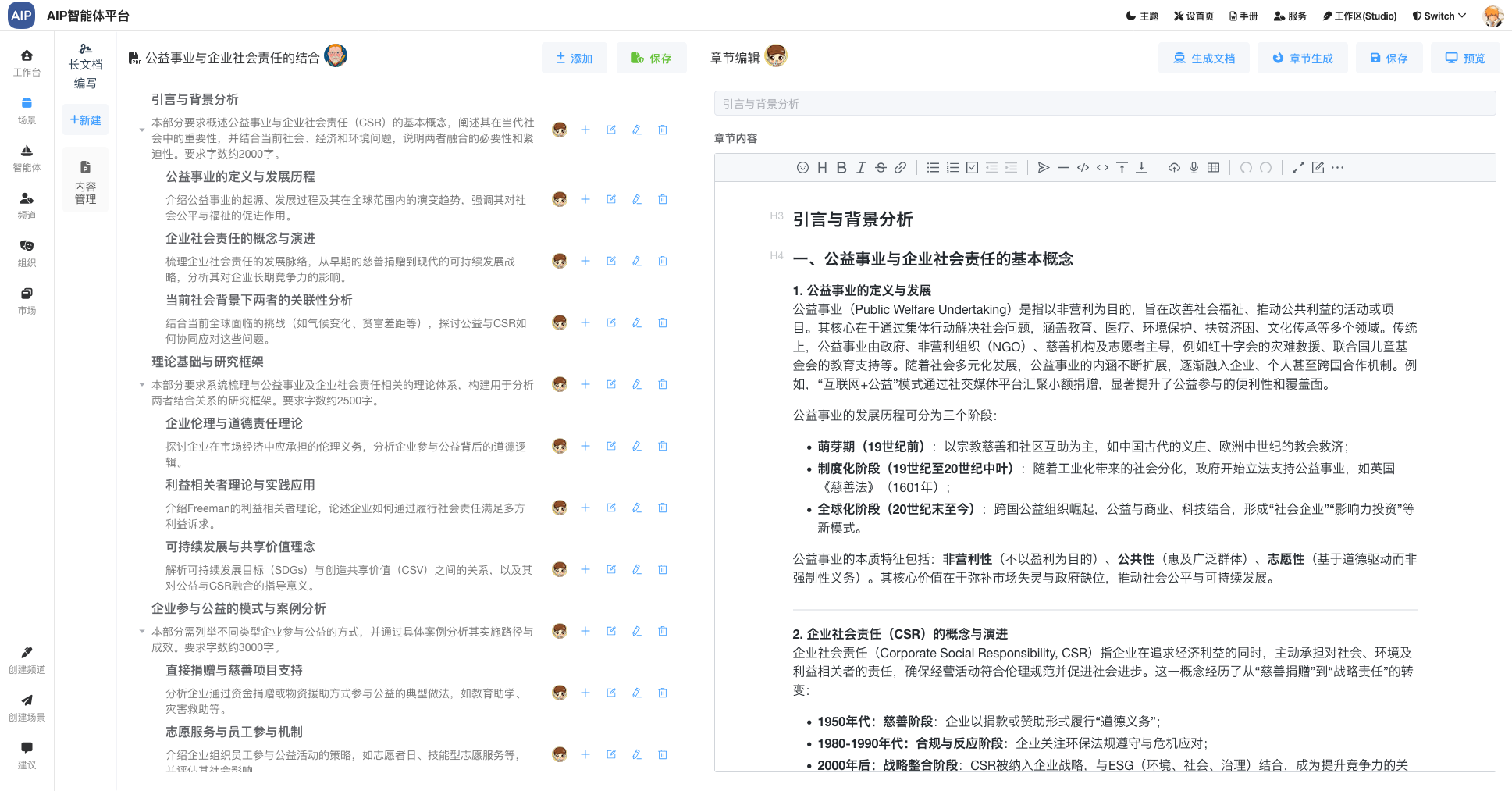
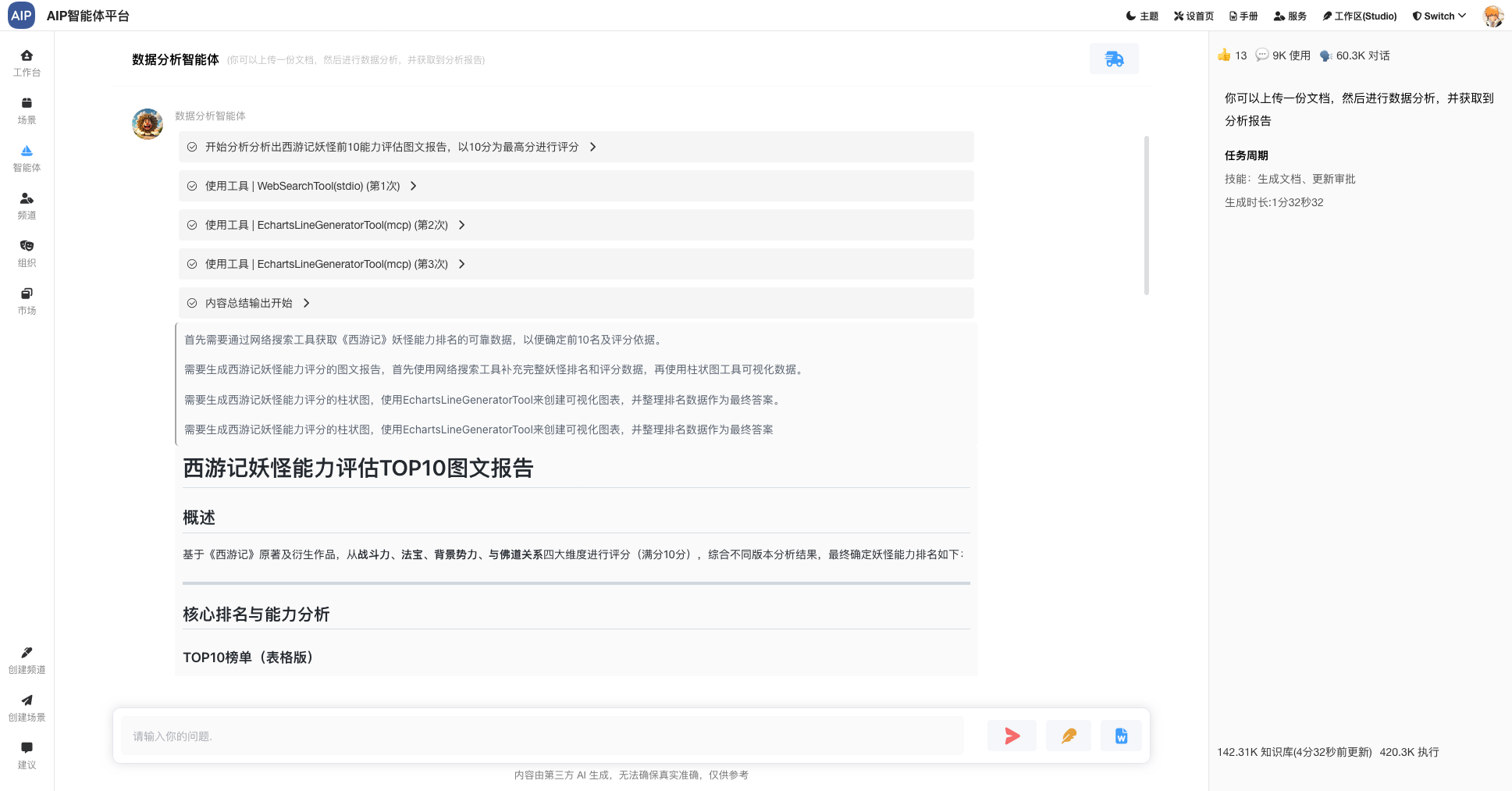
工业数据计算场景很多,一份报告的产出需要大量的过程计算还有明确参数化,专家需要精细的数据计算和验证,还有确保每个阶段是否正确,同时做好审核验证,计算过程和公式和所带参赛是否满足,是确保最终的报告数据是否可用的主要条件之一。
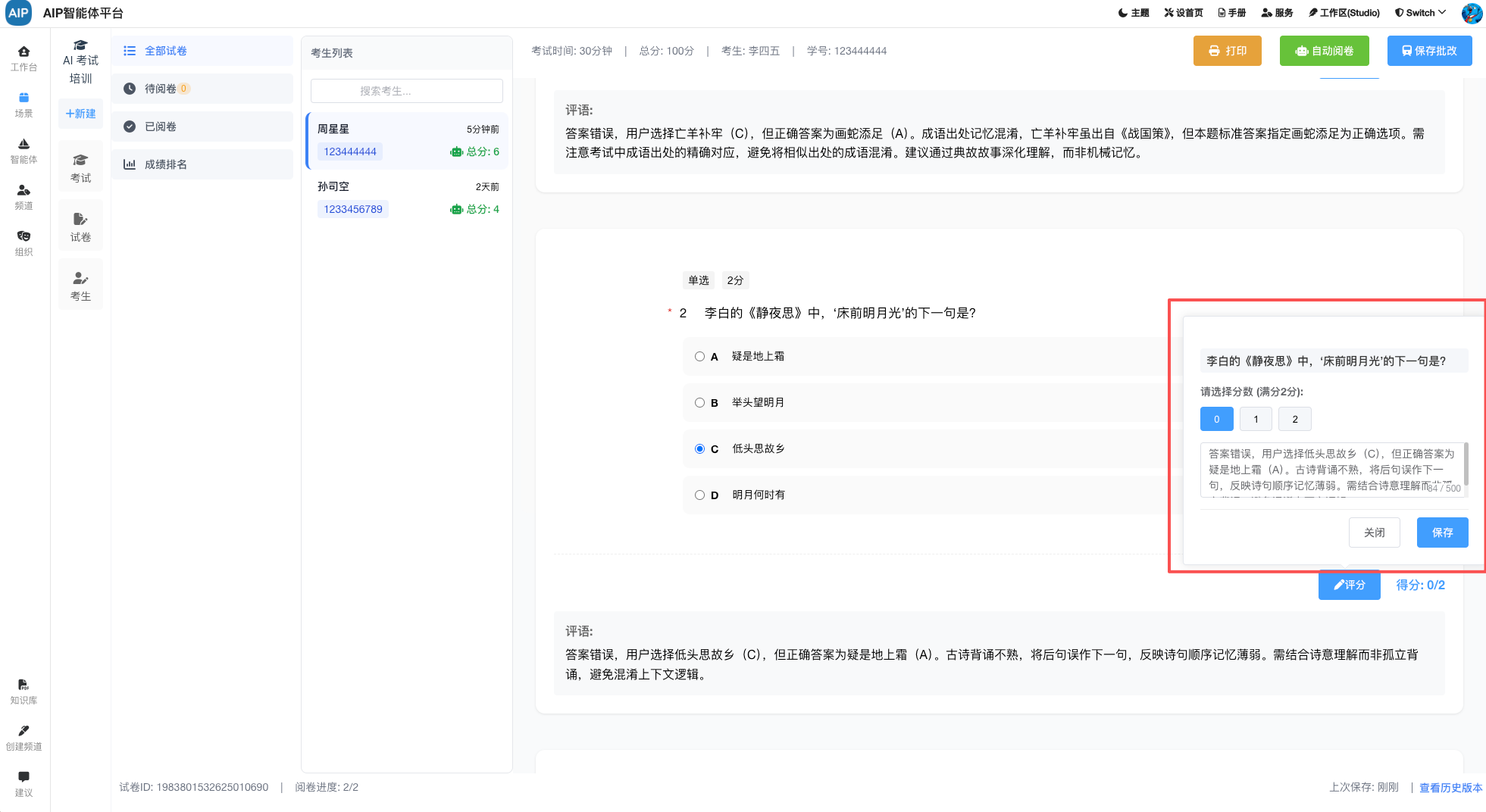
总的来说,需要看到完整的计算过程,AI过程不要是白盒,同时满足卡片现实,友好界面要求,还需要可以导出word版本。
这个主要是调整工作流和流程的显示优化处理,如下:
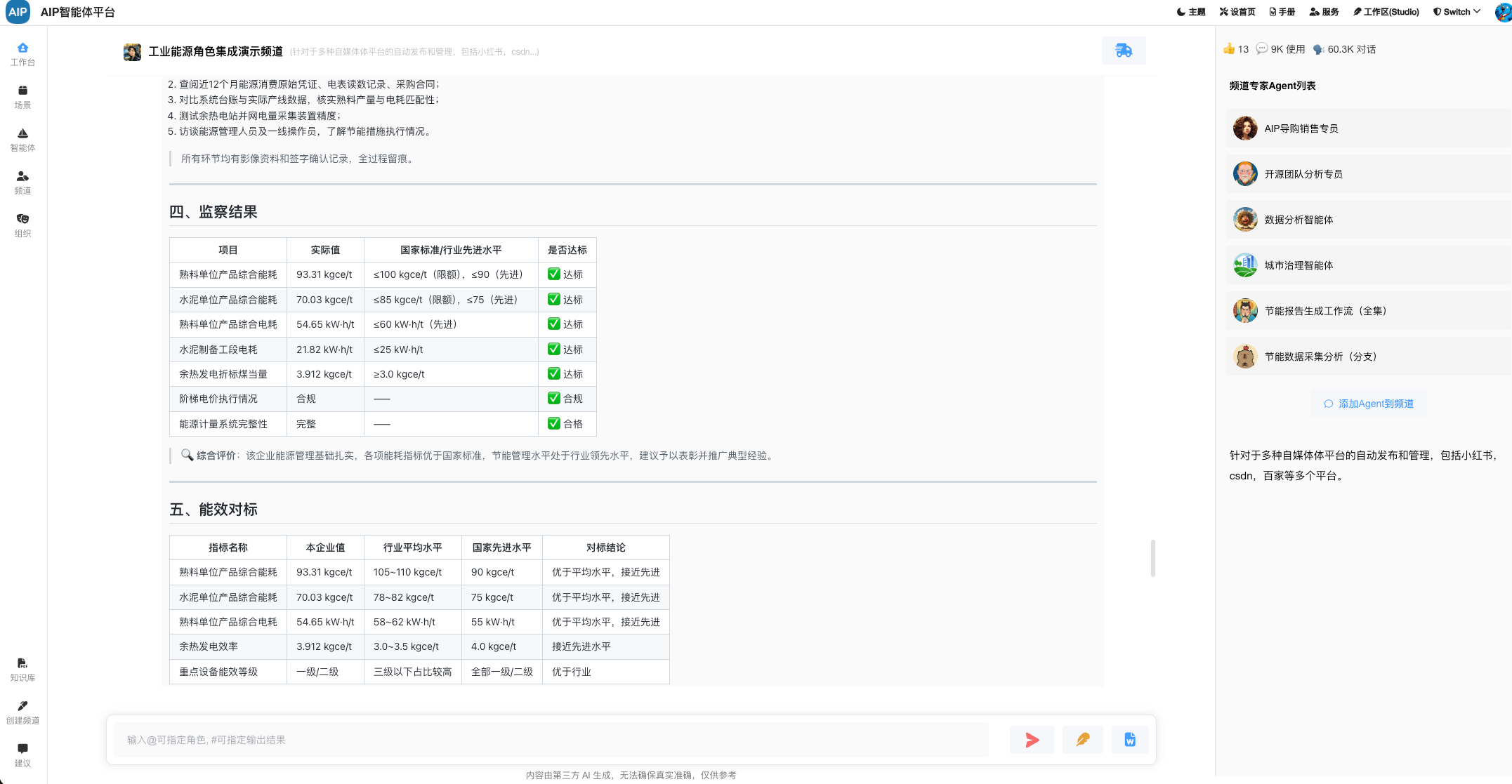
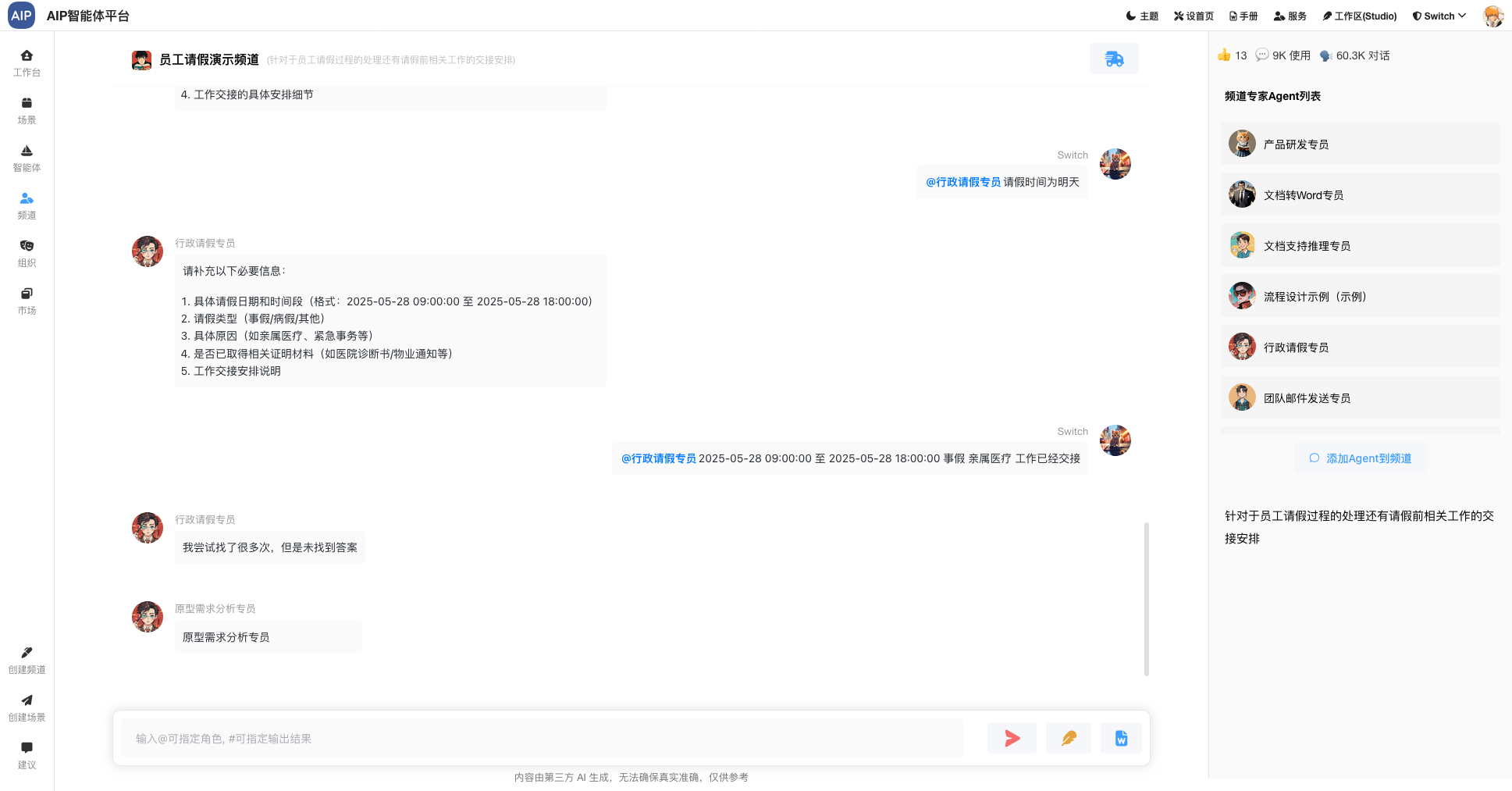
另外其它知识库和同步添加引用查看来源,标记内容反馈等。
出了本身大模型的能力和上下文技巧,这里结合高质量的数据,尽量可以最短的最有效的上下文获取到一个流程节点的去幻觉化,主要达到每个过程可查,可找,可看,有问题的地方清楚,明确,目前AI大模型已经有非常高的推理和理解能力,流程走下来,这个基本是可以达到的预期的目标。
总结
本阶段AIP在工业能源领域的AI落地探索,通过“湖仓一体化架构+AI任务编排平台”的轻量级技术方案,解决垂直场景相关问题。后续进一步深化AI与工业场景的适配性,例如拓展更多能源细分场景,优化智能体的交互效率,以更贴合专家工作流的方式,高效率地实现AI价值落地。
以上为AI智能体的一些落地建设参考,有兴趣同学可交流沟通。