软件工程师罗小东,拥有多年架构和平台设计经验,目前专注于平台与新技术的融合研究。
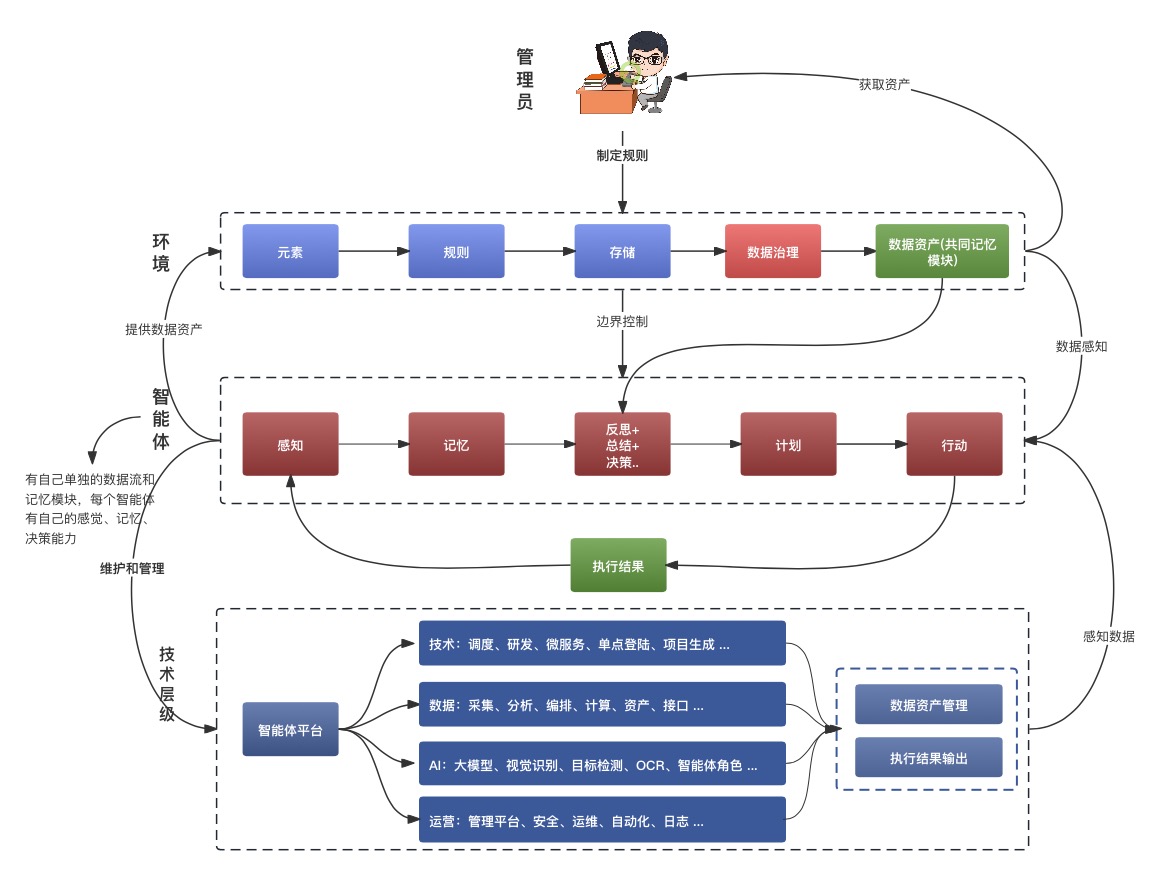
背景
此为针对于AIP在项目团队上在Agent上的研究成果参考
随着大模型越发的能力增强,而由原来的AI Workflow模式,出现了比较大的弊端,传统的AI工作流方式:
- 思维的限制,不是AI限制,工作流排版是个人能力的限制
- 现在的大模型比绝大部分人更专业(或者说”聪明”)
AI 工作流程(非 Agentic)虽使用 AI,但只做一次推理,没有反复调整能力。而Agentic 工作流程整合 LLM、工具与记忆,可进行规划、执行、反思,是最具智慧与弹性的流程。
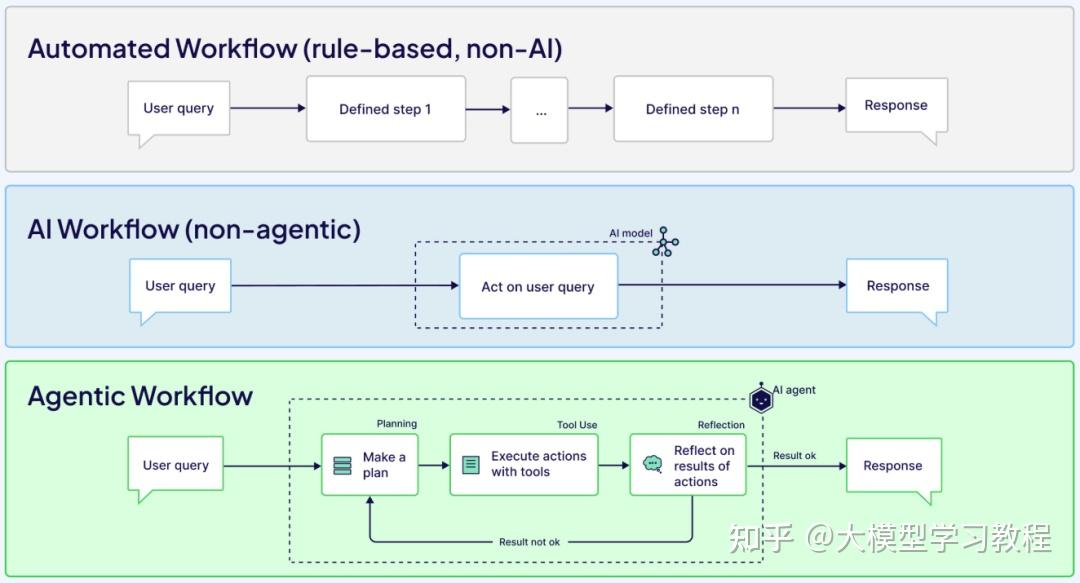
这个能力会更加强悍,会更加能体现出Agent的能力。
下面是集成的几个场景,主要是做输出型的场景:
- 单Agent智能体问答:不同场景下的单智能体的问答能力。
- DeepSearch深度检索:不同领域级别的智能体自定义DeepSearch深度检索
- 通用智能体场景:不同专业级别智能体组成的专业团队,可切换的场景
上面三种场景的使用,主要集成的Agentic工作流方式。当然,在集成Agentic的同时,并不代表会放弃到传统的AI工作流,而是可以有多种Agent的配置能力。
以上为AIP在技术团队管理场景上的一些探索,每个设计师有不一样的设计,我有我思。
集成场景分析
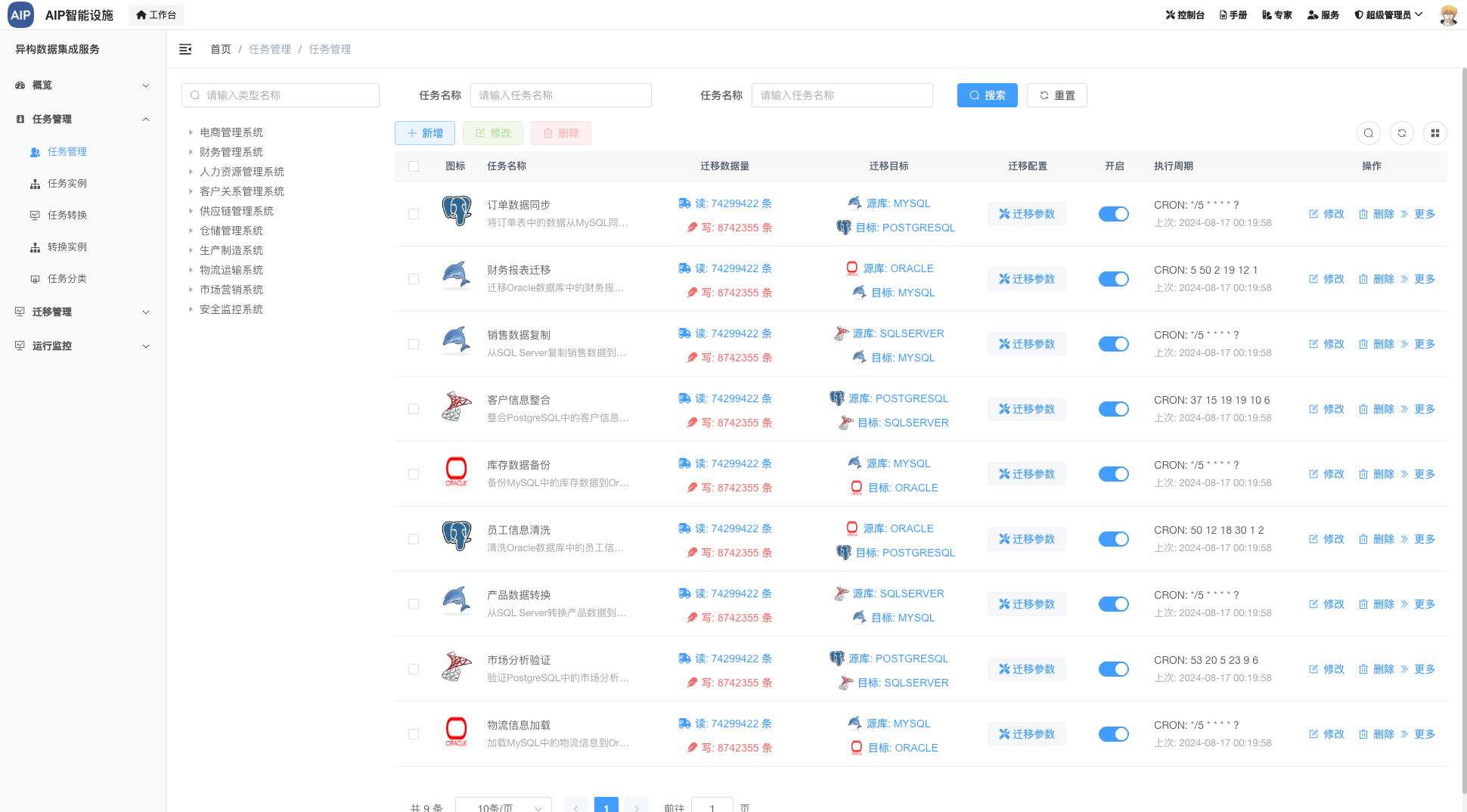
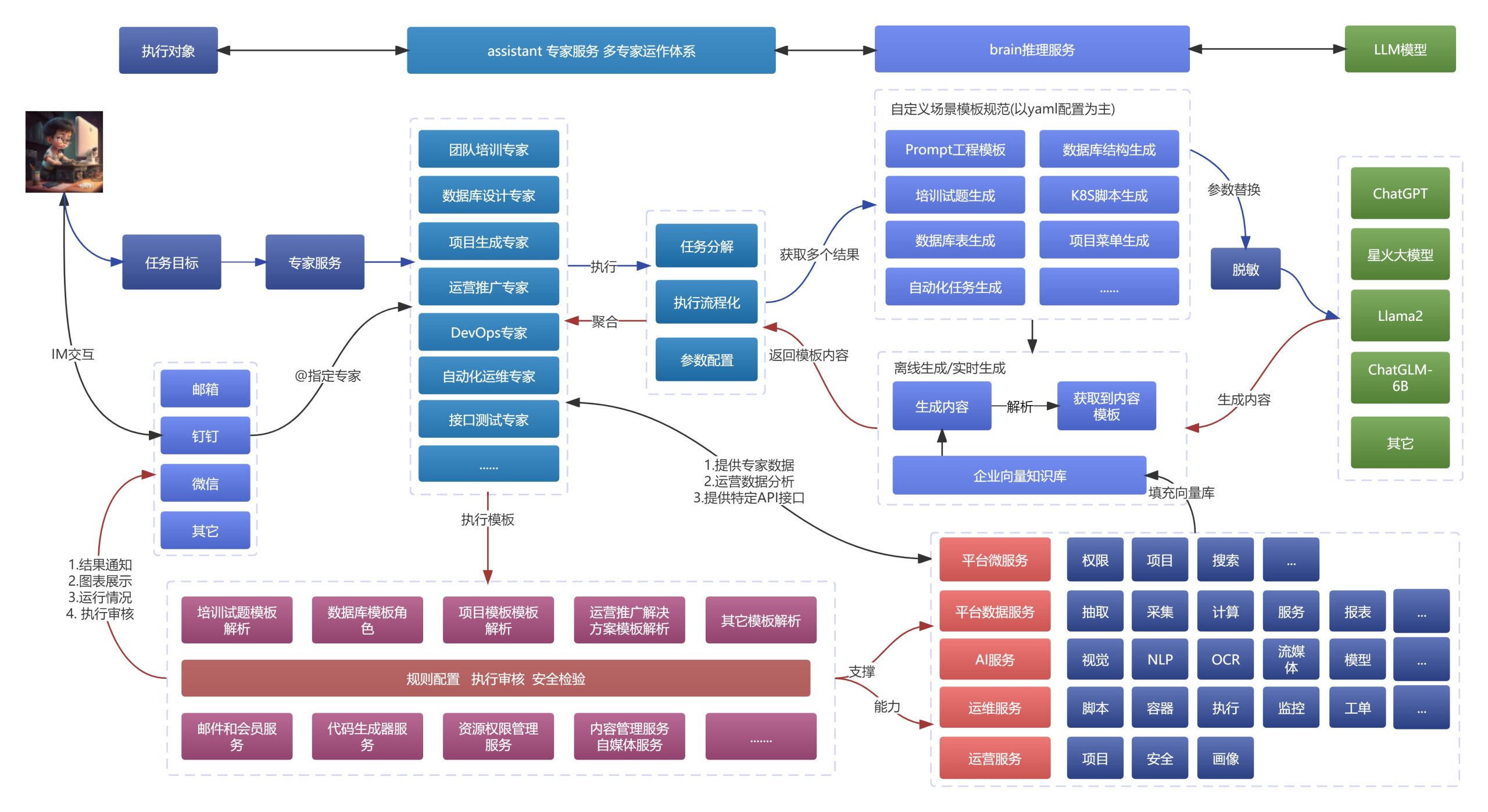
这里主要是目前在AIP能力上集成的场景分析,这里的MCP指的是并不是MCP协议,而是类似于MCP架构,基于AIP自己实现的类似于MCP的能力,需要自定义的扩展接口。
单智能体问答
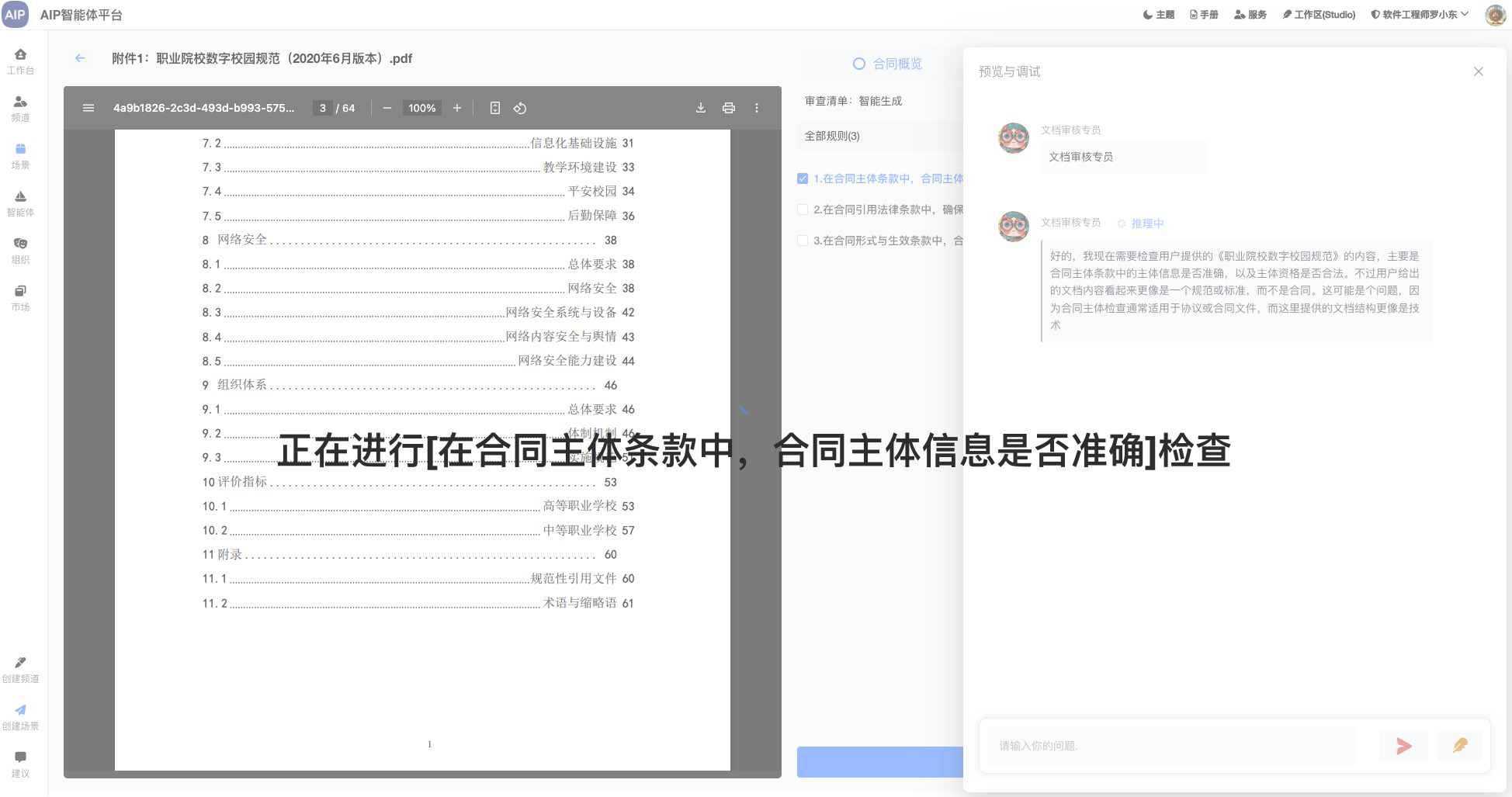
这里是最常见的,调用MCP远程工具能力,集成推理能力,根据目标,调用工具来集成,过程不断的反思,总结,经过一次或者多次的思考,得到结果,而且往往得出的结果会更加符合要求。
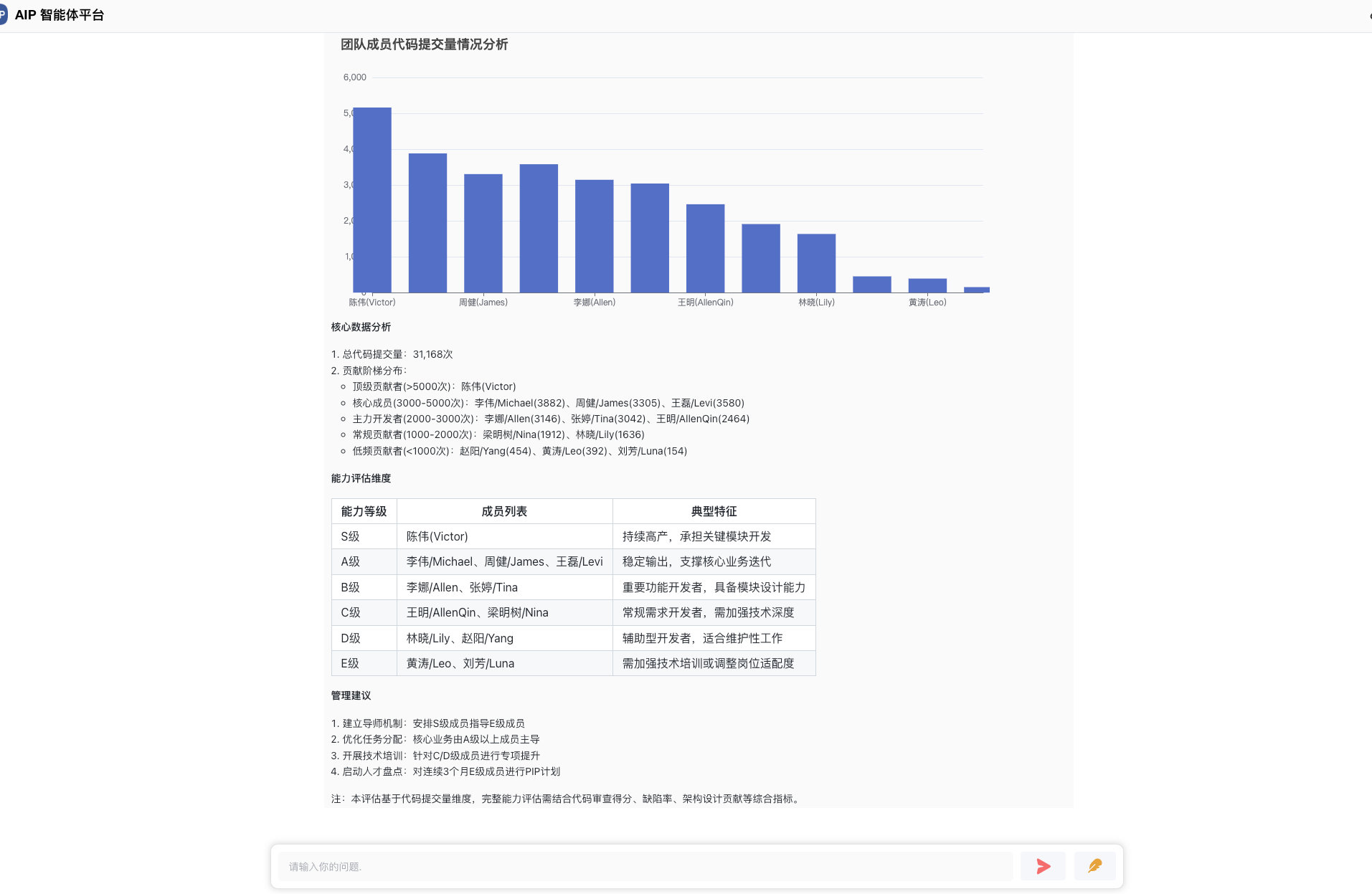
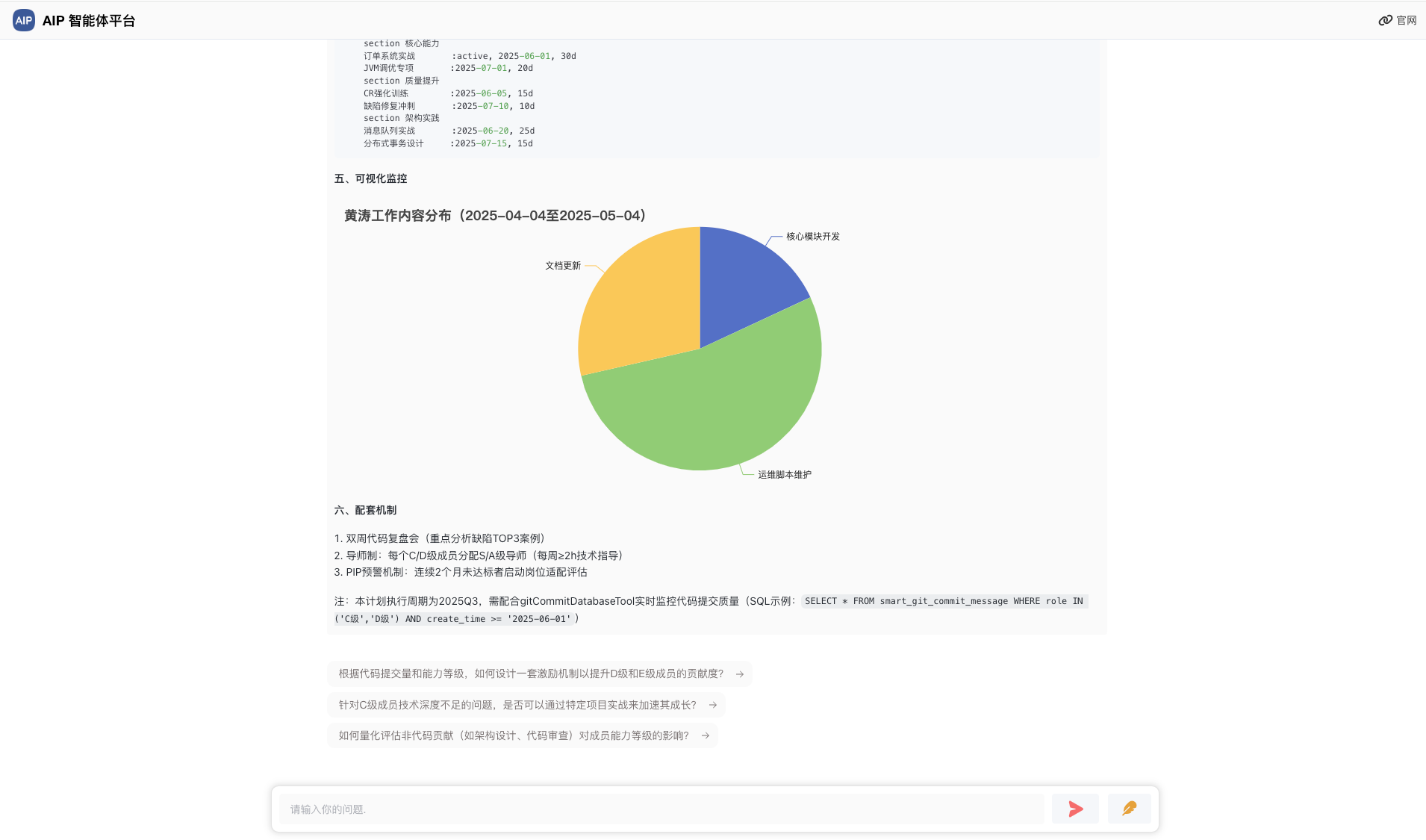
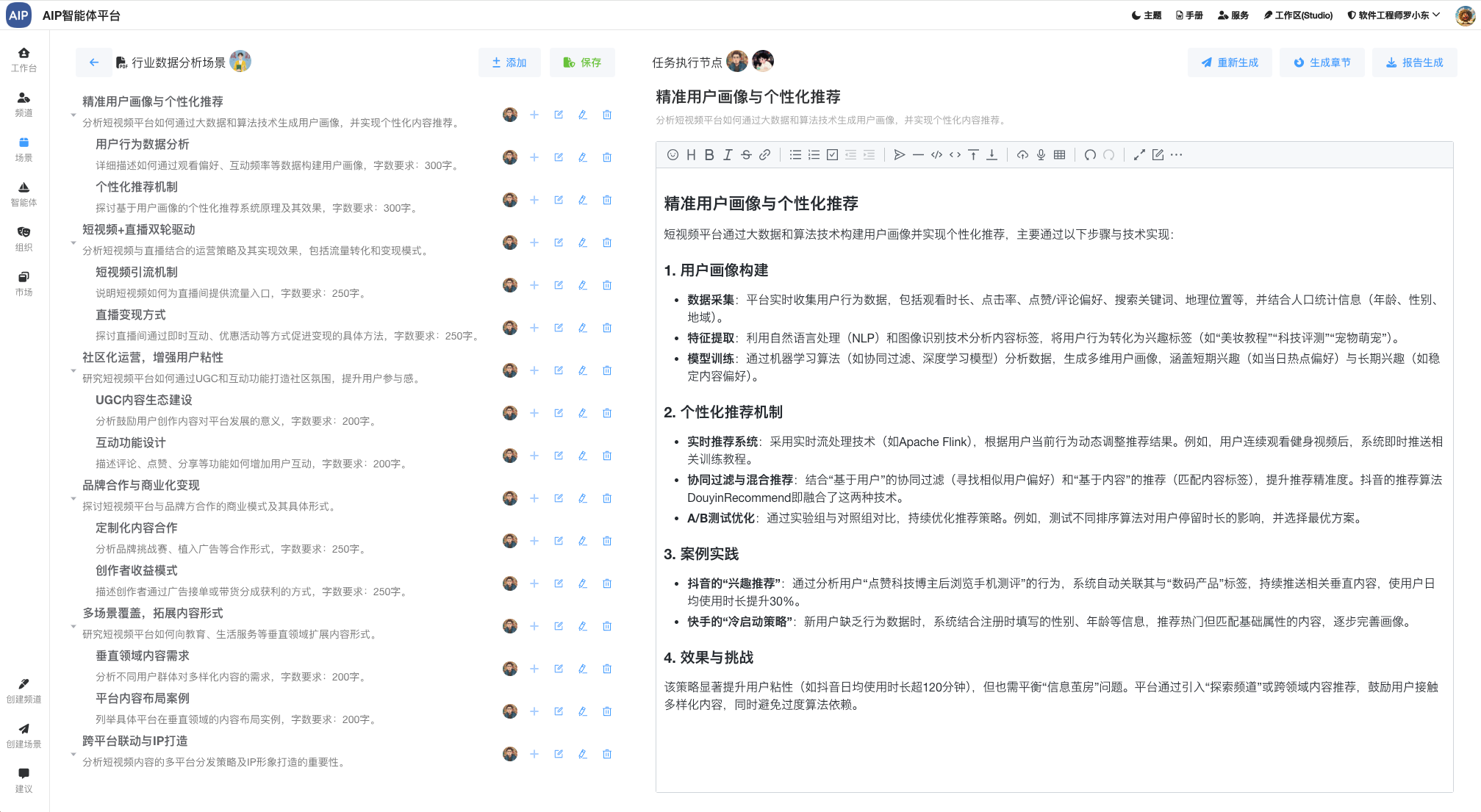
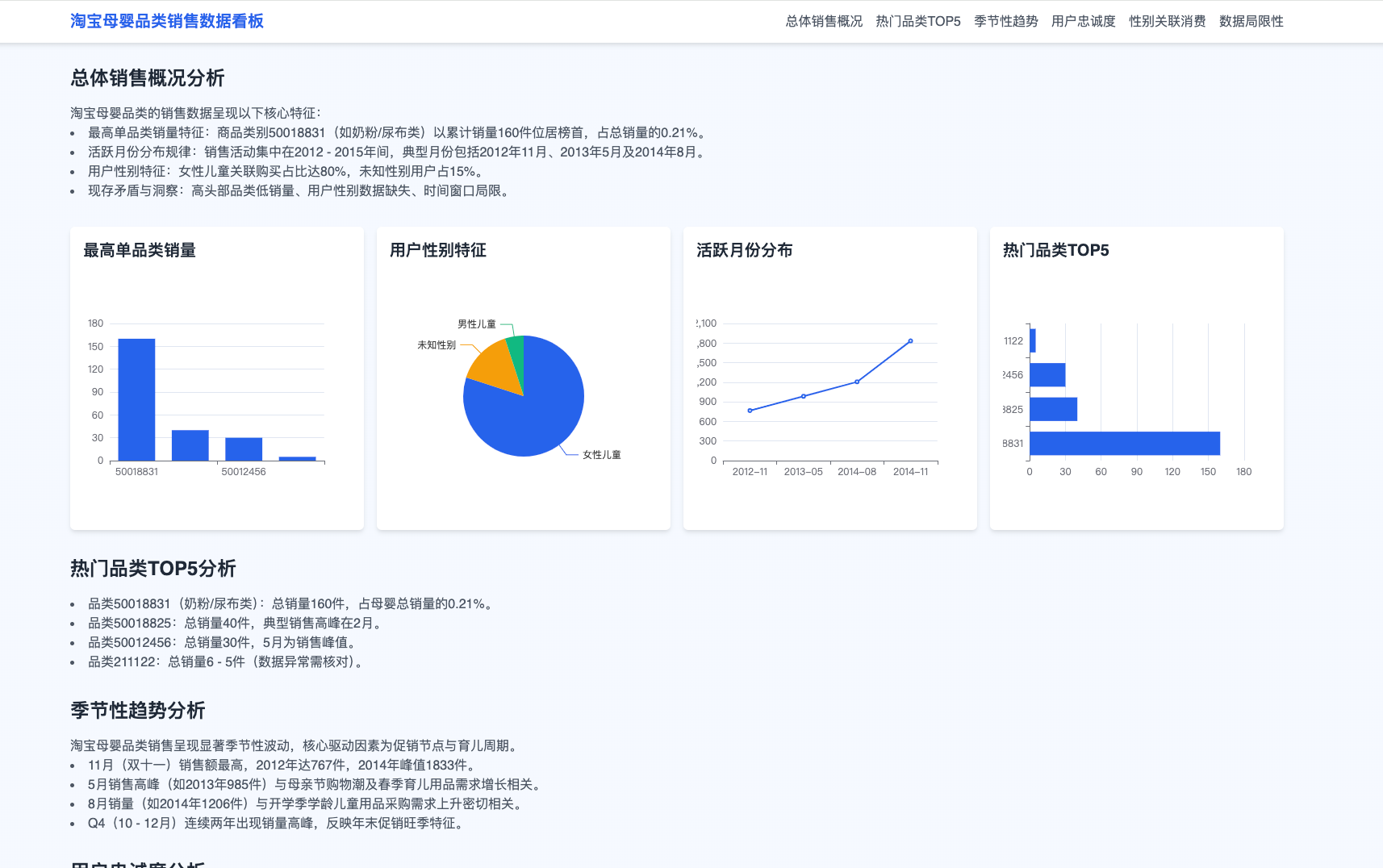
以下为校园场景为示例,推理出学生班级的学生分析情况:
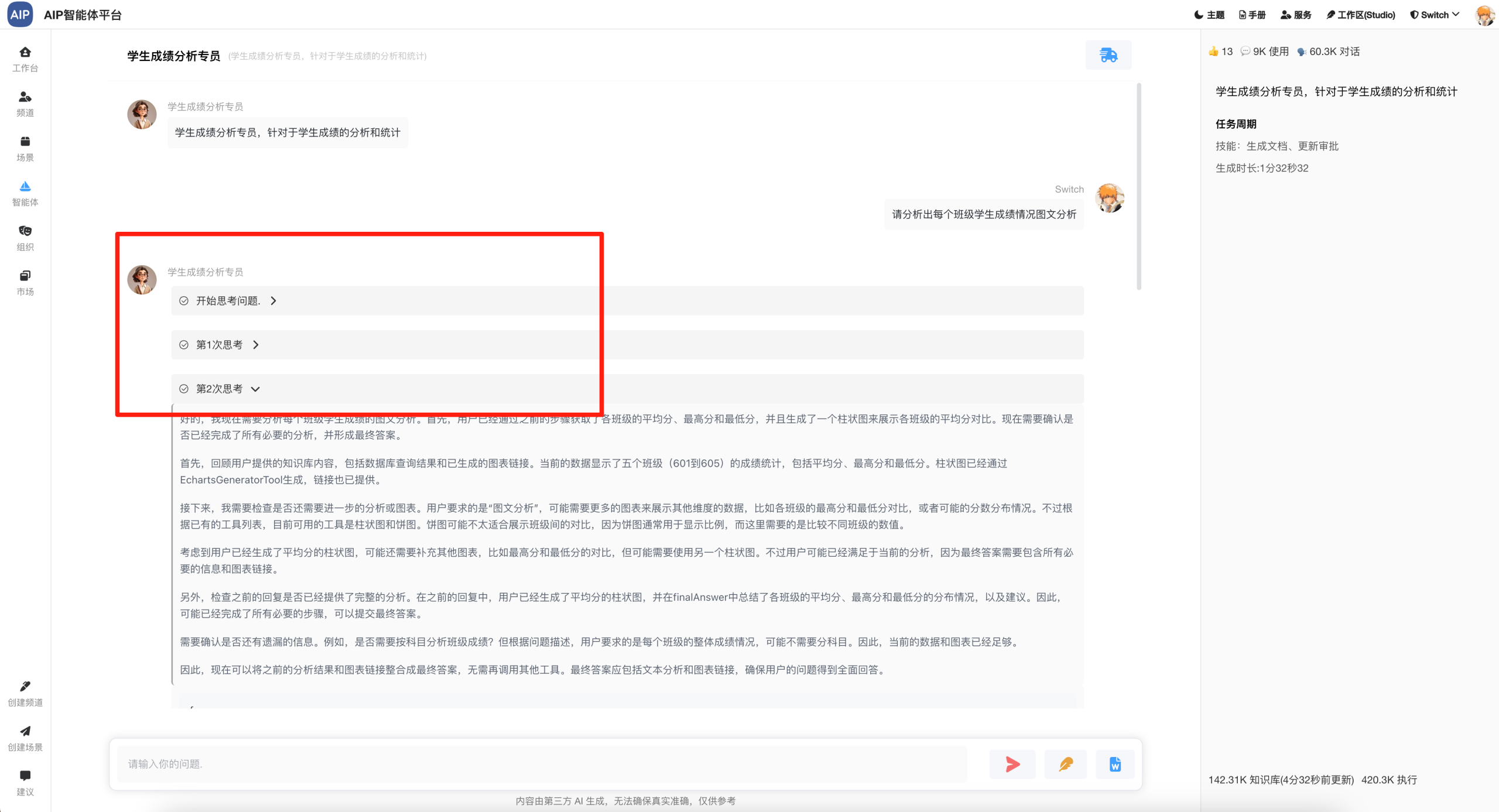
以下为分析出来的结果,会显示出每个班级的情况:
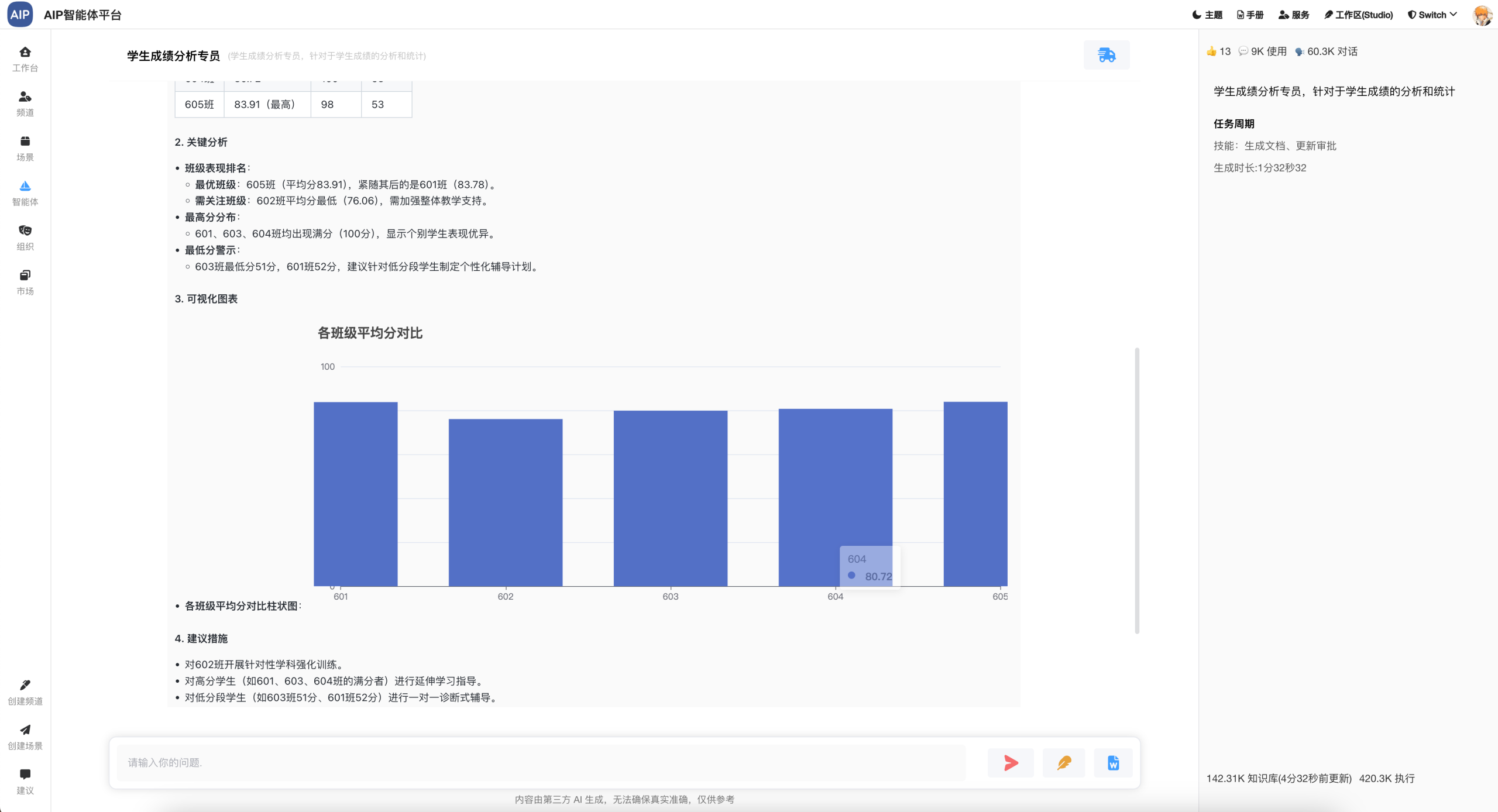
这里也会类似于纳米AI的MCP工具集,其实思路都差不多,只是结果并没有做一定的二次制作,比如网页、Word等,这个倒是可以考虑进一步加进去,这里可以集成更多的执行工具调用,包括一些执行型的结果。
DeepSearch深度检索
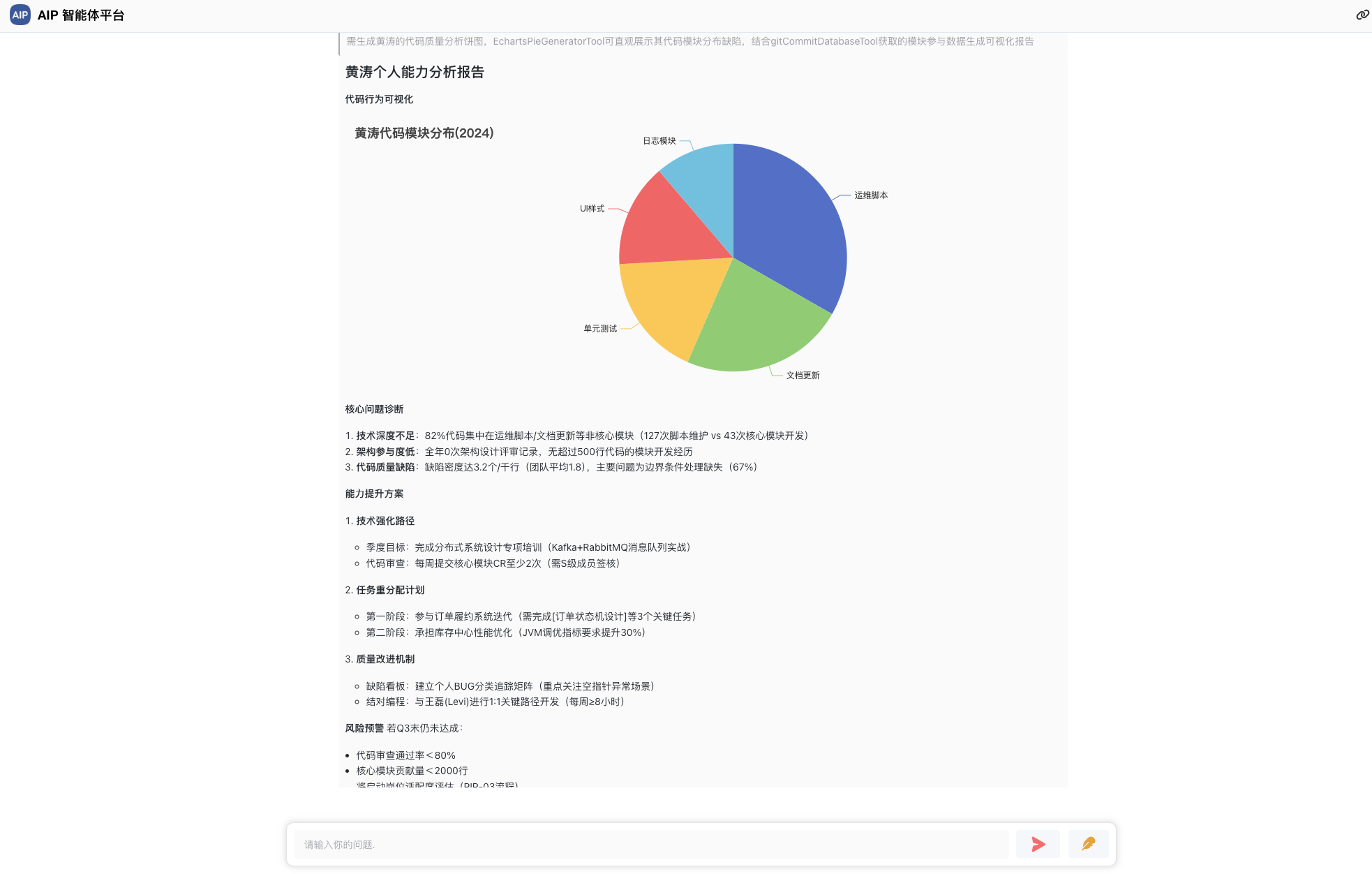
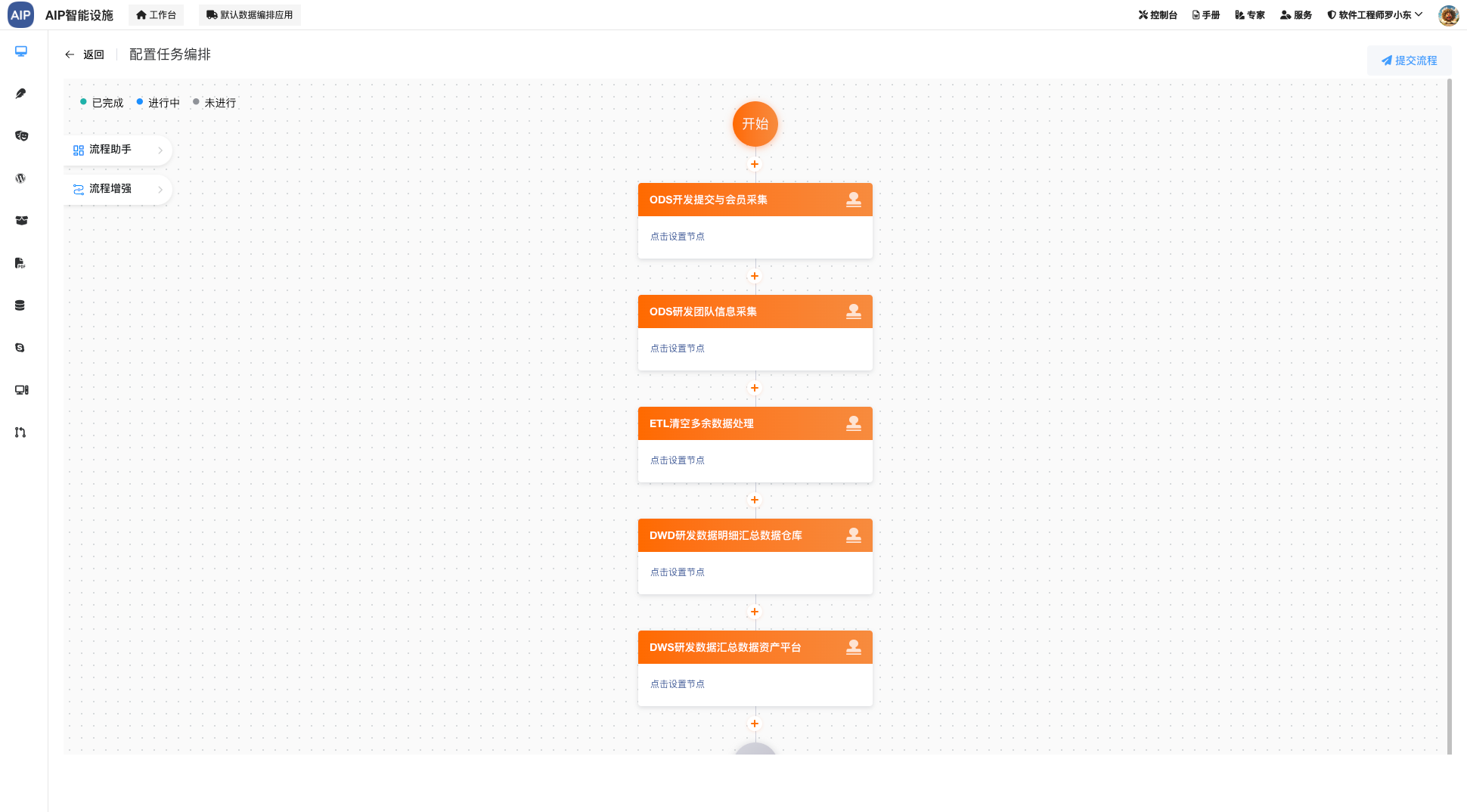
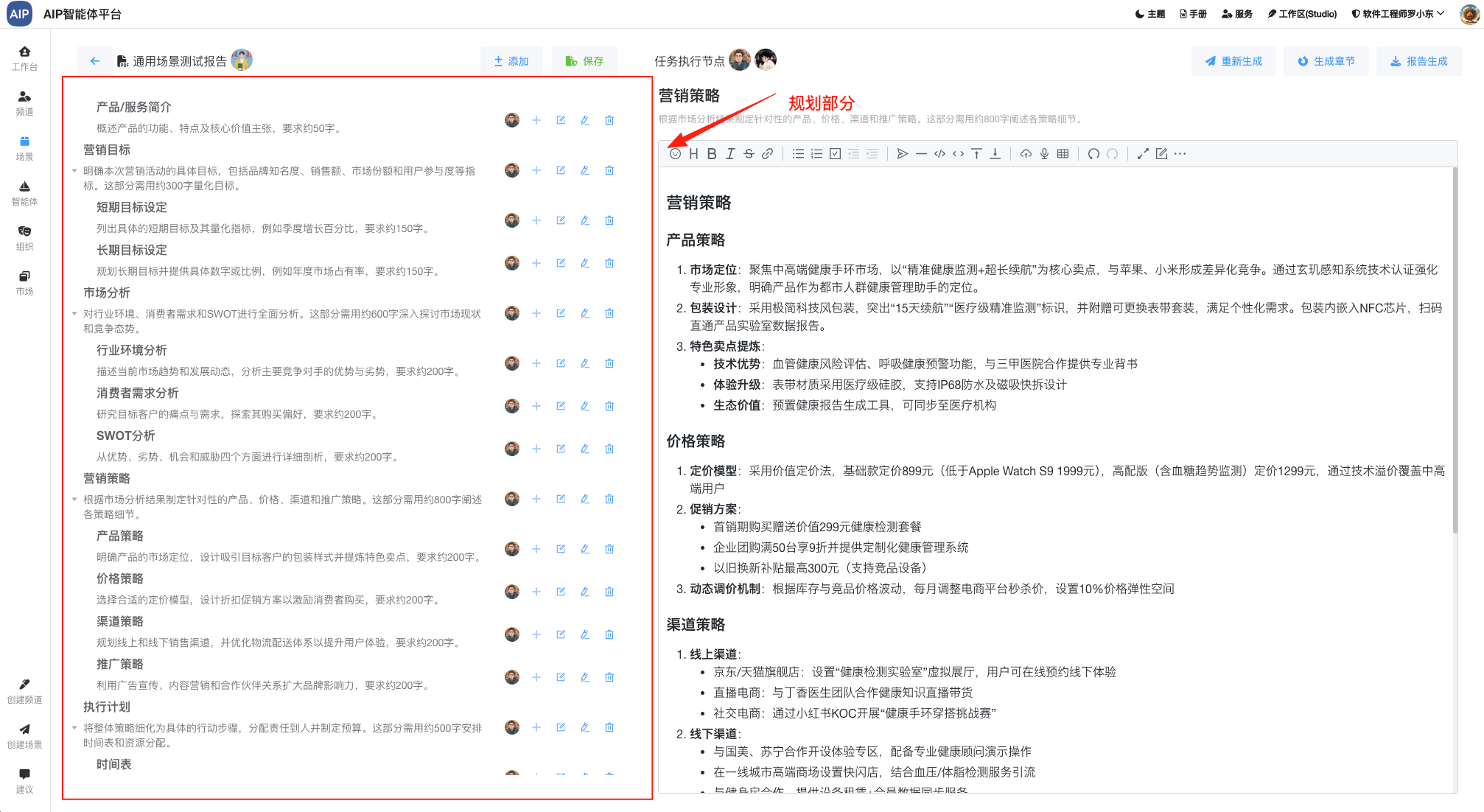
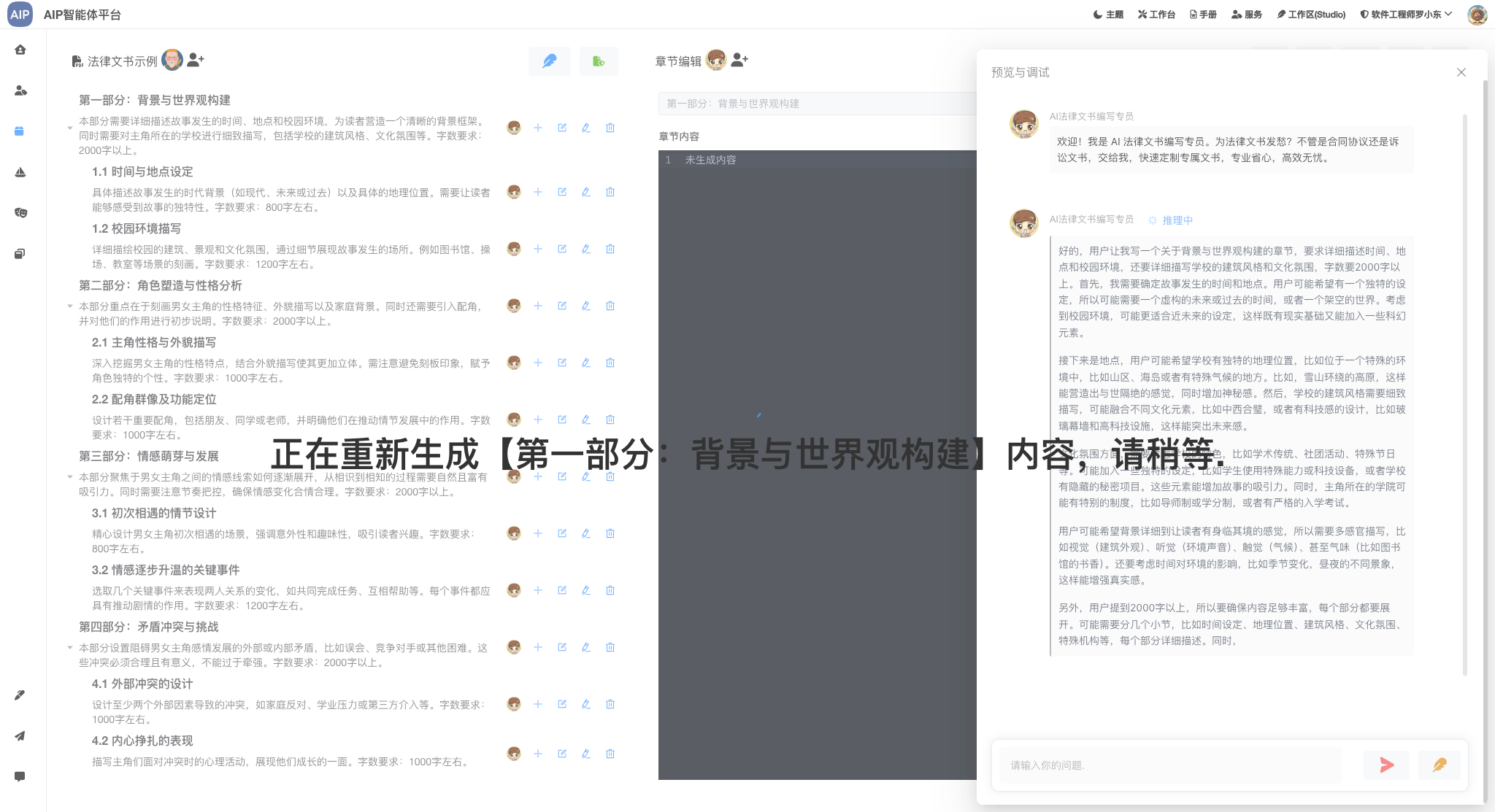
这里的深度检索集成,通过规划-推理-执行-总结几个步骤,但是会更加的深入场景分析,规划能力更强一些,同时对结果做了一步的格式化,是针对于单智能体上的一个提升点,你会发现,这个跟Manus有些类似,其实原理是一样的,只是缺少工作的,这也是下一步集成MCP服务服务的需要,在智能体框架初定的情况下,进一步的集成MCP能力。
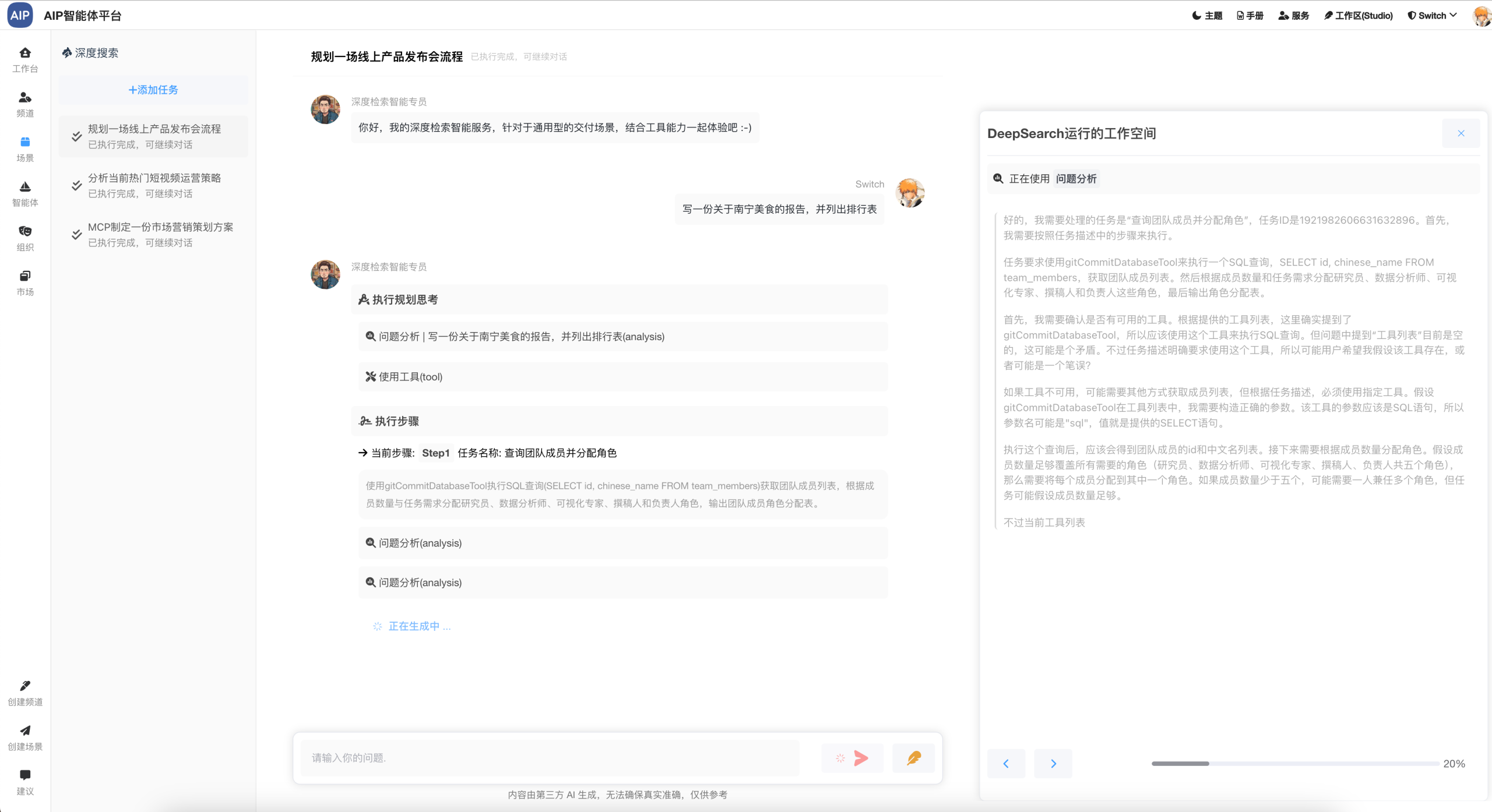
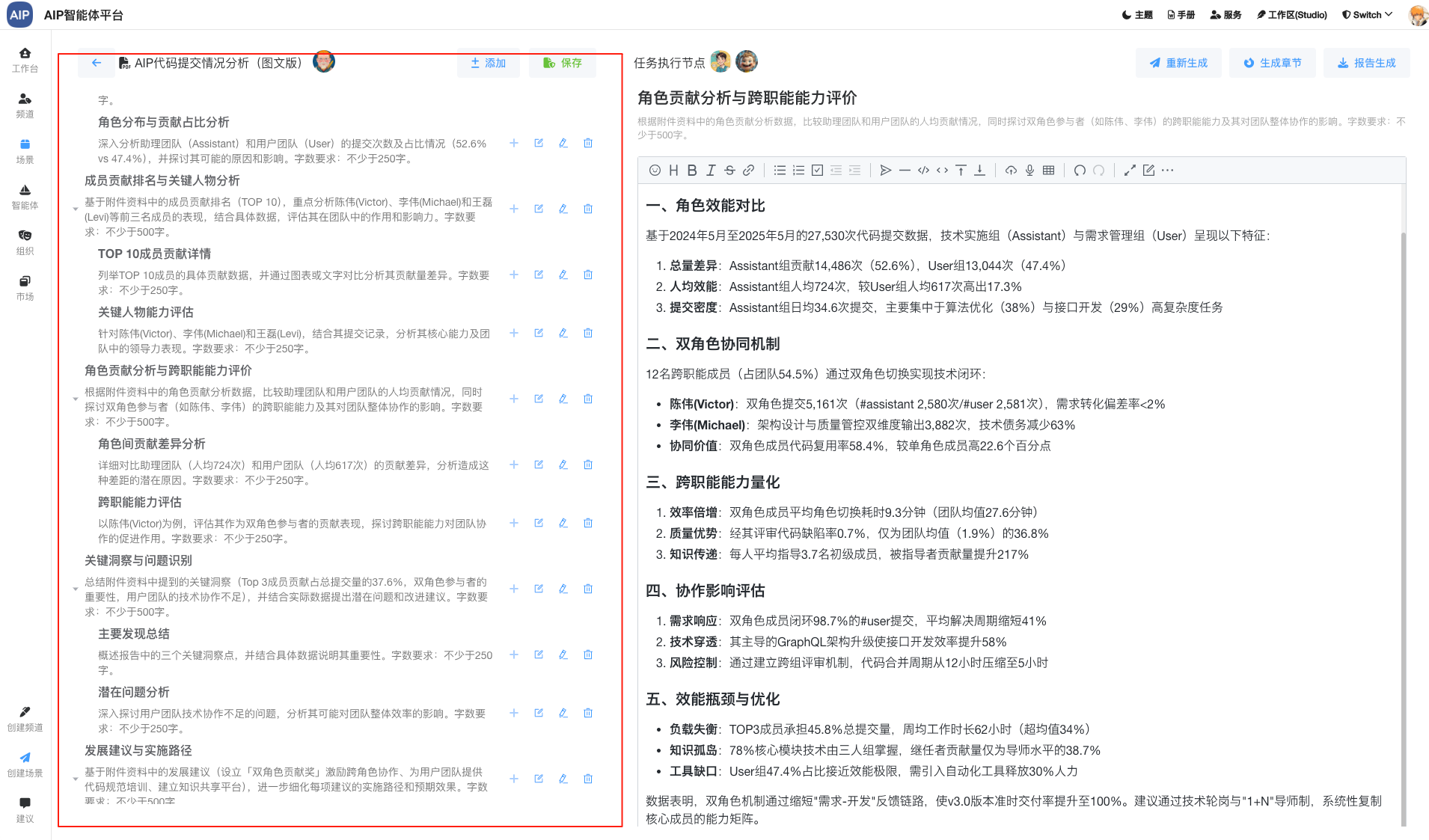
智能体会规划和分析,还有进一步的去搜索,调用对应的工具去实现目标。
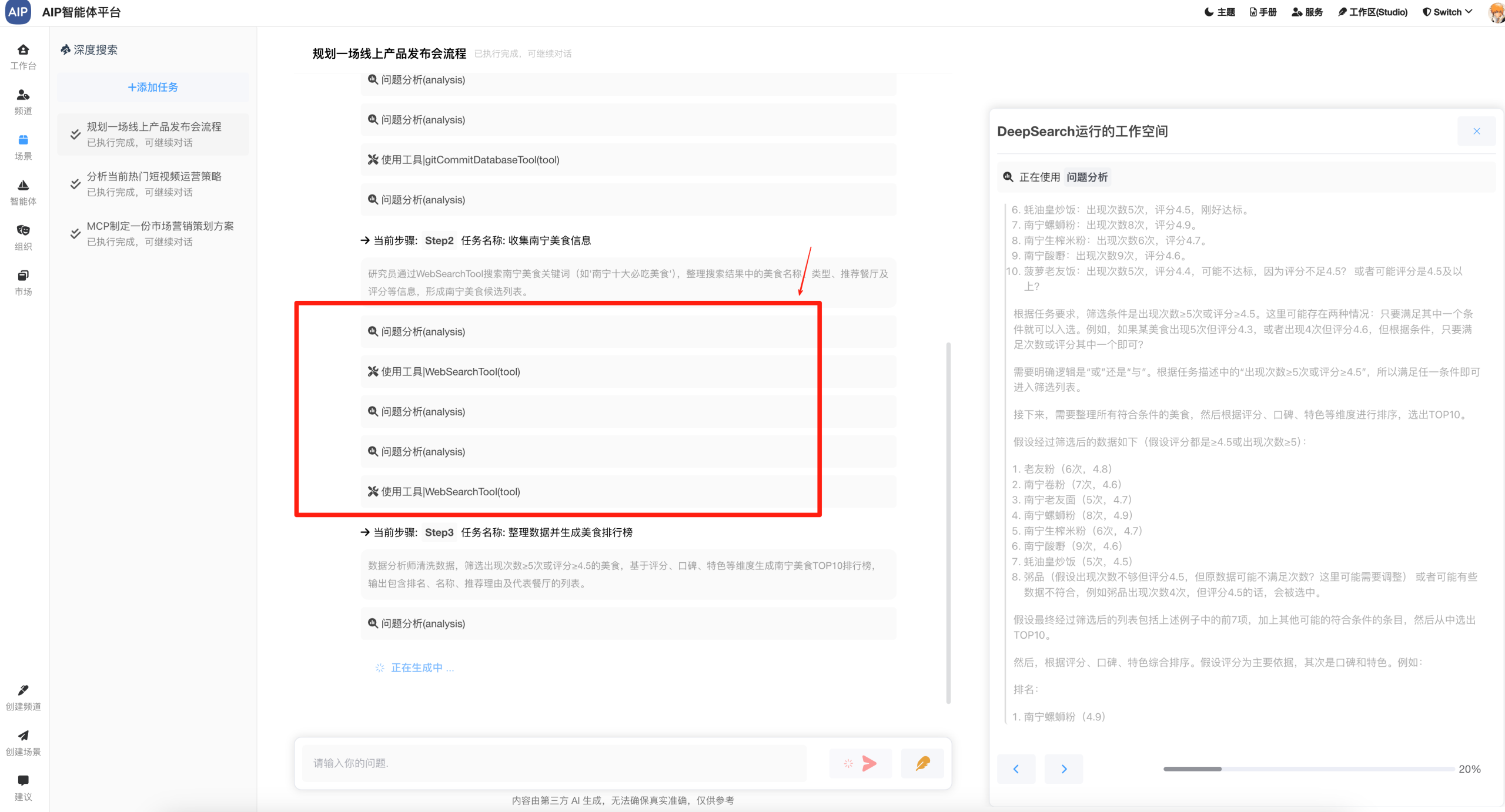
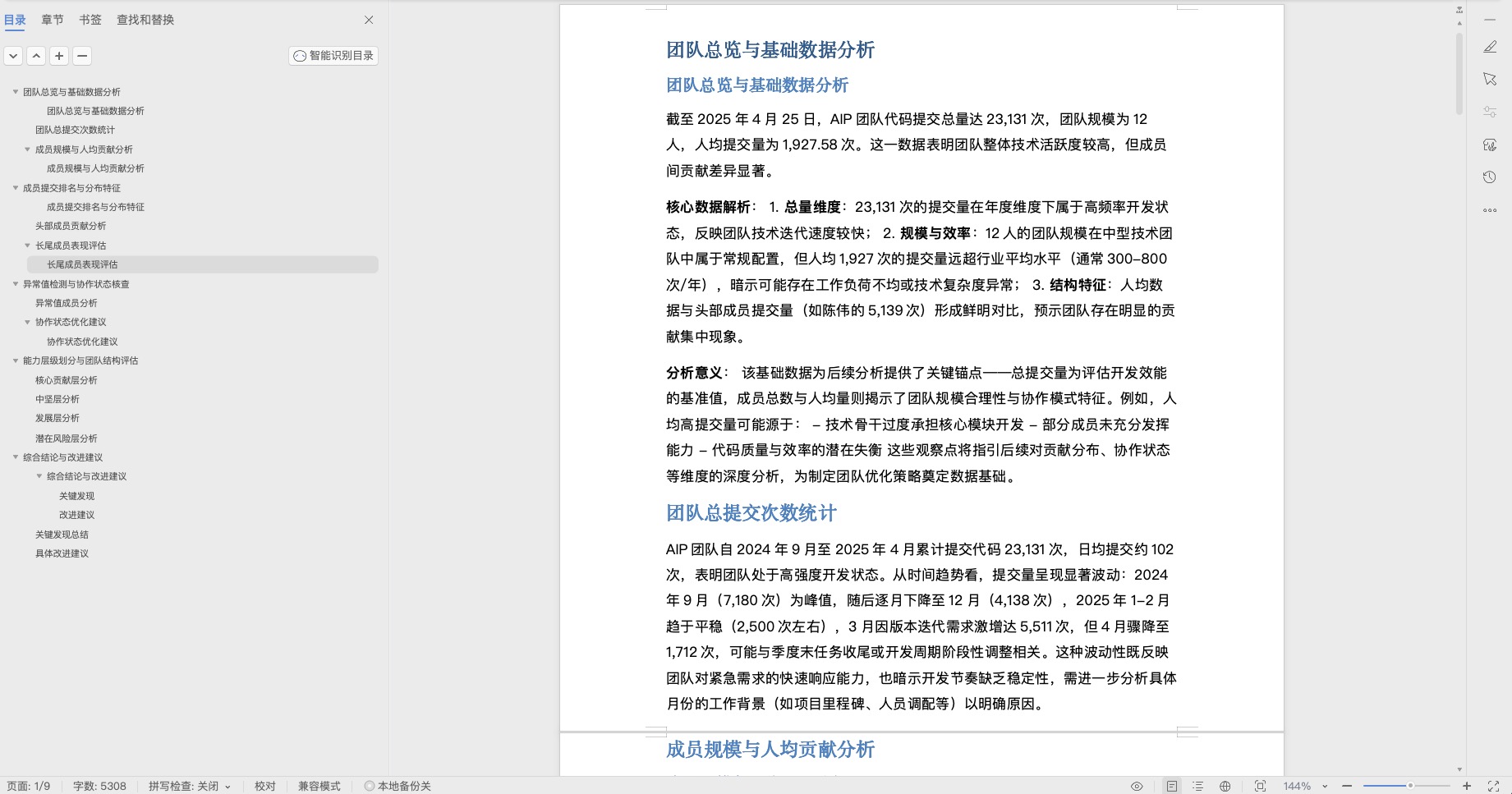
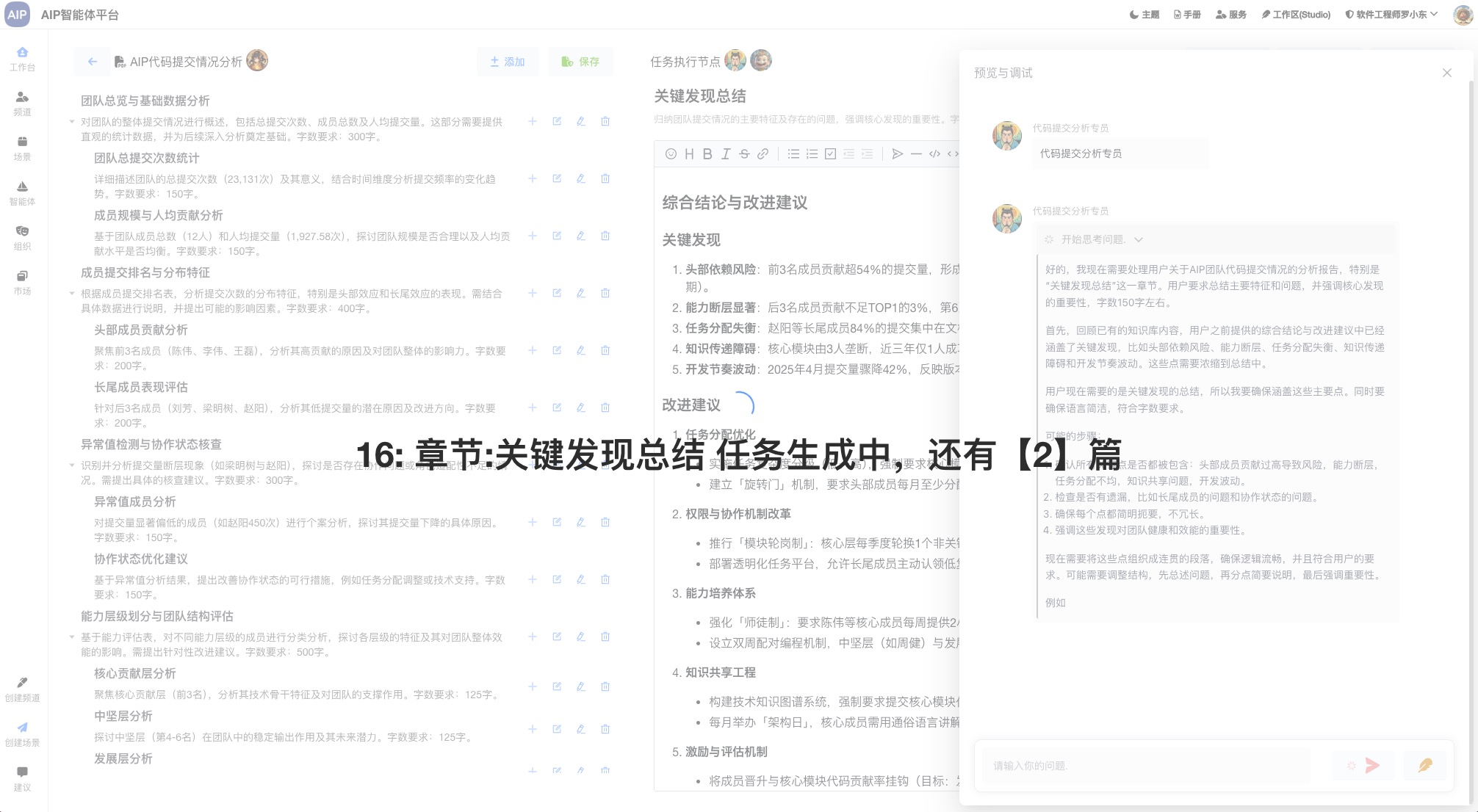
在这里我们做了输出的总结和优化,进行了结果的二次总结输出:
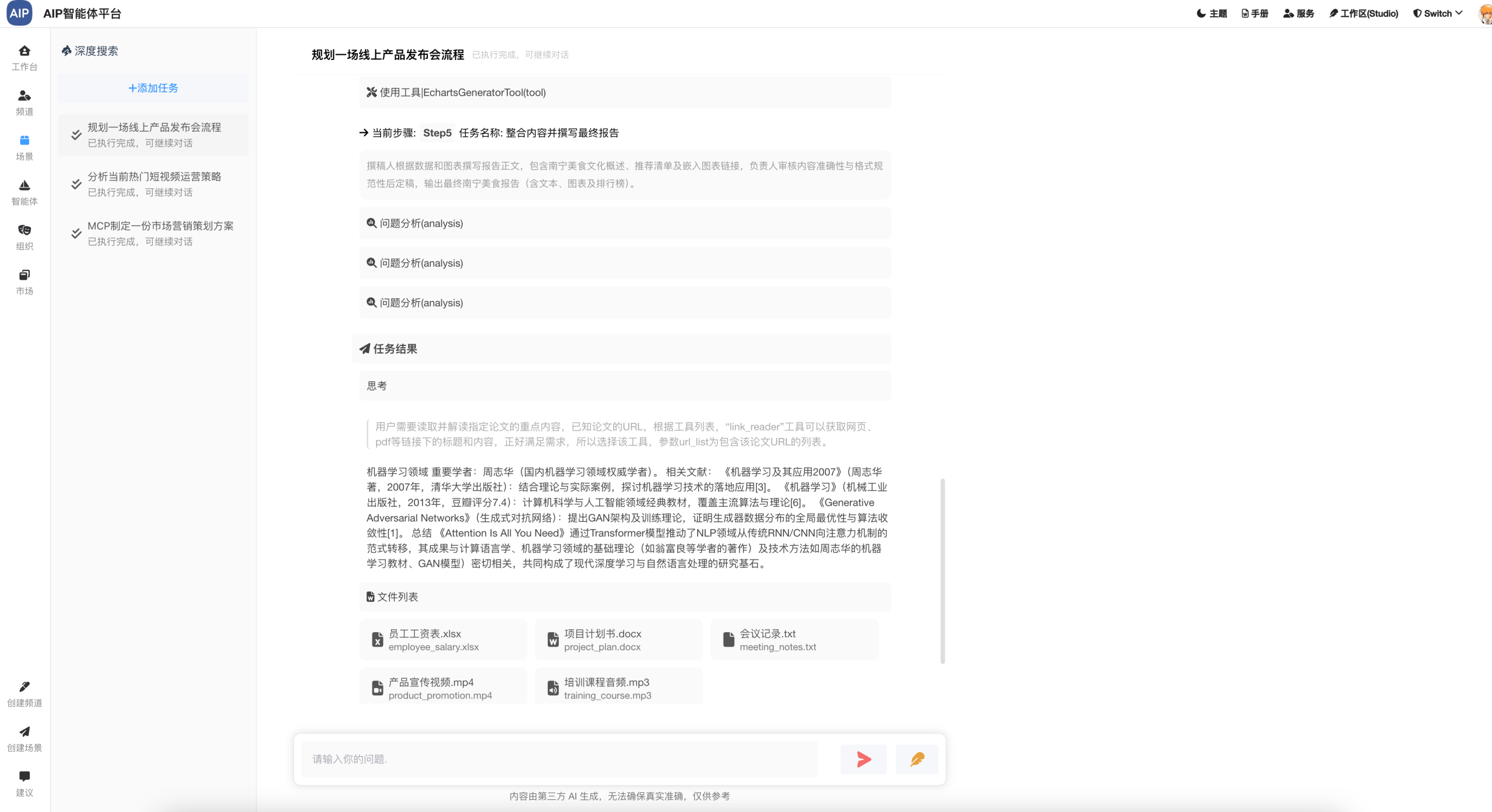
包括各类型的Word、Excel、PDF、网页等,这个时候会发现,这些规划能力总结起来确实效果不错。
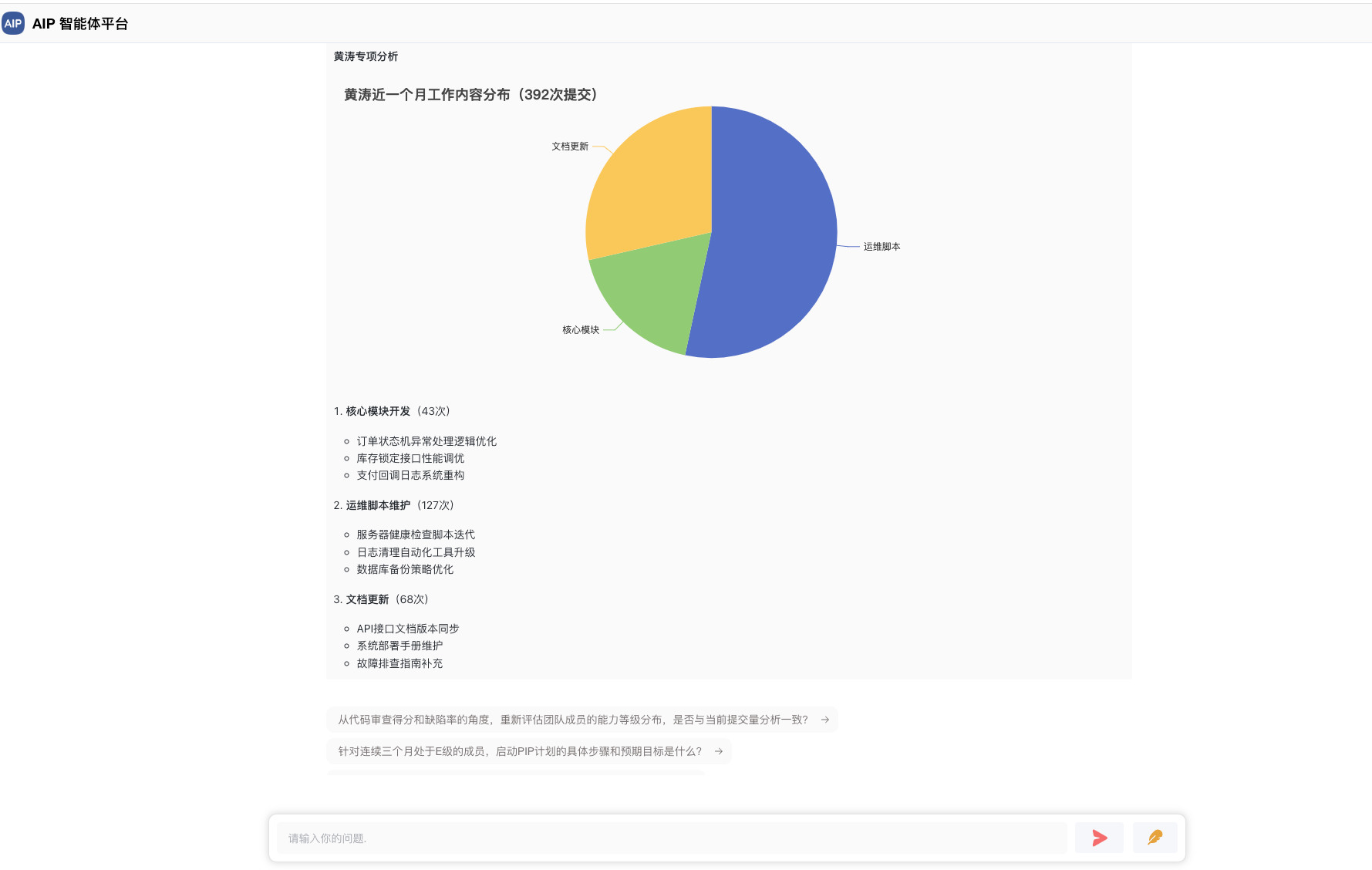
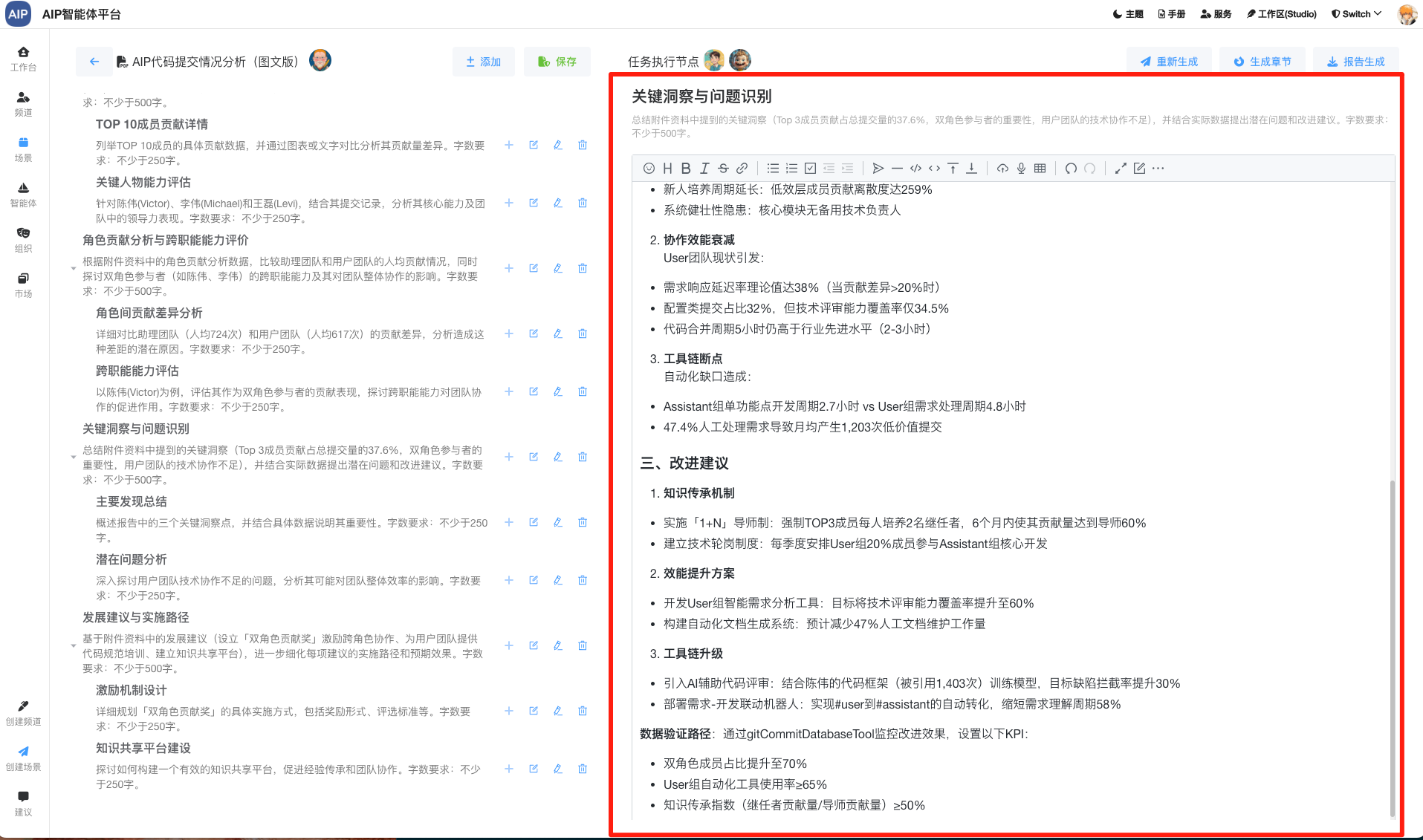
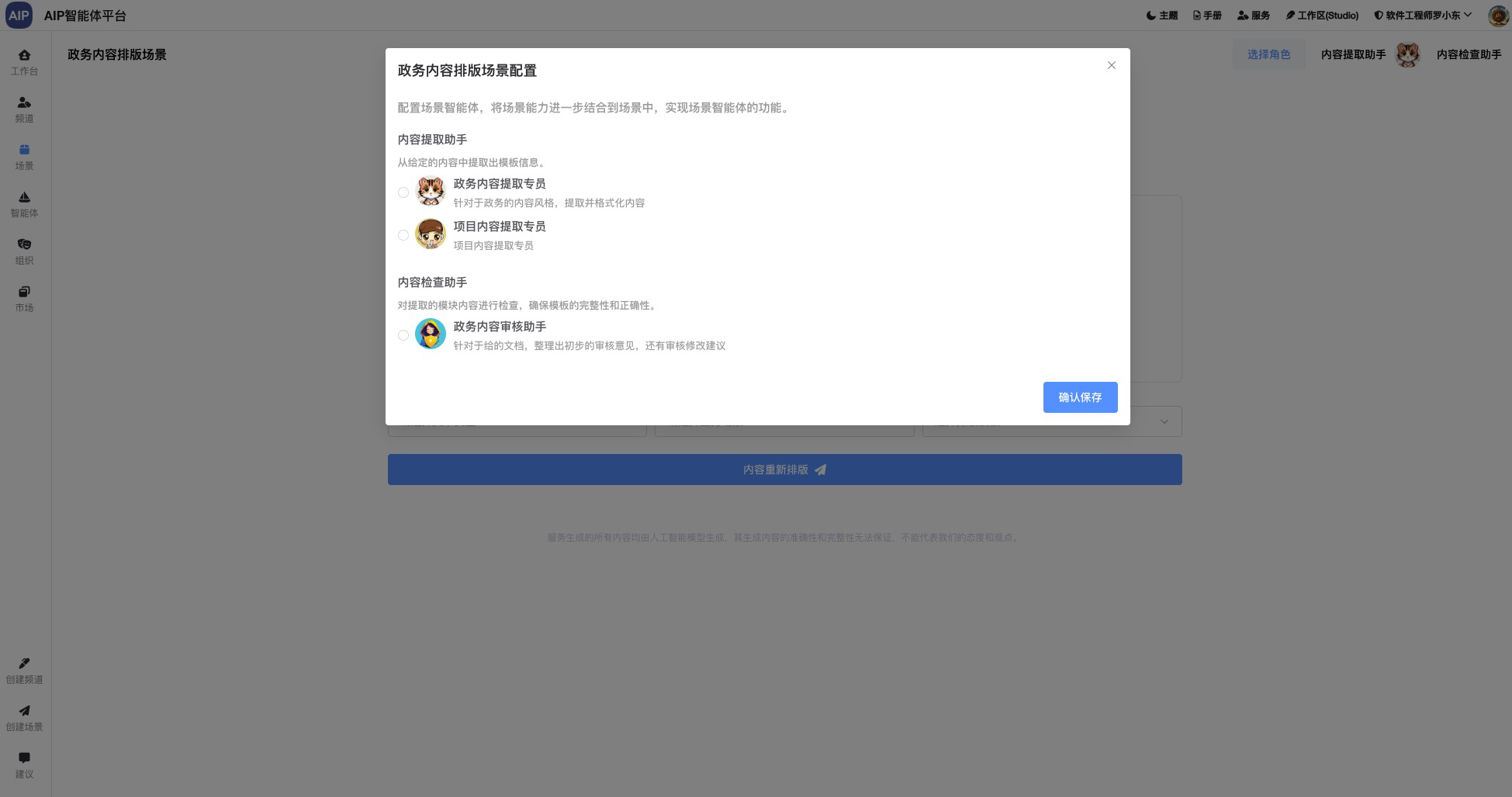
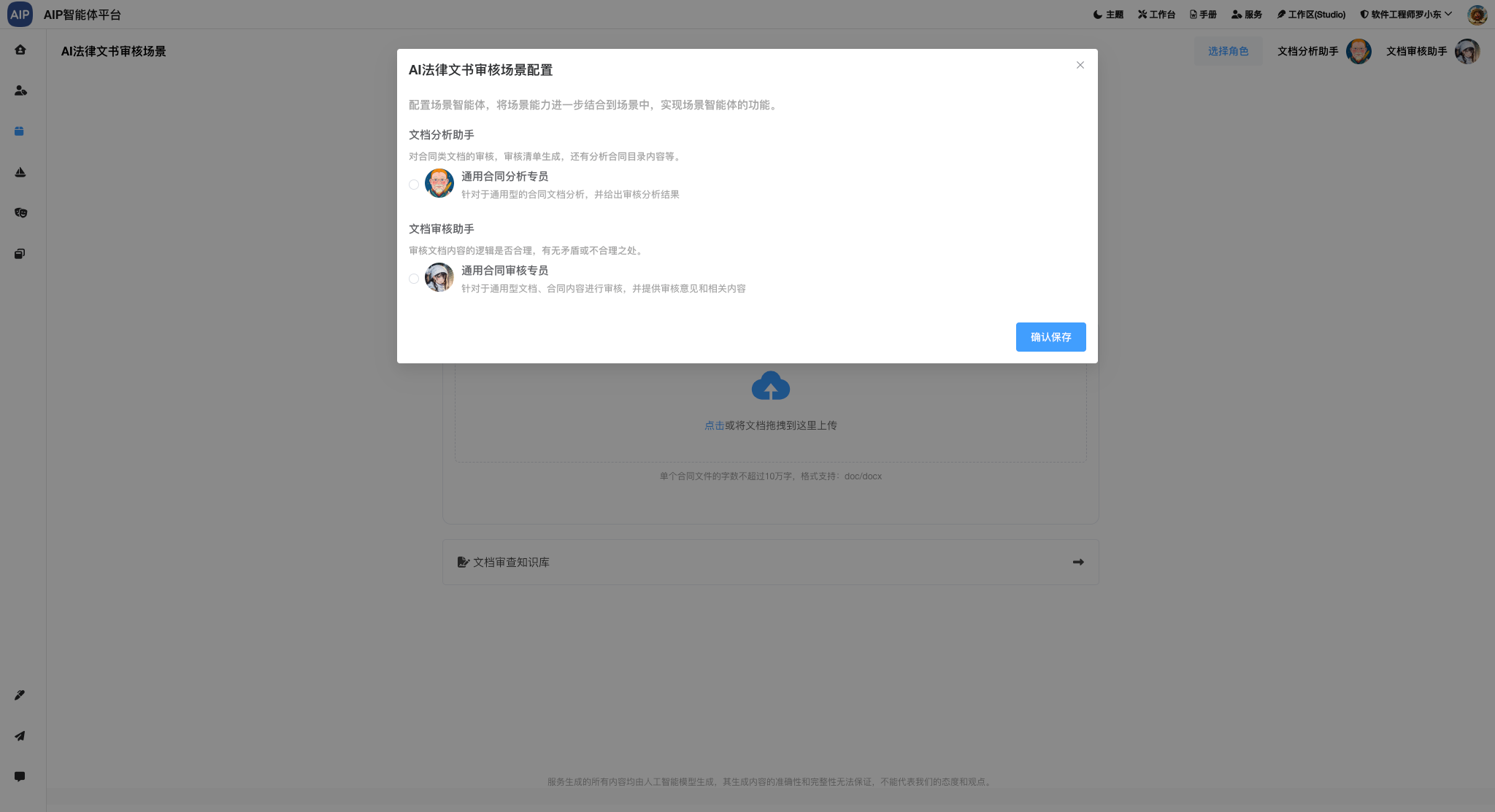
针对于不同的专家类型,不同的场景,会有不同的知识库,不同的工作,接入不同的场景,这些相对来说,纳米AI做得更为平民化,这里考虑到适配不同的场景,可以定义多种不同的DeepSearch智能体,以下是配置界面:
这个是针对于不同领域专家输出的结果。
通用智能体场景
总的来说,上面是还是单智能体的交互情况,配置起来的效果可能还会有一些场景局限,然后增加了自定义多智能体结合起来的场景,这里我们定义为通用智能体,做为输出结果,我们需要更为专业的智能体来做专业的事情。
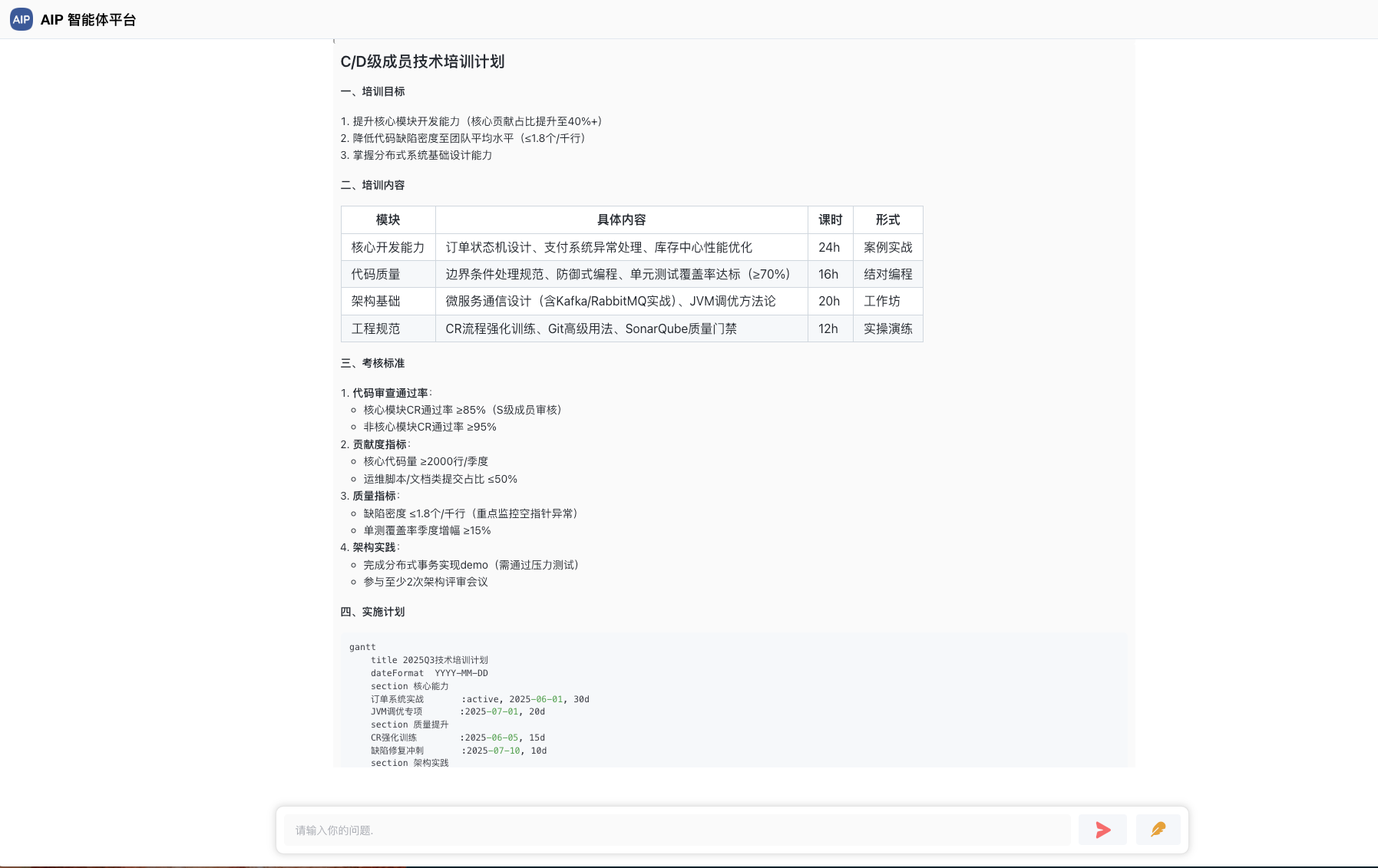
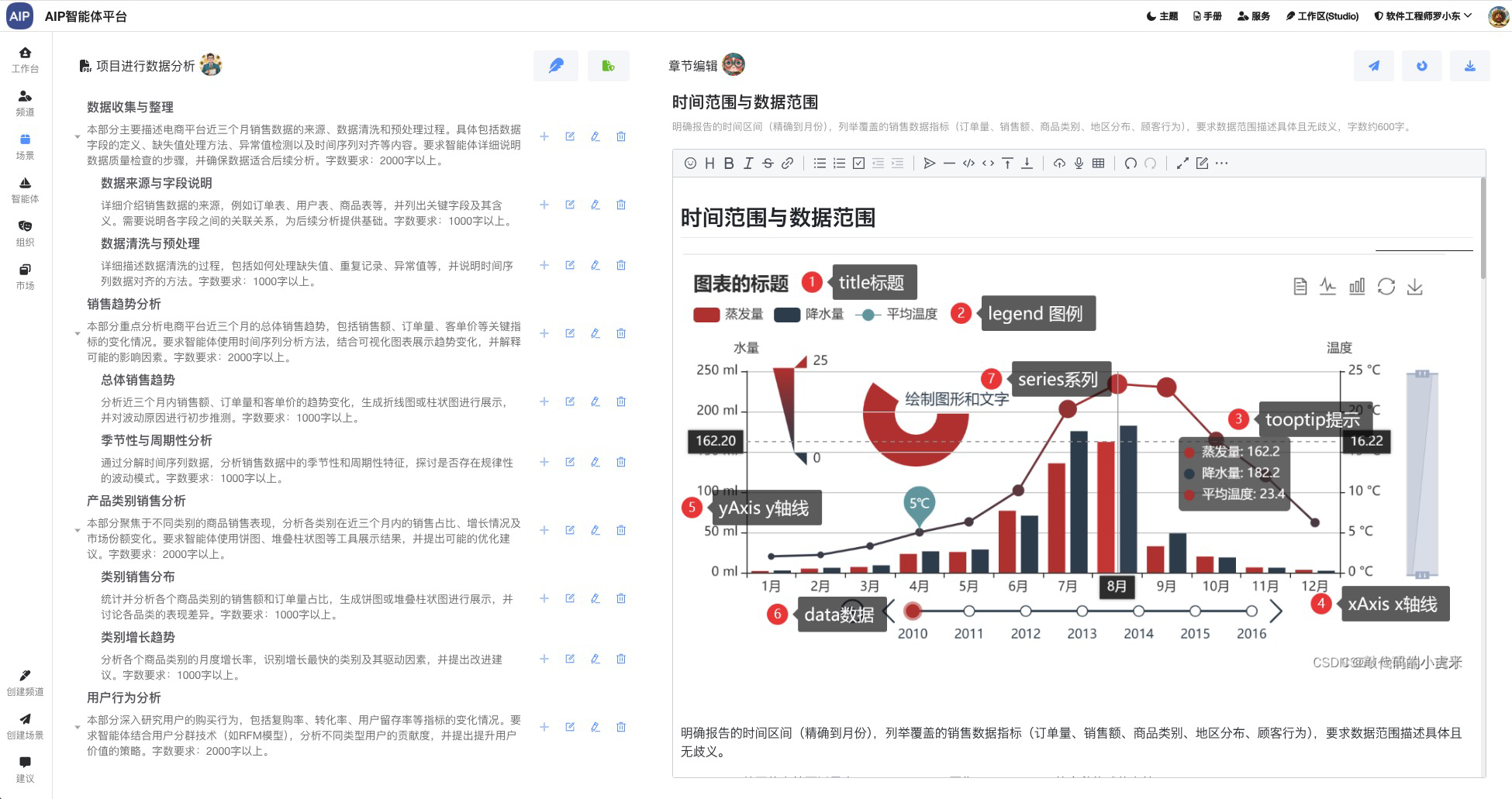
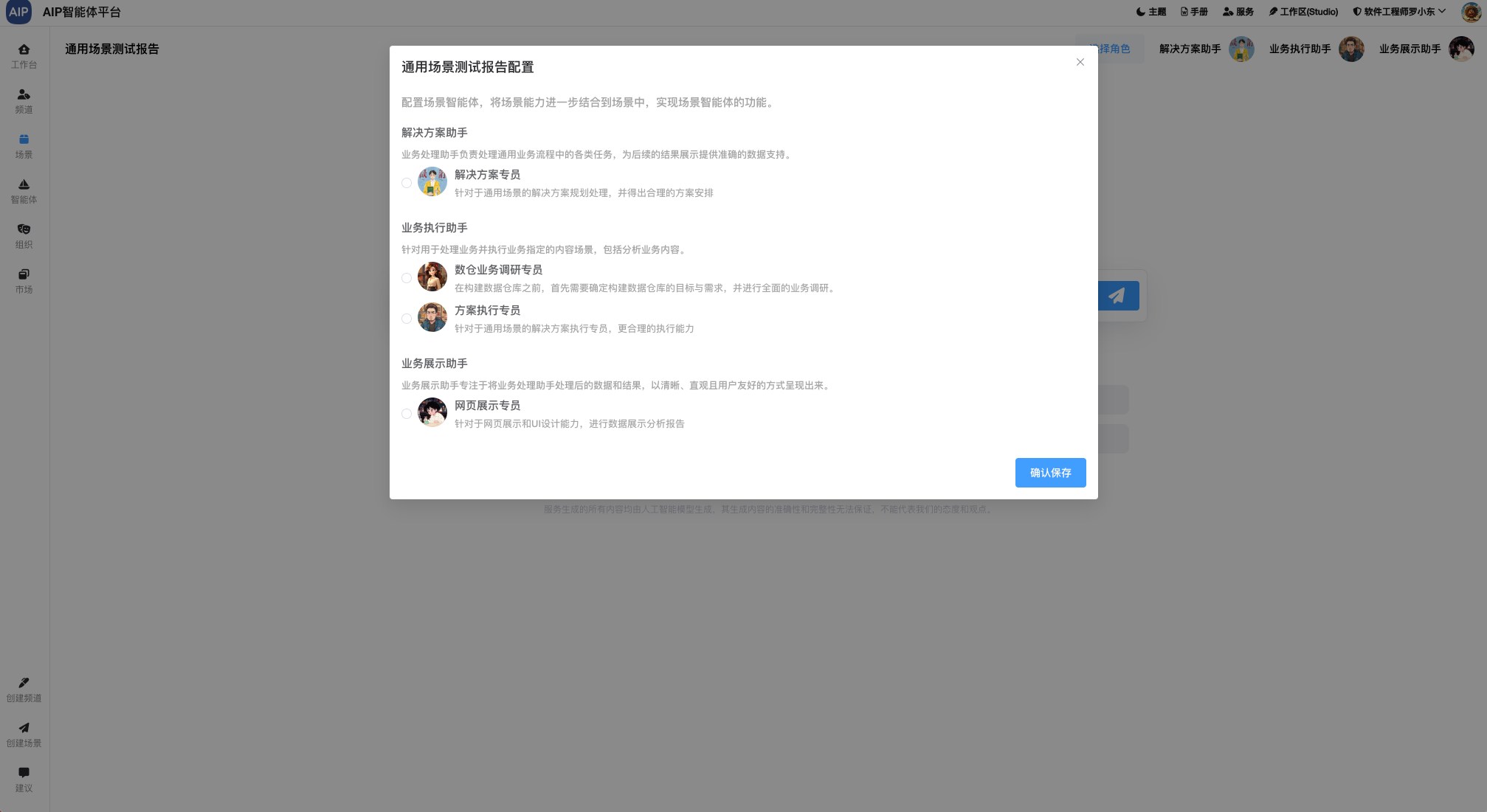
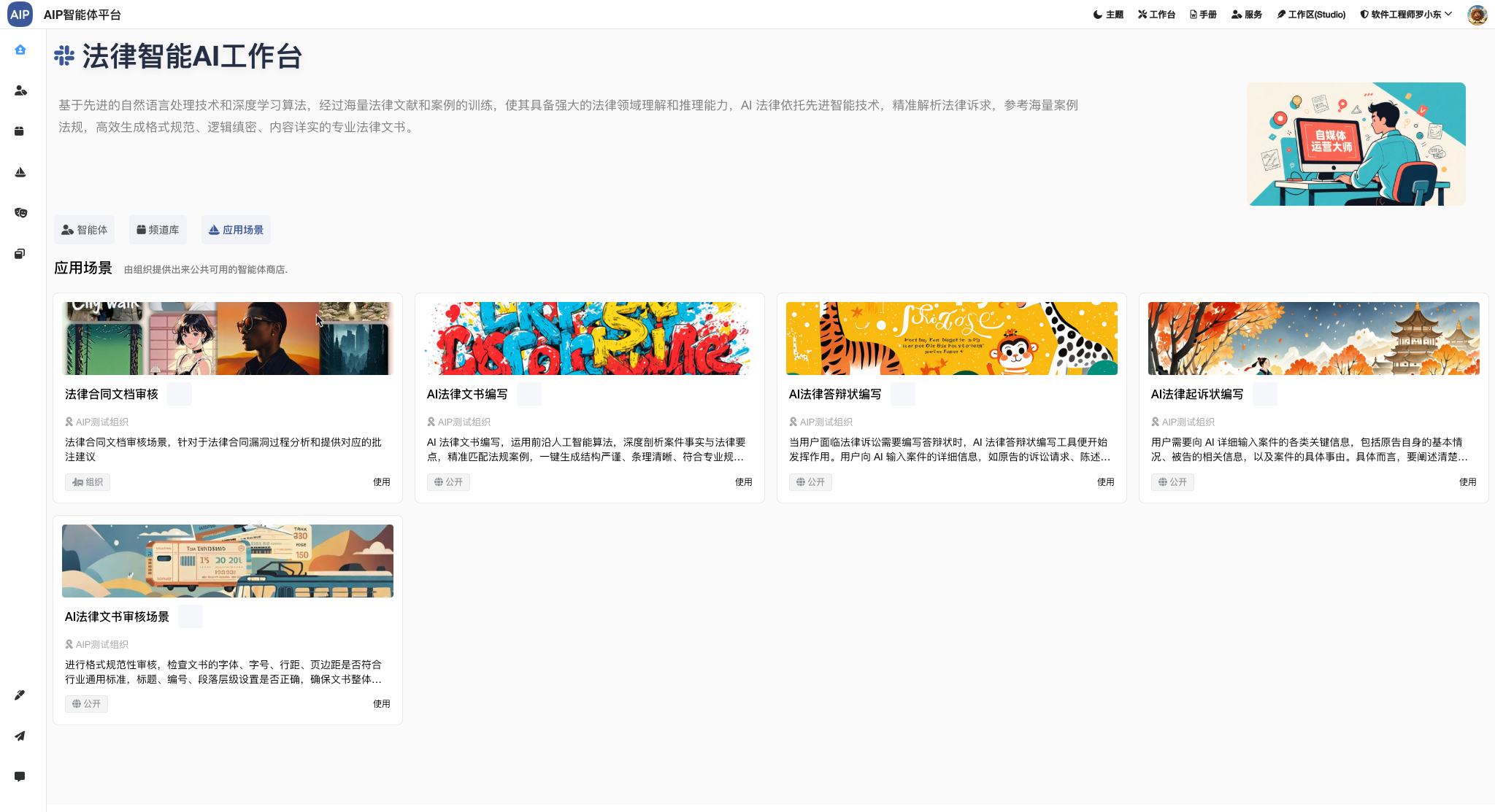
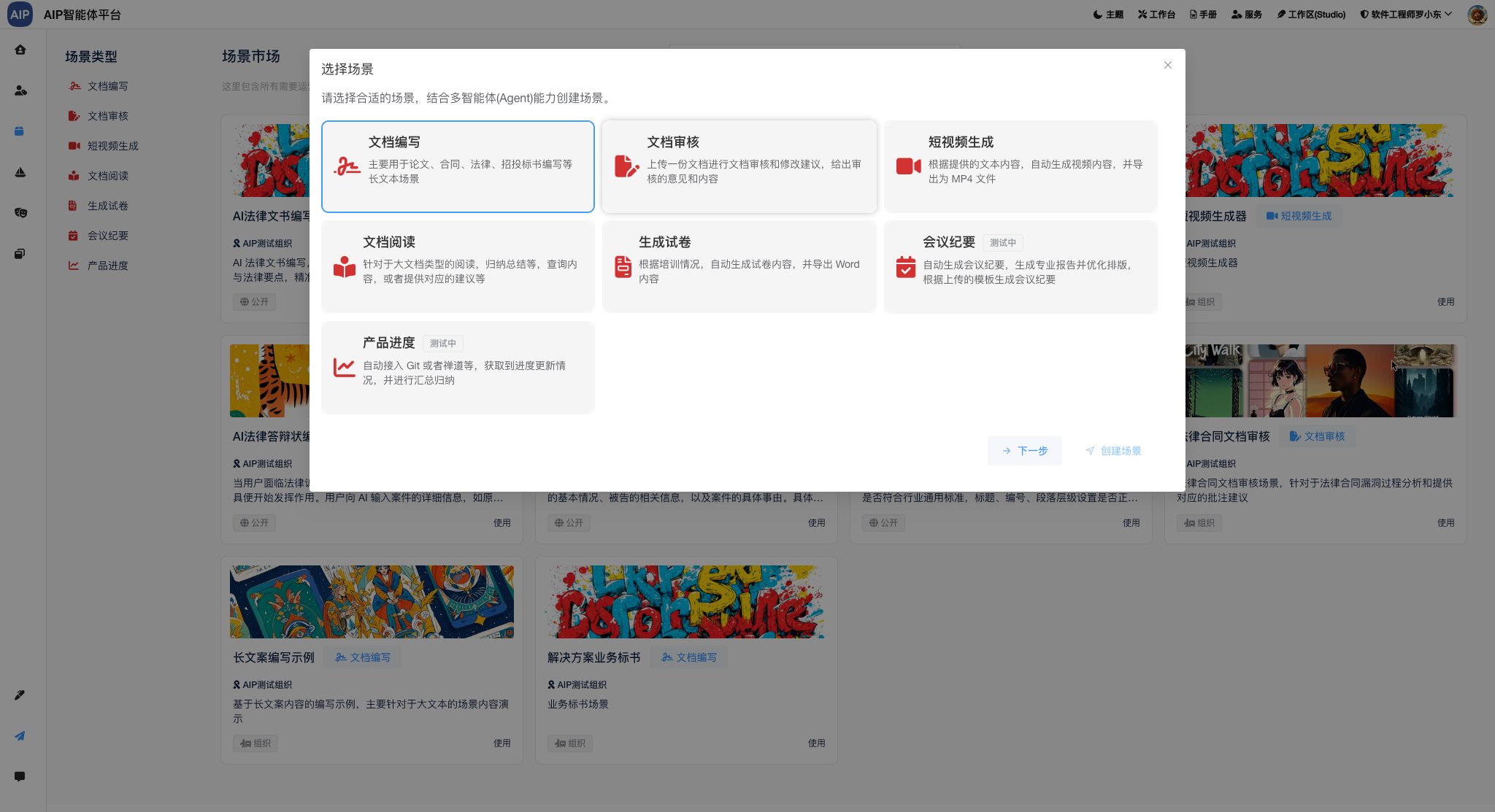
定义两个协同的智能体来配合完成一个事情,这里流程上我们配置引用不同的智能体来完成一个任务,下面是智能体的场景选择:
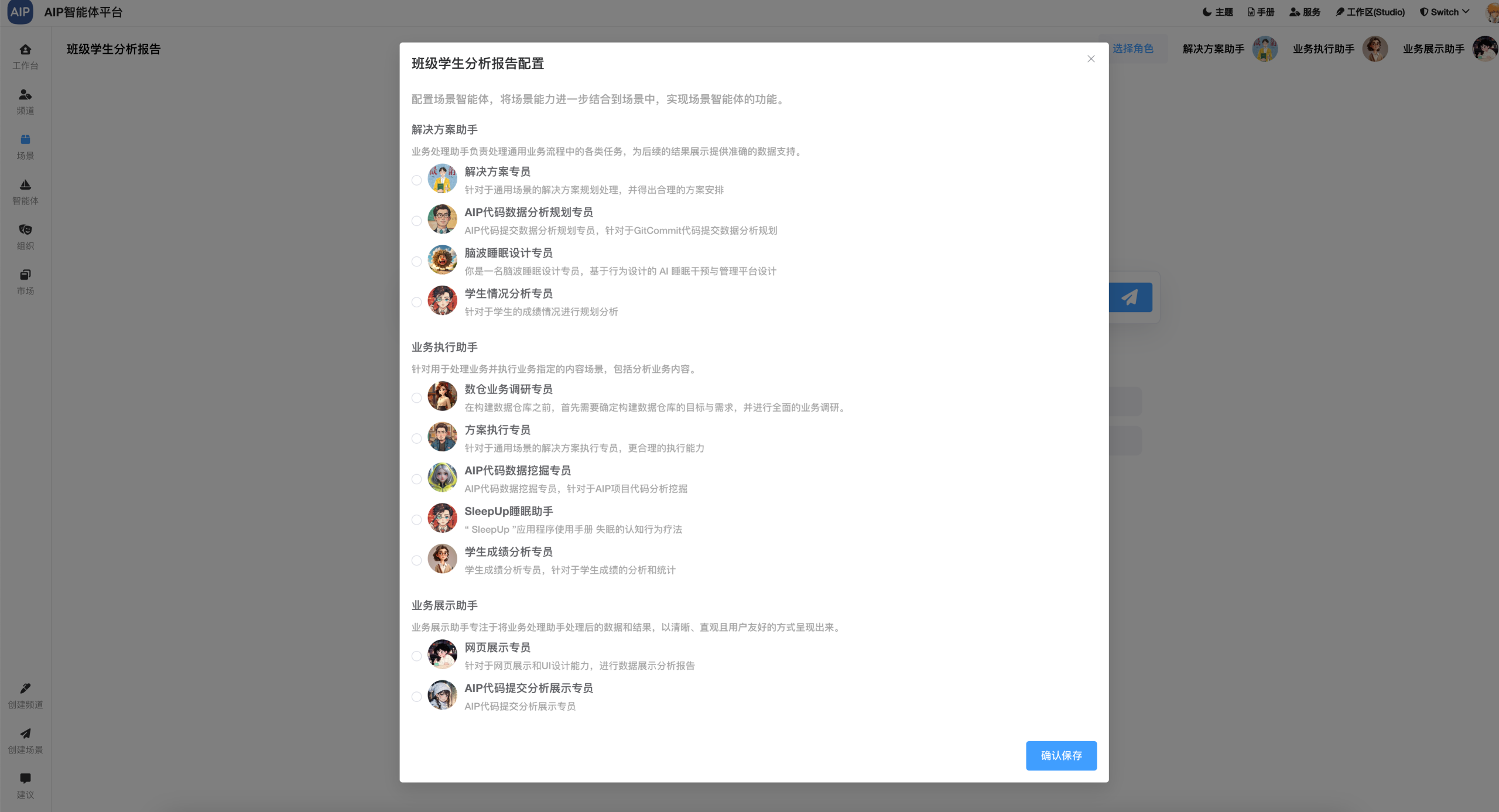
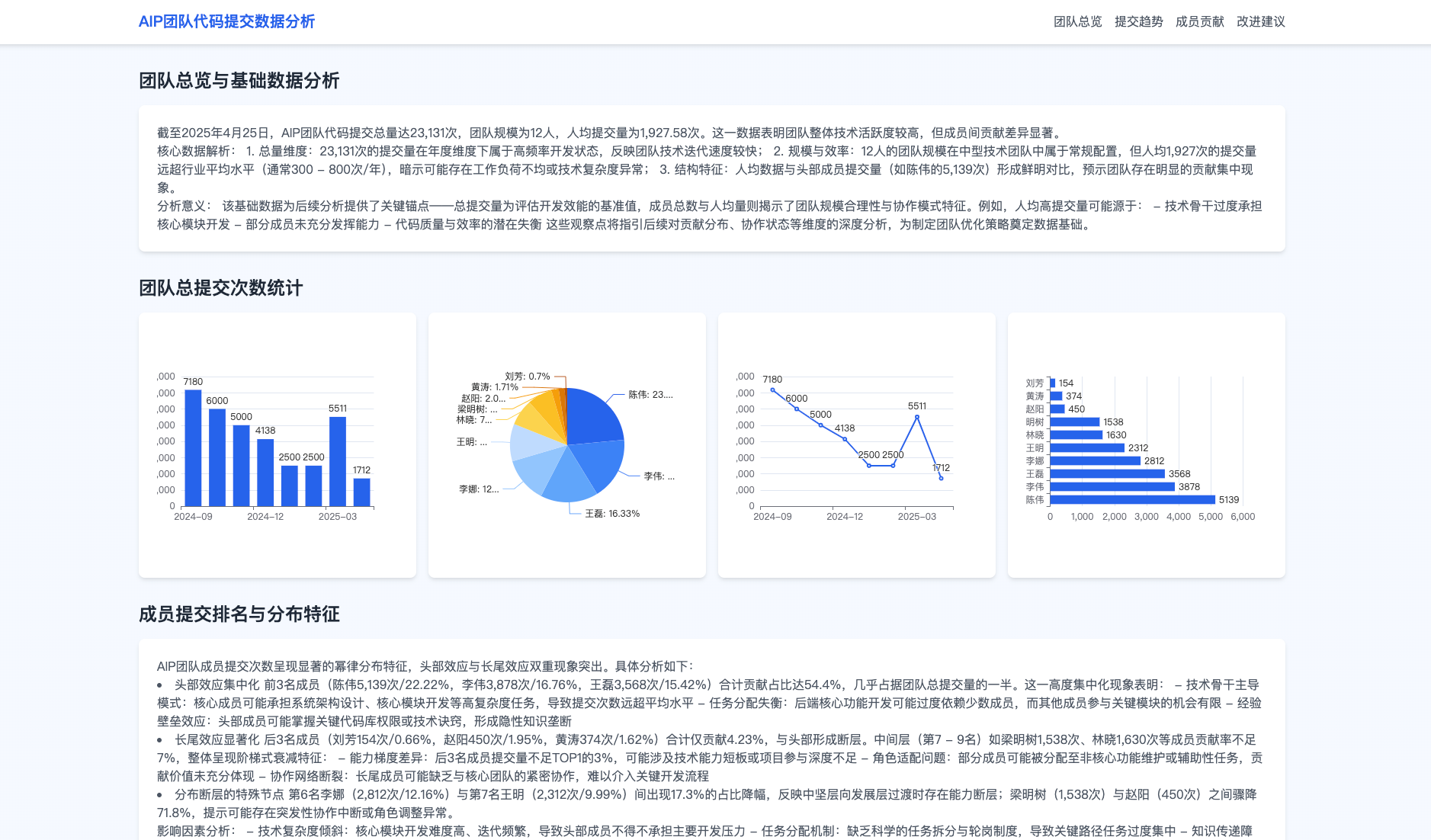
形成团队的能力来实现这个,更为灵活的控制每个环节实现这个目标,比如形成分析形结果输出,也以校园场景为示例:
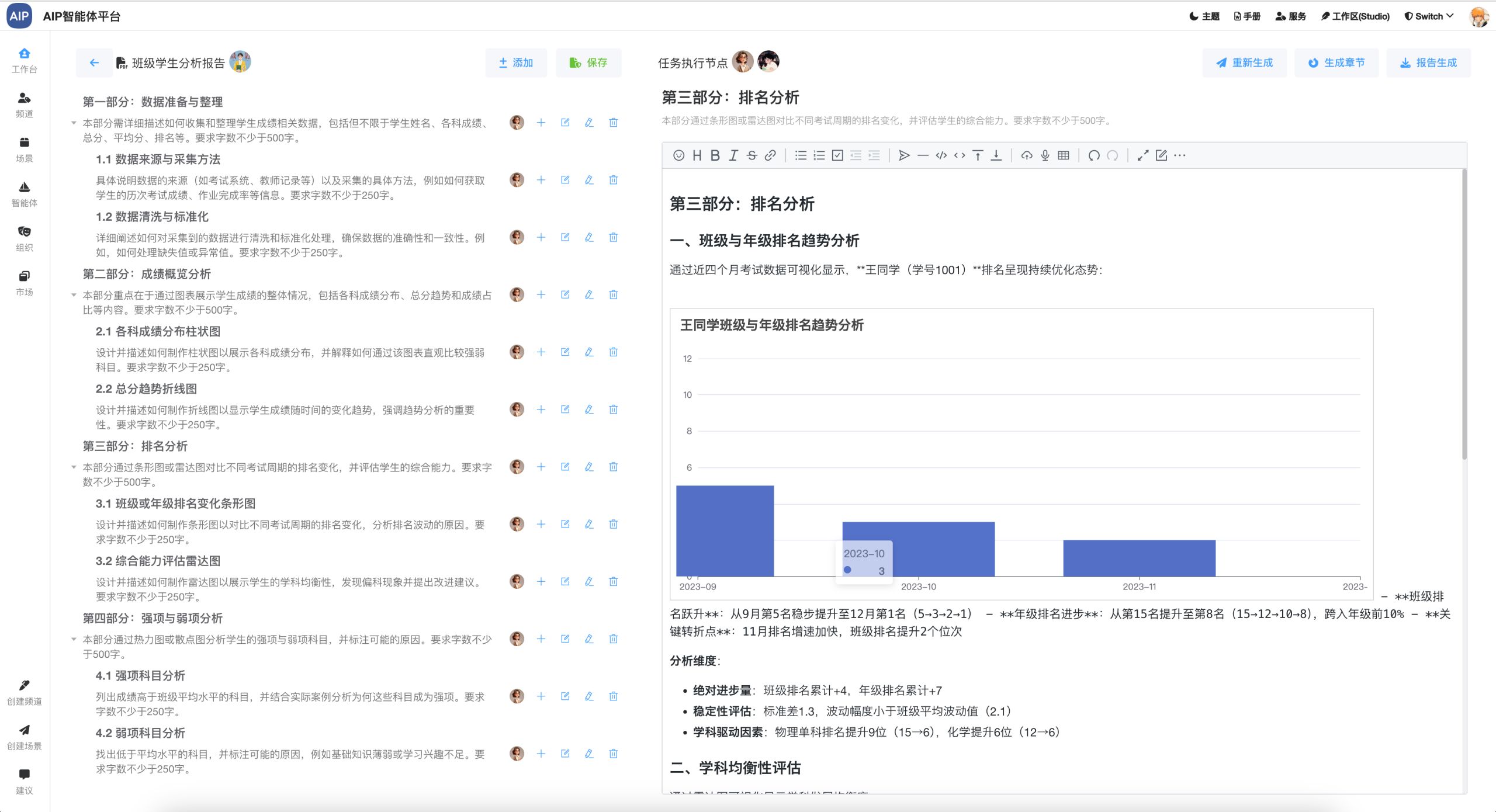
团队能力的补充会在某个任务安排上更专业,效果更为突出,通过每个角色的能力来完成他需要完成的事情。
总结
通过智能体与工具的深度协同,实现从单一问答到复杂任务处理的全面覆盖。单智能体问答提供基础交互能力,DeepSearch 深度检索深化专业领域应用,通用智能体场景则突破个体能力局限,构建高效协作体系。
在保留传统 AI 工作流的同时,方案强调多 Agent 配置的灵活性,满足不同用户、不同场景的差异化需求。未来,可进一步探索智能体间的动态协作机制,优化工具集成与数据交互效率,推动 AI 工作流向更智能、更高效的方向发展,为各行业提供更具价值的 AI 解决方案。
以上为Agentic 工作流上的一些探索,也期望有兴趣的同学可以互相交流。